

Imagine you are a product owner who wants to know what people are saying about your product in social media. Maybe your company launched a new product and you want to know how people reacted to it. You might want to use a sentiment analyzer like MonkeyLearn or Talkwalker. But wouldn’t it be cool if we could make our own sentiment analyzer? Let’s make it then!
In this tutorial, we are going to make a Telegram Bot that will do the sentiment analysis of tweets related to the keyword that we define.
If this is your first time building a Telegram Bot, you might want to read this post first.
Getting started
1. Install the libraries
We are going to use tweepy to gather the tweet data. We will use nltk to help us clean the tweets. Google Natural Language API will do the sentiment analysis. python-telegram-bot will send the result through Telegram chat.
pip3 install tweepy nltk google-cloud-language python-telegram-bot2. Get Twitter API Keys
To be able to gather the tweets from Twitter, we need to create a developer account to get the Twitter API Keys first.
Go to Twitter Developer website, and create an account if you don’t have one.
Open Apps page, click “Create an app”, fill out the form and click “Create”.
Click on “Keys and tokens” tab, copy the API Key and API Secret Key in the “Consumer API keys” section.
Click the “Create” button under “Access token & access token secret” section. Copy the Access Token and Access Token Secret that have been generated.

Great! Now you should have four keys — API Key, API Secret Key, Access Token, and Access Token Secret. Save those keys for later use.
3. Enable Google Natural Language API
We need to enable the Google Natural Language API first if we want to use the service.
Go to Google Developers Console and create a new project (or select the one you have).
In the project dashboard, click “ENABLE APIS AND SERVICES”, and search for Cloud Natural Language API.
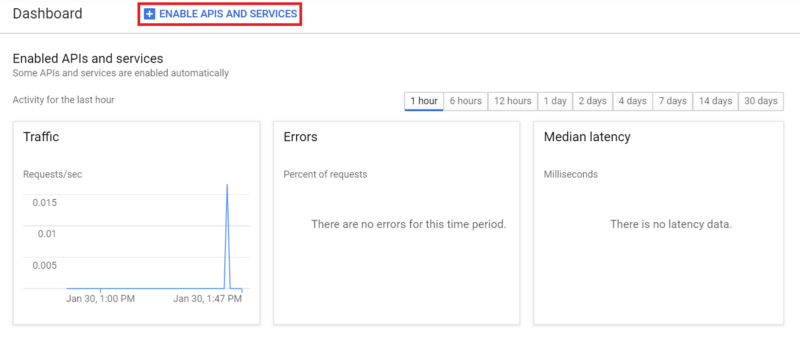
Click “ENABLE” to enable the API.
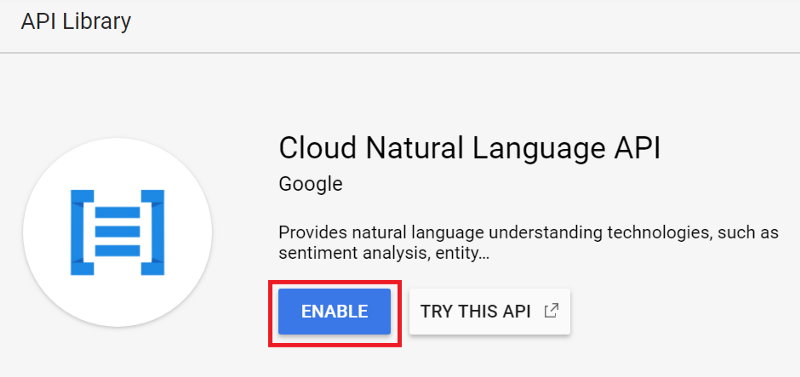
4. Create service account key
If we want to use Google Cloud services like Google Natural Language, we need a service account key. This is like our credential to use Google’s services.
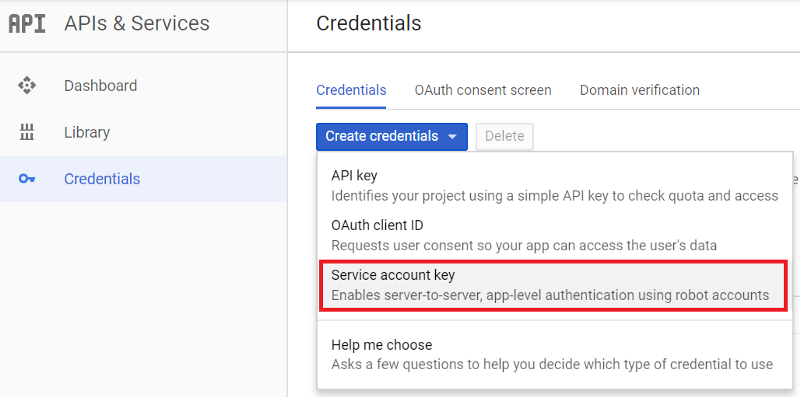
Go to Google Developers Console, click “Credentials” tab, choose “Create credentials” and click “Service account key”.
Choose “App Engine default service account” and JSON as key type, then click “Create”.
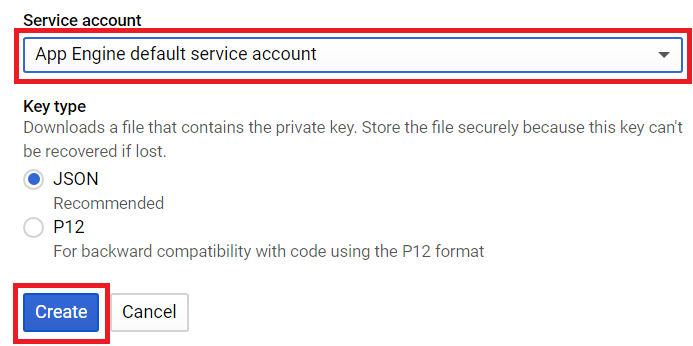
There is a .json file that will be automatically downloaded, name it creds.json.
Set the GOOGLE_APPLICATION_CREDENTIALS with the path of our creds.json file in the terminal.
export GOOGLE_APPLICATION_CREDENTIALS='[PATH_TO_CREDS.JSON]'If everything is good, then it’s time to write our program.
Write the program
This program will gather all the tweets containing the defined keyword in the last 24 hours with a maximum of 50 tweets. Then it will analyze the tweets’ sentiments one by one. We will send the result (average sentiment score) through Telegram chat.
This is a simple workflow of our program.
connect to the Twitter API -> search tweets based on the keyword -> clean all of the tweets -> get tweet’s sentiment score -> send the result
Let’s make a single function to define each flow.
1. Connect to the Twitter API
The first thing that we need to do is gather the tweets’ data, so we have to connect to the Twitter API first.
Import the tweepy library.
import tweepyDefine the keys that we generated earlier.
ACC_TOKEN = 'YOUR_ACCESS_TOKEN'
ACC_SECRET = 'YOUR_ACCESS_TOKEN_SECRET'
CONS_KEY = 'YOUR_CONSUMER_API_KEY'
CONS_SECRET = 'YOUR_CONSUMER_API_SECRET_KEY'Make a function called authentication to connect to the API, with four parameters which are all of the keys.
def authentication(cons_key, cons_secret, acc_token, acc_secret):
auth = tweepy.OAuthHandler(cons_key, cons_secret)
auth.set_access_token(acc_token, acc_secret)
api = tweepy.API(auth)
return api2. Search the tweets
We can search the tweets with two criteria, based on time or quantity. If it’s based on time, we define the time interval and if it’s based on quantity, we define the total tweets that we want to gather. Since we want to gather the tweets from the last 24 hours with maximum tweets of 50, we will use both of the criteria.
Since we want to gather the tweets from the last 24 hours, let's take yesterday’s date as our time parameter.
from datetime import datetime, timedelta
today_datetime = datetime.today().now()
yesterday_datetime = today_datetime - timedelta(days=1)
today_date = today_datetime.strftime('%Y-%m-%d')
yesterday_date = yesterday_datetime.strftime('%Y-%m-%d')Connect to the Twitter API using a function we defined before.
api = authentication(CONS_KEY,CONS_SECRET,ACC_TOKEN,ACC_SECRET)Define our search parameters. q is where we define our keyword, since is the start date for our search, result_type='recent' means we are going to take the newest tweets, lang='en' is going to take the English tweets only, and items(total_tweets) is where we define the maximum tweets that we are going to take.
search_result = tweepy.Cursor(api.search,
q=keyword,
since=yesterday_date,
result_type='recent',
lang='en').items(total_tweets)Wrap those codes in a function called search_tweets with keyword and total_tweets as the parameters.
def search_tweets(keyword, total_tweets):
today_datetime = datetime.today().now()
yesterday_datetime = today_datetime - timedelta(days=1)
today_date = today_datetime.strftime('%Y-%m-%d')
yesterday_date = yesterday_datetime.strftime('%Y-%m-%d')
api = authentication(CONS_KEY,CONS_SECRET,ACC_TOKEN,ACC_SECRET)
search_result = tweepy.Cursor(api.search,
q=keyword,
since=yesterday_date,
result_type='recent',
lang='en').items(total_tweets)
return search_result3. Clean the tweets
Before we analyze the tweets sentiment, we need to clean the tweets a little bit so the Google Natural Language API can identify them better.
We will use the nltk and regex libraries to help us in this process.
import re
from nltk.tokenize import WordPunctTokenizerWe remove the username in every tweet, so basically we can remove everything that begins with @ and we use regex to do it.
user_removed = re.sub(r'@[A-Za-z0-9]+','',tweet.decode('utf-8'))We also remove links in every tweet.
link_removed = re.sub('https?://[A-Za-z0-9./]+','',user_removed)Numbers are also deleted from all of the tweets.
number_removed = re.sub('[^a-zA-Z]',' ',link_removed)The last, convert all of the characters into lower space, then remove every unnecessary space.
lower_case_tweet = number_removed.lower()
tok = WordPunctTokenizer()
words = tok.tokenize(lower_case_tweet)
clean_tweet = (' '.join(words)).strip()Wrap those codes into a function called clean_tweets with tweet as our parameter.
def clean_tweets(tweet):
user_removed = re.sub(r'@[A-Za-z0-9]+','',tweet.decode('utf-8'))
link_removed = re.sub('https?://[A-Za-z0-9./]+','',user_removed)
number_removed = re.sub('[^a-zA-Z]', ' ', link_removed)
lower_case_tweet= number_removed.lower()
tok = WordPunctTokenizer()
words = tok.tokenize(lower_case_tweet)
clean_tweet = (' '.join(words)).strip()
return clean_tweet4. Get tweet’s sentiment
To be able to get a tweet’s sentiment, we will use Google Natural Language API.
The API provides Sentiment Analysis, Entities Analysis, and Syntax Analysis. We will only use the Sentiment Analysis for this tutorial.
In Google’s Sentiment Analysis, there are score and magnitude. Score is the score of the sentiment ranges from -1.0 (very negative) to 1.0 (very positive). Magnitude is the strength of sentiment and ranges from 0 to infinity.
For the sake of simplicity of this tutorial, we will only consider the score. If you are thinking of doing deep NLP analysis, you should consider the magnitude too.
Import the Google Natural Language library.
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import typesMake a function called get_sentiment_score which takes tweet as the parameter, and returns the sentiment score.
def get_sentiment_score(tweet):
client = language.LanguageServiceClient()
document = types\
.Document(content=tweet,
type=enums.Document.Type.PLAIN_TEXT)
sentiment_score = client\
.analyze_sentiment(document=document)\
.document_sentiment\
.score
return sentiment_score5. Analyze the tweets
Let’s make a function that will loop the list of tweets we get from search_tweets function and get the sentiment’s score of every tweet using get_sentiment_score function. Then we’ll calculate the average. The average score will determine whether the given keyword has a positive, neutral, or negative sentiment.
Define score equals to 0 , then use search_tweets function to get the tweets related to the keyword that we define.
score = 0
tweets = search_tweets(keyword, total_tweets)Loop through the list of tweets, and do the cleaning using clean_tweets function that we created before.
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))Get the sentiment score using get_sentiment_score function, and increment the score by adding sentiment_score.
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_scoreLet’s print out each tweet and its sentiment so we can see the progress detail in the terminal.
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_score
print('Tweet: {}'.format(cleaned_tweet))
print('Score: {}\n'.format(sentiment_score))Calculate the average score and pass it to final_score variable. Wrap all of the codes into analyze_tweets function, with keyword and total_tweets as the parameters.
def analyze_tweets(keyword, total_tweets):
score = 0
tweets = search_tweets(keyword, total_tweets)
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_score
print('Tweet: {}'.format(cleaned_tweet))
print('Score: {}\n'.format(sentiment_score))
final_score = round((score / float(total_tweets)),2)
return final_score6. Send the tweet’s sentiment score
Let’s make the last function in the workflow. This function will takes user’s keyword and calculate the average sentiment’s score. Then we’ll send it through Telegram Bot.
Get the keyword from the user.
keyword = update.message.textUse analyze_tweets function to get the final score, keyword as our parameter, and set the total_tweets = 50 since we want to gather 50 tweets.
final_score = analyze_tweets(keyword, 50)We define whether a given score is considered negative, neutral, or positive using Google’s score range, as we see in the image below.

if final_score <= -0.25:
status = 'NEGATIVE ❌'
elif final_score <= 0.25:
status = 'NEUTRAL ?'
else:
status = 'POSITIVE ✅'Lastly, send the final_score and the status through Telegram Bot.
bot.send_message(chat_id=update.message.chat_id,
text='Average score for '
+ str(keyword)
+ ' is '
+ str(final_score)
+ ' '
+ status)Wrap the codes into a function called send_the_result.
def send_the_result(bot, update):
keyword = update.message.text
final_score = analyze_tweets(keyword, 50)
if final_score <= -0.25:
status = 'NEGATIVE ❌'
elif final_score <= 0.25:
status = 'NEUTRAL ?'
else:
status = 'POSITIVE ✅'
bot.send_message(chat_id=update.message.chat_id,
text='Average score for '
+ str(keyword)
+ ' is '
+ str(final_score)
+ ' '
+ status)7. Main program
Lastly, create another function called main to run our program. Don’t forget to change YOUR_TOKEN to your bot’s token.
from telegram.ext import Updater, MessageHandler, Filters
def main():
updater = Updater('YOUR_TOKEN')
dp = updater.dispatcher
dp.add_handler(MessageHandler(Filters.text, send_the_result))
updater.start_polling()
updater.idle()
if __name__ == '__main__':
main()In the end, your code should look like this
import tweepy
import re
from telegram.ext import Updater, MessageHandler, Filters
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import types
from datetime import datetime, timedelta
from nltk.tokenize import WordPunctTokenizer
ACC_TOKEN = 'YOUR_ACCESS_TOKEN'
ACC_SECRET = 'YOUR_ACCESS_TOKEN_SECRET'
CONS_KEY = 'YOUR_CONSUMER_API_KEY'
CONS_SECRET = 'YOUR_CONSUMER_API_SECRET_KEY'
def authentication(cons_key, cons_secret, acc_token, acc_secret):
auth = tweepy.OAuthHandler(cons_key, cons_secret)
auth.set_access_token(acc_token, acc_secret)
api = tweepy.API(auth)
return api
def search_tweets(keyword, total_tweets):
today_datetime = datetime.today().now()
yesterday_datetime = today_datetime - timedelta(days=1)
today_date = today_datetime.strftime('%Y-%m-%d')
yesterday_date = yesterday_datetime.strftime('%Y-%m-%d')
api = authentication(CONS_KEY,CONS_SECRET,ACC_TOKEN,ACC_SECRET)
search_result = tweepy.Cursor(api.search,
q=keyword,
since=yesterday_date,
result_type='recent',
lang='en').items(total_tweets)
return search_result
def clean_tweets(tweet):
user_removed = re.sub(r'@[A-Za-z0-9]+','',tweet.decode('utf-8'))
link_removed = re.sub('https?://[A-Za-z0-9./]+','',user_removed)
number_removed = re.sub('[^a-zA-Z]', ' ', link_removed)
lower_case_tweet= number_removed.lower()
tok = WordPunctTokenizer()
words = tok.tokenize(lower_case_tweet)
clean_tweet = (' '.join(words)).strip()
return clean_tweet
def get_sentiment_score(tweet):
client = language.LanguageServiceClient()
document = types\
.Document(content=tweet,
type=enums.Document.Type.PLAIN_TEXT)
sentiment_score = client\
.analyze_sentiment(document=document)\
.document_sentiment\
.score
return sentiment_score
def analyze_tweets(keyword, total_tweets):
score = 0
tweets = search_tweets(keyword,total_tweets)
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_score
print('Tweet: {}'.format(cleaned_tweet))
print('Score: {}\n'.format(sentiment_score))
final_score = round((score / float(total_tweets)),2)
return final_score
def send_the_result(bot, update):
keyword = update.message.text
final_score = analyze_tweets(keyword, 50)
if final_score <= -0.25:
status = 'NEGATIVE ❌'
elif final_score <= 0.25:
status = 'NEUTRAL ?'
else:
status = 'POSITIVE ✅'
bot.send_message(chat_id=update.message.chat_id,
text='Average score for '
+ str(keyword)
+ ' is '
+ str(final_score)
+ ' '
+ status)
def main():
updater = Updater('YOUR_TOKEN')
dp = updater.dispatcher
dp.add_handler(MessageHandler(Filters.text, send_the_result))
updater.start_polling()
updater.idle()
if __name__ == '__main__':
main()Save the file and name it main.py, then run the program.
python3 main.pyGo to your telegram bot by accessing this URL: https://telegram.me/YOUR_BOT_USERNAME. Type any product, person name, or whatever you want and send it to your bot. If everything runs, there should be a detailed sentiment score for each tweet in the terminal. The bot will reply with the average sentiment score.
The pictures below are an example if I type valentino rossi and send it to the bot.

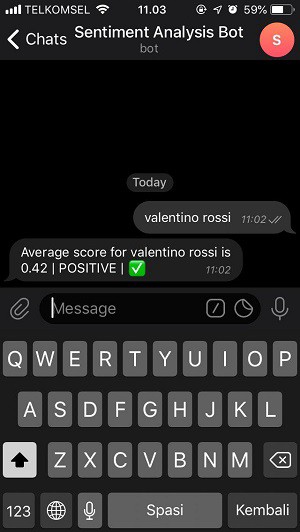
If you managed to follow the steps until the end of this tutorial, that’s awesome! You have your sentiment analyzer now, how cool is that!?
You can also check out my GitHub to get the code. Please do not hesitate to connect and leave a message in my Linkedin profile if you want to ask about anything.
Please leave a comment if you think there are any errors in my code or writing.
Thank you and good luck! :)