

Retrieval-Augmented Generation (RAG) can be extremely helpful when developing projects with Large Language Models. It combines the power of retrieval systems with advanced natural language generation, providing a sophisticated approach to generating accurate and context-rich responses.
We just posted an in-depth course on the freeCodeCamp.org YouTube channel that will teach you how to implement RAG from scratch. Lance Martin created this course. He is a software engineer at LangChain with a PhD in applied machine learning from Stanford.
What is RAG?
Retrieval-Augmented Generation (RAG) is a powerful framework that integrates retrieval into the sequence generation process. Essentially, RAG operates by fetching relevant documents or data snippets based on a query and then using this retrieved information to generate a coherent and contextually appropriate response. This method is particularly valuable in fields like chatbot development, where the ability to provide precise answers derived from extensive databases of knowledge is crucial.
RAG fundamentally enhances the natural language understanding and generation capabilities of models by allowing them to access and leverage a vast amount of external knowledge. The approach is built upon the synergy between two main components: a retrieval system and a generative model. The retrieval system first identifies relevant information from a knowledge base, which the generative model then uses to craft responses that are not only accurate but also rich in detail and scope.
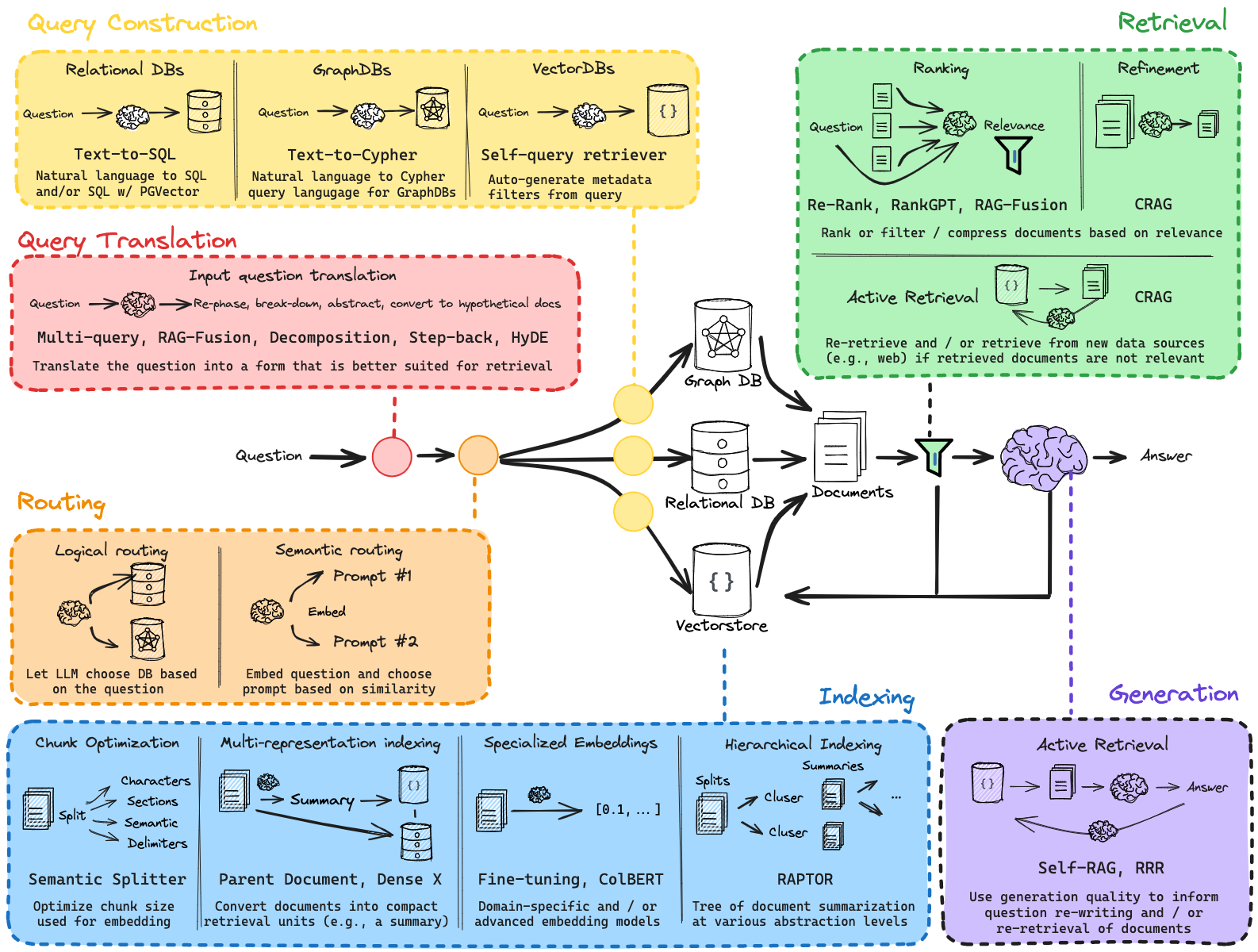
Course Breakdown
Lance Martin’s course meticulously covers all aspects of RAG, beginning with an overview that sets the stage for deeper exploration. The course is structured to walk students through the entire process of implementing a RAG system from the ground up:
Indexing: Learners will start by understanding how to create efficient indexing systems to store and retrieve data, which is fundamental for any retrieval-based model.
Retrieval: This section dives into the mechanics of retrieving the most relevant documents in response to a query.
Generation: After retrieval, the focus shifts to generating coherent text from the retrieved data, using advanced natural language processing techniques.
Query Translation: Multiple strategies for translating and refining queries are discussed, including Multi-Query techniques, RAG Fusion, Decomposition, Step Back, and HyDE approaches, each offering unique benefits depending on the application.
Routing, Query Construction, and Advanced Indexing Techniques: These segments explore more sophisticated elements of RAG systems, such as routing queries to appropriate models, constructing effective queries, and advanced indexing techniques like RAPTOR and ColBERT.
CRAG and Adaptive RAG: The course also introduces CRAG (Conditional RAG) and Adaptive RAG, enhancements that provide even more flexibility and power to the standard RAG framework.
Is RAG Really Dead?: Finally, a discussion on the current and future relevance of RAG in research and practical applications, stimulating critical thinking and exploration beyond the course.
Each section is packed with practical exercises, real-life examples, and detailed explanations that ensure students not only learn the theory but also apply the concepts in practical settings.
This course is ideal for software engineers, data scientists, and researchers with a solid foundation in machine learning and natural language processing who are looking to expand their expertise in advanced AI techniques.
Watch the full course on the freeCodeCamp.org YouTube channel (2.5-hour watch).