

Distributed Systems often process and store huge amounts of data. Processing this data efficiently is typically an ongoing endeavor, and how it is designed almost always affects the end-user experience of a product.
Two popular modes of processing data are Batch Processing and Asynchronous Processing. We'll learn more about both in this article, along with when to use each approach.
Table of Contents
- What is Batch Processing?
- When Do We Use Batch Processing?
- Real World Example of Batch Processing of Data
- What Does Batch Processing Look Like in Code?
2. Asynchronous Processing of Data
- What is Asynchronous Processing?
- When Do We Use Asynchronous Processing
- Real World Example of Asynchronous Processing of Data
- What Does Async Processing Look Like in Code?
3. Summary
Batch Processing of Data
What is Batch Processing?
Batch Processing, as you may have guessed, waits for a certain amount of data to be accumulated, and then processes this batch of data in one go. In other words, this means that in most scenarios we would wait for some number of events to complete and then process the data.
This is different from asynchronous processing of data, where we process an event and its associated data as soon as it occurs. More on that soon.
Now that you know a bit more about batch processing, it'll be useful to see a couple of real world examples.
When Do We Use Batch Processing?
Batch processing is used in lots of scenarios, such as:
- Large volume of data: When we have a very large amount of data, it is often more resource-efficient to let the data collect over a period of time and then process it.
- Data that isn't time sensitive: Since batch processing waits for data to collect, it is generally not suitable for processing data that's very time sensitive. On the other hand, it is possible to process batches of data within short intervals of time.
- Scheduled Processing of data: In lots of instances, we need a large amount of data to be processed at regular intervals. Automated system backup and updates, for example, are generally scheduled for particular intervals. Batch processing can be very useful in such scenarios.
Real World Example of Batch Processing of Data
A popular real world use case for batch processing is credit card transactions.
Many financial institutions choose to settle credit card transactions in batches instead of settling them in real time. Since the settlement of transactions is generally not very time sensitive, this gives systems the time to run various other analyses / jobs on the transactions such as fraud detection, currency conversions etc.

The diagram above shows a very high level example of a lifecycle of a credit card transaction. The steps are as follows:
- The credit card transaction takes place at the Point of Sale (POS).
- A gateway forwards the request to a serverless component that writes the transaction to a staging database where the transaction is stored temporarily.
- At the end of the business day, the transactions in the staging database are reconciled and go through fraud detection. This is the component where batch processing takes place (note that we waited for some data to collect, and processed a large amount of data).
What Does Batch Processing Look Like in Code?
We saw an example of a distributed system in the above example. How would batch processing look like in code?
Below you'll see some code that lets you process a batch of SQS messages:
import boto3
def process_batch_messages(sqs, queue_url):
partial_response = sqs.receive_message(
QueueUrl=queue_url
MaxNumberOfMessages=10 # This sets the maximum batch size to 10
WaitTimeSeconds=10 # We wait for a maximum of 10 seconds
)
if 'Messages' in partial_response:
messages = partial_response['Messages']
for each message in messages:
# do something with each message
# remove the message from the queue after processing
sqs.delete_message(QueueUrl=queue_url, ReceiptHandle=message['ReceiptHandle'])
if __name__ == '__main__':
# Initialize sqs client
sqs = boto3.client(
'sqs',
aws_access_key_id='Your access key id',
aws_secret_access_key='your secret access key,
region_name='Your AWS region'
)
your_queue_url = 'your-queue-url'
process_batch_messages(sqs, your_queue_url)
The above code waits for the earlier of two events: either 10 seconds having passed, or a batch size of 10 being reached within the queue.
Asynchronous Processing of Data
What is Asynchronous Processing?
The word asynchronous is generally defined as "events that are not coordinated in time". As the definition suggests, asynchronous processing of data does not rely on coordination of data events, and these events are processed as and when they occur.
This means that as soon as an event occurs, the event is processed and the data corresponding to the event may be stored in a sub system, passed on to another component in the system, or may simply lead to another event being fired off.
When Do We Use Asynchronous Processing?
You'll use asynchronous processing of data (sometimes also referred to as async) in various scenarios.
- Microservices: Microservices often involve a request that needs an immediate response. Since this processing is done "per event", this would require async processing of data, so in most cases results are returned to clients within a very short period of time (low latency).
- User Interfaces: Often, components in user facing UI components need to use async processing of data. For instance, multiple data fetches can be performed in the background using async calls when a user is using an application. This ensures that the application works smoothly and responsively without having the need for the UI components to "freeze".
- Systems that require real time responses: Many interactive systems require real time processing of data. In the past few years, video calls and meetings have become increasingly popular. Since systems like these require immediate requests and responses (and in some cases streams of data being processed), async processing of data is used here.
Real World Example of Asynchronous Processing of Data
Chat apps are a great example of asynchronous processing of data. Here, if a user 1 types a message and sends it to user 2, the message must be written to the required databases / systems, delivered to user 2, and possibly read by user 2 without any delay.
Since this is real time processing of the event that occurred here (the event being that a message was sent), this is an example of asynchronous processing of data.
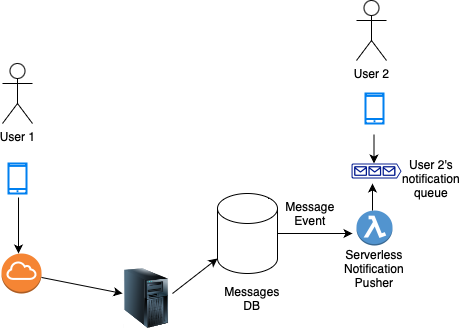
In the above diagram we see that User 1 sends a message through their phone. The message gets routed to a message server which ultimately creates an entry in a messages database (Messages DB).
Now that MessagesDB has an entry, an event is fired off that is consumed by the Notification Pusher. This then communicates with User 2's notification queue to put a notification related to the message in their notification queue.
Whenever User 2's device comes online or has access to the internet, they receive a message notification.
Note that we did not wait for any data to collect, nor did we process this data after any specific time delay. We processed the event as soon as it happened. So this is an example of asynchronous processing of data.
What Does Async Processing Look Like in Code?
Can we modify the code that we saw in the section for batch processing to work for async processing? Remember that we said "this code waits for the earlier of two events: 10 seconds having passed, or a batch size of 10 being reached within the queue".
If we change the batch size to 1, we would effectively process a message as soon as it is received.
import boto3
def process_async_messages(sqs, queue_url, batch_size):
partial_response = sqs.receive_message(
QueueUrl=queue_url
MaxNumberOfMessages=batch_size # This sets the maximum batch size
WaitTimeSeconds=10 # We wait for a maximum of 10 seconds
)
if 'Messages' in partial_response:
messages = partial_response['Messages']
for each message in messages:
# do something with each message
# remove the message from the queue after processing
sqs.delete_message(QueueUrl=queue_url, ReceiptHandle=message['ReceiptHandle'])
if __name__ == '__main__':
# Initialize sqs client
sqs = boto3.client(
'sqs',
aws_access_key_id='Your access key id',
aws_secret_access_key='your secret access key,
region_name='Your AWS region'
)
your_queue_url = 'your-queue-url'
process_batch_messages(sqs, your_queue_url, 1)
Note that in the above code we modified the process_batch_messages to accept a batch_size parameter and renamed the method to process_async_messages. This method processes a message as soon as the queue receives a method (assuming the queue has received a message within the wait time of 10 seconds)
Summary
Let's summarize batch and asynchronous data processing.
Batch Processing is a paradigm where you wait for an amount of data to collect or some time to pass before the data is processed.
Batch processing is often used in scenarios where you have large volumes of data, data that isn't time sensitive, and data that can be processed on a set schedule. The example we discussed above was that of a credit card transaction.
Asynchronous processing of data, on the other hand, is used to process data related to events as soon as they occur.
This approach is often used when dealing with data processed in microservices, user interfaces, and in general with systems needing real time request-response processing. We looked at an example of a chat app in the above discussion and learnt how asynchronous processing of data is applicable to the scenario.