

The rapid evolution of artificial intelligence (AI) has resulted in a powerful synergy between large language models (LLMs) and AI agents. This dynamic interplay is sort of like the tale of David and Goliath (without the fighting), where nimble AI agents enhance and amplify the capabilities of the colossal LLMs.
This handbook will explore how AI agents – akin to David – are supercharging LLMs – our modern-day Goliaths – to help revolutionize various industries and scientific domains.
Table of Contents
Chapter 2: The History of Artificial Intelligence and AI-Agents
Chapter 4: The Philosophical Foundation of Intelligent Systems
Chapter 6: Architectural Design for Integrating AI Agents with LLMs
The Emergence of AI Agents in Language Models
AI agents are autonomous systems designed to perceive their environment, make decisions, and execute actions to achieve specific goals. When integrated with LLMs, these agents can perform complex tasks, reason about information, and generate innovative solutions.
This combination has led to significant advancements across multiple sectors, from software development to scientific research.
Transformative Impact Across Industries
The integration of AI agents with LLMs has had a profound impact on various industries:
Software Development: AI-powered coding assistants, such as GitHub Copilot, have demonstrated the ability to generate up to 40% of code, leading to a remarkable 55% increase in development speed.
Education: AI-powered learning assistants have shown promise in reducing average course completion time by 27%, potentially revolutionizing the educational landscape.
Transportation: With projections suggesting that 10% of vehicles will be driverless by 2030, autonomous AI agents in self-driving cars are poised to transform the transportation industry.
Advancing Scientific Discovery
One of the most exciting applications of AI agents and LLMs is in scientific research:
Drug Discovery: AI agents are accelerating the drug discovery process by analyzing vast datasets and predicting potential drug candidates, significantly reducing the time and cost associated with traditional methods.
Particle Physics: At CERN's Large Hadron Collider, AI agents are employed to analyze particle collision data, using anomaly detection to identify promising leads that could indicate the existence of undiscovered particles.
General Scientific Research: AI agents are enhancing the pace and scope of scientific discoveries by analyzing past studies, identifying unexpected links, and proposing novel experiments.
The convergence of AI agents and large language models (LLMs) is propelling artificial intelligence into a new era of unprecedented capabilities. This comprehensive handbook examines the dynamic interplay between these two technologies, unveiling their combined potential to revolutionize industries and solve complex problems.
We will trace the evolution of AI from its origins to the advent of autonomous agents and the rise of sophisticated LLMs. We'll also explore ethical considerations, which are fundamental to responsible AI development. This will help us ensure that these technologies align with our human values and societal well-being.
By the conclusion of this handbook, you will have a profound understanding of the synergistic power of AI agents and LLMs, along with the knowledge and tools to leverage this cutting-edge technology.
Chapter 1: Introduction to AI Agents and Language Models
What Are AI Agents and Large Language Models?
The rapid evolution of artificial intelligence (AI) has brought forth a transformative synergy between large language models (LLMs) and AI agents.
AI agents are autonomous systems designed to perceive their environment, make decisions, and execute actions to achieve specific goals. They exhibit characteristics such as autonomy, perception, reactivity, reasoning, decision-making, learning, communication, and goal-orientation.
On the other hand, LLMs are sophisticated AI systems that utilize deep learning techniques and vast datasets to understand, generate, and predict human-like text.
These models, such as GPT-4, Mistral, LLama, have demonstrated remarkable capabilities in natural language processing tasks, including text generation, language translation, and conversational agents.
Key Characteristics of AI Agents
AI agents possess several defining features that set them apart from traditional software:
Autonomy: They can operate independently without constant human intervention.
Perception: Agents can sense and interpret their environment through various inputs.
Reactivity: They respond dynamically to changes in their environment.
Reasoning and Decision-making: Agents can analyze data and make informed choices.
Learning: They improve their performance over time through experience.
Communication: Agents can interact with other agents or humans using various methods.
Goal-orientation: They are designed to achieve specific objectives.
Capabilities of Large Language Models
LLMs have demonstrated a wide range of capabilities, including:
Text Generation: LLMs can produce coherent and contextually relevant text based on prompts.
Language Translation: They can translate text between different languages with high accuracy.
Summarization: LLMs can condense long texts into concise summaries while retaining key information.
Question Answering: They can provide accurate responses to queries based on their vast knowledge base.
Sentiment Analysis: LLMs can analyze and determine the sentiment expressed in a given text.
Code Generation: They can generate code snippets or entire functions based on natural language descriptions.
Levels of AI Agents
AI agents can be classified into different levels based on their capabilities and complexity. According to a paper on arXiv, AI agents are categorized into five levels:
Level 1 (L1): AI agents as research assistants, where scientists set hypotheses and specify tasks to achieve objectives.
Level 2 (L2): AI agents that can autonomously perform specific tasks within a defined scope, such as data analysis or simple decision-making.
Level 3 (L3): AI agents capable of learning from experience and adapting to new situations, enhancing their decision-making processes.
Level 4 (L4): AI agents with advanced reasoning and problem-solving abilities, capable of handling complex, multi-step tasks.
Level 5 (L5): Fully autonomous AI agents that can operate independently in dynamic environments, making decisions and taking actions without human intervention.
Limitations of Large Language Models
Training Costs and Resource Constraints
Large language models (LLMs) such as GPT-3 and PaLM have revolutionized natural language processing (NLP) by leveraging deep learning techniques and vast datasets.
But these advancements come at a significant cost. Training LLMs requires substantial computational resources, often involving thousands of GPUs and extensive energy consumption.
According to Sam Altman, CEO of OpenAI, the training cost for GPT-4 exceeded $100 million. This aligns with the model's reported scale and complexity, with estimates suggesting it has around 1 trillion parameters. However, other sources offer different figures:
A leaked report indicated that GPT-4's training costs were approximately $63 million, considering the computational power and training duration.
As of mid-2023, some estimates suggested that training a model similar to GPT-4 could cost around $20 million and take about 55 days, reflecting advancements in efficiency.
This high cost of training and maintaining LLMs limits their widespread adoption and scalability.
Data Limitations and Bias
The performance of LLMs is heavily dependent on the quality and diversity of the training data. Despite being trained on massive datasets, LLMs can still exhibit biases present in the data, leading to skewed or inappropriate outputs. These biases can manifest in various forms, including gender, racial, and cultural biases, which can perpetuate stereotypes and misinformation.
Also, the static nature of the training data means that LLMs may not be up-to-date with the latest information, limiting their effectiveness in dynamic environments.
Specialization and Complexity
While LLMs excel in general tasks, they often struggle with specialized tasks that require domain-specific knowledge and high-level complexity.
For example, tasks in fields such as medicine, law, and scientific research demand a deep understanding of specialized terminology and nuanced reasoning, which LLMs may not possess inherently. This limitation necessitates the integration of additional layers of expertise and fine-tuning to make LLMs effective in specialized applications.
Input and Sensory Limitations
LLMs primarily process text-based inputs, which restricts their ability to interact with the world in a multimodal manner. While they can generate and understand text, they lack the capability to process visual, auditory, or sensory inputs directly.
This limitation hinders their application in fields that require comprehensive sensory integration, such as robotics and autonomous systems. For instance, an LLM cannot interpret visual data from a camera or auditory data from a microphone without additional processing layers.
Communication and Interaction Constraints
The current communication capabilities of LLMs are predominantly text-based, which limits their ability to engage in more immersive and interactive forms of communication.
For example, while LLMs can generate text responses, they cannot produce video content or holographic representations, which are increasingly important in virtual and augmented reality applications (read more here). This constraint reduces the effectiveness of LLMs in environments that demand rich, multimodal interactions.
How to Overcome Limitations with AI Agents
AI agents offer a promising solution to many of the limitations faced by LLMs. These agents are designed to operate autonomously, perceive their environment, make decisions, and execute actions to achieve specific goals. By integrating AI agents with LLMs, it is possible to enhance their capabilities and address their inherent limitations.
Enhanced Context and Memory: AI agents can maintain context over multiple interactions, allowing for more coherent and contextually relevant responses. This capability is particularly useful in applications that require long-term memory and continuity, such as customer service and personal assistants.
Multimodal Integration: AI agents can incorporate sensory inputs from various sources, such as cameras, microphones, and sensors, enabling LLMs to process and respond to visual, auditory, and sensory data. This integration is crucial for applications in robotics and autonomous systems.
Specialized Knowledge and Expertise: AI agents can be fine-tuned with domain-specific knowledge, enhancing the ability of LLMs to perform specialized tasks. This approach allows for the creation of expert systems that can handle complex queries in fields such as medicine, law, and scientific research.
Interactive and Immersive Communication: AI agents can facilitate more immersive forms of communication by generating video content, controlling holographic displays, and interacting with virtual and augmented reality environments. This capability expands the application of LLMs in fields that require rich, multimodal interactions.
While large language models have demonstrated remarkable capabilities in natural language processing, they are not without limitations. The high costs of training, data biases, specialization challenges, sensory limitations, and communication constraints present significant hurdles.
But the integration of AI agents offers a viable pathway to overcoming these limitations. By leveraging the strengths of AI agents, it is possible to enhance the functionality, adaptability, and applicability of LLMs, paving the way for more advanced and versatile AI systems.
Chapter 2: The History of Artificial Intelligence and AI-Agents
The Genesis of Artificial Intelligence
The concept of artificial intelligence (AI) has roots that extend far beyond the modern digital age. The idea of creating machines capable of human-like reasoning can be traced back to ancient myths and philosophical debates. But the formal inception of AI as a scientific discipline occurred in the mid-20th century.
The Dartmouth Conference of 1956, organized by John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon, is widely regarded as the birthplace of AI as a field of study. This seminal event brought together leading researchers to explore the potential of creating machines that could simulate human intelligence.
Early Optimism and the AI Winter
The early years of AI research were characterized by unbridled optimism. Researchers made significant strides in developing programs capable of solving mathematical problems, playing games, and even engaging in rudimentary natural language processing.
But this initial enthusiasm was tempered by the realization that creating truly intelligent machines was far more complex than initially anticipated.
The 1970s and 1980s saw a period of reduced funding and interest in AI research, commonly referred to as the "AI Winter". This downturn was primarily due to the failure of AI systems to meet the lofty expectations set by early pioneers.
From Rule-Based Systems to Machine Learning
The Era of Expert Systems
The 1980s witnessed a resurgence of interest in AI, primarily driven by the development of expert systems. These rule-based programs were designed to emulate the decision-making processes of human experts in specific domains.
Expert systems found applications in various fields, including medicine, finance, and engineering. But they were limited by their inability to learn from experience or adapt to new situations outside their programmed rules.
The Rise of Machine Learning
The limitations of rule-based systems paved the way for a paradigm shift towards machine learning. This approach, which gained prominence in the 1990s and 2000s, focuses on developing algorithms that can learn from and make predictions or decisions based on data.
Machine learning techniques, such as neural networks and support vector machines, demonstrated remarkable success in tasks like pattern recognition and data classification. The advent of big data and increased computational power further accelerated the development and application of machine learning algorithms.
The Emergence of Autonomous AI Agents
From Narrow AI to General AI
As AI technologies continued to evolve, researchers began to explore the possibility of creating more versatile and autonomous systems. This shift marked the transition from narrow AI, designed for specific tasks, to the pursuit of artificial general intelligence (AGI).
AGI aims to develop systems capable of performing any intellectual task that a human can do. While true AGI remains a distant goal, significant progress has been made in creating more flexible and adaptable AI systems.
The Role of Deep Learning and Neural Networks
The emergence of deep learning, a subset of machine learning based on artificial neural networks, has been instrumental in advancing the field of AI.
Deep learning algorithms, inspired by the structure and function of the human brain, have demonstrated remarkable capabilities in areas such as image and speech recognition, natural language processing, and game playing. These advancements have laid the groundwork for the development of more sophisticated autonomous AI agents.
Characteristics and Types of AI Agents
AI agents are autonomous systems that are able to perceive their environment, make decisions, and perform actions to achieve specific goals. They possess characteristics such as autonomy, perception, reactivity, reasoning, decision-making, learning, communication, and goal-orientation.
There are several types of AI agents, each with unique capabilities:
Simple Reflex Agents: Respond to specific stimuli based on pre-defined rules.
Model-Based Reflex Agents: Maintain an internal model of the environment for decision-making.
Goal-Based Agents: Execute actions to achieve specific goals.
Utility-Based Agents: Consider potential outcomes and choose actions that maximize expected utility.
Learning Agents: Improve decision-making over time through machine learning techniques.
Challenges and Ethical Considerations
As AI systems become increasingly advanced and autonomous, they bring critical considerations to ensure their use remains within socially accepted bounds.
Large Language Models (LLMs), in particular, act as superchargers of productivity. But this raises a crucial question: What will these systems supercharge—good intent or bad intent? When the intent behind using AI is malevolent, it becomes imperative for these systems to detect such misuse using various NLP techniques or other tools at our disposal.
LLM engineers have access to a range of tools and methodologies to address these challenges:
Sentiment Analysis: By employing sentiment analysis, LLMs can assess the emotional tone of text to detect harmful or aggressive language, helping to identify potential misuse in communication platforms.
Content Filtering: Tools like keyword filtering and pattern matching can be used to prevent the generation or dissemination of harmful content, such as hate speech, misinformation, or explicit material.
Bias Detection Tools: Implementing bias detection frameworks, such as AI Fairness 360 (IBM) or Fairness Indicators (Google), can help identify and mitigate bias in language models, ensuring that AI systems operate fairly and equitably.
Explainability Techniques: Using explainability tools like LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations), engineers can understand and explain the decision-making processes of LLMs, making it easier to detect and address unintended behaviors.
Adversarial Testing: By simulating malicious attacks or harmful inputs, engineers can stress-test LLMs using tools like TextAttack or Adversarial Robustness Toolbox, identifying vulnerabilities that could be exploited for malicious purposes.
Ethical AI Guidelines and Frameworks: Adopting ethical AI development guidelines, such as those provided by the IEEE or the Partnership on AI, can guide the creation of responsible AI systems that prioritize societal well-being.
In addition to these tools, this is why we need a dedicated Red Team for AI—specialized teams that push LLMs to their limits to detect gaps in their defenses. Red Teams simulate adversarial scenarios and uncover vulnerabilities that might otherwise go unnoticed.
But it’s important to recognize that the people behind the product have by far the strongest effect on it. Many of the attacks and challenges we face today have existed even before LLMs were developed, highlighting that the human element remains central to ensuring AI is used ethically and responsibly.
The integration of these tools and techniques into the development pipeline, alongside a vigilant Red Team, is essential for ensuring that LLMs are used to supercharge positive outcomes while detecting and preventing their misuse.
Chapter 3: Where AI-Agents Shine The Brightest
The Unique Strengths of AI Agents
AI agents stand out thanks to their ability to autonomously perceive their environment, make decisions, and execute actions to achieve specific goals. This autonomy, combined with advanced machine learning capabilities, allows AI agents to perform tasks that are either too complex or too repetitive for humans.
Here are the key strengths that make AI agents shine:
Autonomy and Efficiency: AI agents can operate independently without constant human intervention. This autonomy allows them to handle tasks 24/7, significantly improving efficiency and productivity. For example, AI-powered chatbots can handle up to 80% of routine customer inquiries, reducing operational costs and improving response times.
Advanced Decision-Making: AI agents can analyze vast amounts of data to make informed decisions. This capability is particularly valuable in fields like finance, where AI trading bots can increase trading efficiency by a lot.
Learning and Adaptability: AI agents can learn from experience and adapt to new situations. This continuous improvement enables them to enhance their performance over time. For instance, AI health assistants can help reduce diagnostic errors, improving healthcare outcomes.
Personalization: AI agents can provide personalized experiences by analyzing user behavior and preferences. Amazon's recommendation engine, which drives 35% of its sales, is a prime example of how AI agents can enhance user experience and boost revenue.
Why AI Agents Are the Solution
AI agents offer solutions to many of the challenges faced by traditional software and human-operated systems. Here’s why they are the preferred choice:
Scalability: AI agents can scale operations without proportional increases in cost. This scalability is crucial for businesses looking to grow without significantly increasing their workforce or operational expenses.
Consistency and Reliability: Unlike humans, AI agents do not suffer from fatigue or inconsistency. They can perform repetitive tasks with high accuracy and reliability, ensuring consistent performance.
Data-Driven Insights: AI agents can process and analyze large datasets to uncover patterns and insights that may be missed by humans. This capability is invaluable for decision-making in areas such as finance, healthcare, and marketing.
Cost Savings: By automating routine tasks, AI agents can reduce the need for human resources, leading to significant cost savings. For example, AI-powered fraud detection systems can save billions of dollars annually by reducing fraudulent activities.
Conditions Required for AI Agents to Perform Well
To ensure the successful deployment and performance of AI agents, certain conditions must be met:
Clear Objectives and Use Cases: Defining specific goals and use cases is crucial for the effective deployment of AI agents. This clarity helps in setting expectations and measuring success. For instance, setting a goal to reduce customer service response times by 50% can guide the deployment of AI chatbots.
Quality Data: AI agents rely on high-quality data for training and operation. Ensuring that the data is accurate, relevant, and up-to-date is essential for the agents to make informed decisions and perform effectively.
Integration with Existing Systems: Seamless integration with existing systems and workflows is necessary for AI agents to function optimally. This integration ensures that AI agents can access the necessary data and interact with other systems to perform their tasks.
Continuous Monitoring and Optimization: Regular monitoring and optimization of AI agents are crucial to maintain their performance. This involves tracking key performance indicators (KPIs) and making necessary adjustments based on feedback and performance data.
Ethical Considerations and Bias Mitigation: Addressing ethical considerations and mitigating biases in AI agents is essential to ensure fairness and inclusivity. Implementing measures to detect and prevent bias can help in building trust and ensuring responsible deployment.
Best Practices for Deploying AI Agents
When deploying AI agents, following best practices can ensure their success and effectiveness:
Define Objectives and Use Cases: Clearly identify the goals and use cases for deploying AI agents. This helps in setting expectations and measuring success.
Select the Right AI Platform: Choose an AI platform that aligns with your objectives, use cases, and existing infrastructure. Consider factors like integration capabilities, scalability, and cost.
Develop a Comprehensive Knowledge Base: Build a well-structured and accurate knowledge base to enable AI agents to provide relevant and reliable responses.
Ensure Seamless Integration: Integrate AI agents with existing systems like CRM and call center technologies to provide a unified customer experience.
Train and Optimize AI Agents: Continuously train and optimize AI agents using data from interactions. Monitor performance, identify areas for improvement, and update models accordingly.
Implement Proper Escalation Procedures: Establish protocols for transferring complex or emotional calls to human agents, ensuring a smooth transition and efficient resolution.
Monitor and Analyze Performance: Track key performance indicators (KPIs) such as call resolution rates, average handle time, and customer satisfaction scores. Use analytics tools for data-driven insights and decision-making.
Ensure Data Privacy and Security: robust security measures are key, like making data anonymous, ensuring human oversight, setting up policies for data retention, and putting strong encryption measures in place to protect customer data and maintain privacy.
AI Agents + LLMs: A New Era of Smart Software
Imagine software that not only understands your requests but can also carry them out. That's the promise of combining AI agents with Large Language Models (LLMs). This powerful pairing is creating a new breed of applications that are more intuitive, capable, and impactful than ever before.
AI Agents: Beyond Simple Task Execution
While often compared to digital assistants, AI agents are far more than glorified script followers. They encompass a range of sophisticated technologies and operate on a framework that enables dynamic decision-making and action-taking.
Architecture: A typical AI agent comprises several key components:
Sensors: These allow the agent to perceive its environment, gathering data from various sources like sensors, APIs, or user input.
Belief State: This represents the agent's understanding of the world based on the data gathered. It's constantly updated as new information becomes available.
Reasoning Engine: This is the core of the agent's decision-making process. It uses algorithms, often based on reinforcement learning or planning techniques, to determine the best course of action based on its current beliefs and goals.
Actuators: These are the agent's tools for interacting with the world. They can range from sending API calls to controlling physical robots.
Challenges: Traditional AI agents, while proficient at handling well-defined tasks, often struggle with:
Natural Language Understanding: Interpreting nuanced human language, handling ambiguity, and extracting meaning from context remain significant challenges.
Reasoning with Common Sense: Current AI agents often lack the common sense knowledge and reasoning abilities that humans take for granted.
Generalization: Training agents to perform well on unseen tasks or adapt to new environments remains a key area of research.
LLMs: Unlocking Language Understanding and Generation
LLMs, with their vast knowledge encoded within billions of parameters, bring unprecedented language capabilities to the table:
Transformer Architecture: The foundation of most modern LLMs is the transformer architecture, a neural network design that excels at processing sequential data like text. This allows LLMs to capture long-range dependencies in language, enabling them to understand context and generate coherent and contextually relevant text.
Capabilities: LLMs excel at a wide range of language-based tasks:
Text Generation: From writing creative fiction to generating code in multiple programming languages, LLMs display remarkable fluency and creativity.
Question Answering: They can provide concise and accurate answers to questions, even when the information is spread across lengthy documents.
Summarization: LLMs can condense large volumes of text into concise summaries, extracting key information and discarding irrelevant details.
Limitations: Despite their impressive abilities, LLMs have limitations:
Lack of Real-World Grounding: LLMs primarily operate in the realm of text and lack the ability to interact directly with the physical world.
Potential for Bias and Hallucination: Trained on massive, uncurated datasets, LLMs can inherit biases present in the data and sometimes generate factually incorrect or nonsensical information.
The Synergy: Bridging the Gap Between Language and Action
The combination of AI agents and LLMs addresses the limitations of each, creating systems that are both intelligent and capable:
LLMs as Interpreters and Planners: LLMs can translate natural language instructions into a format that AI agents can understand, enabling more intuitive human-computer interaction. They can also leverage their knowledge to assist agents in planning complex tasks by breaking them down into smaller, manageable steps.
AI Agents as Executors and Learners: AI agents provide LLMs with the ability to interact with the world, gather information, and receive feedback on their actions. This real-world grounding can help LLMs learn from experience and improve their performance over time.
This potent synergy is driving the development of a new generation of applications that are more intuitive, adaptable, and capable than ever before. As both AI agent and LLM technologies continue to advance, we can expect to see even more innovative and impactful applications emerge, reshaping the landscape of software development and human-computer interaction.
Real-World Examples: Transforming Industries
This powerful combination is already making waves across various sectors:
Customer Service: Resolving Issues with Contextual Awareness
- Example: Imagine a customer contacting an online retailer about a delayed shipment. An AI agent powered by an LLM can understand the customer's frustration, access their order history, track the package in real-time, and proactively offer solutions like expedited shipping or a discount on their next purchase.
Content Creation: Generating High-Quality Content at Scale
- Example: A marketing team can use an AI agent + LLM system to generate targeted social media posts, write product descriptions, or even create video scripts. The LLM ensures the content is engaging and informative, while the AI agent handles the publishing and distribution process.
Software Development: Accelerating Coding and Debugging
- Example: A developer can describe a software feature they want to build using natural language. The LLM can then generate code snippets, identify potential errors, and suggest improvements, significantly speeding up the development process.
Healthcare: Personalizing Treatment and Improving Patient Care
- Example: An AI agent with access to a patient's medical history and equipped with an LLM can answer their health-related questions, provide personalized medication reminders, and even offer preliminary diagnoses based on their symptoms.
Law: Streamlining Legal Research and Document Drafting
- Example: A lawyer needs to draft a contract with specific clauses and legal precedents. An AI agent powered by an LLM can analyze the lawyer's instructions, search through vast legal databases, identify relevant clauses and precedents, and even draft portions of the contract, significantly reducing the time and effort required.
Video Creation: Generating Engaging Videos with Ease
- Example: A marketing team wants to create a short video explaining their product's features. They can provide an AI agent + LLM system with a script outline and visual style preferences. The LLM can then generate a detailed script, suggest appropriate music and visuals, and even edit the video, automating much of the video creation process.
Architecture: Designing Buildings with AI-Powered Insights
- Example: An architect is designing a new office building. They can use an AI agent + LLM system to input their design goals, such as maximizing natural light and optimizing space utilization. The LLM can then analyze these goals, generate different design options, and even simulate how the building would perform under different environmental conditions.
Construction: Improving Safety and Efficiency on Construction Sites
- Example: An AI agent equipped with cameras and sensors can monitor a construction site for safety hazards. If a worker is not wearing proper safety gear or a piece of equipment is left in a dangerous position, the LLM can analyze the situation, alert the site supervisor, and even automatically halt operations if necessary.
The Future is Here: A New Era of Software Development
The convergence of AI agents and LLMs marks a significant leap forward in software development. As these technologies continue to evolve, we can expect to see even more innovative applications emerge, transforming industries, streamlining workflows, and creating entirely new possibilities for human-computer interaction.
AI agents shine the brightest in areas that require processing vast amounts of data, automating repetitive tasks, making complex decisions, and providing personalized experiences. By meeting the necessary conditions and following best practices, organizations can harness the full potential of AI agents to drive innovation, efficiency, and growth.
Chapter 4: The Philosophical Foundation of Intelligent Systems
The development of intelligent systems, especially in the field of artificial intelligence (AI), requires a thorough understanding of philosophical principles. This chapter delves into the core philosophical ideas that shape the design, development, and use of AI. It highlights the importance of aligning technological progress with ethical values.
The philosophical foundation of intelligent systems is not just a theoretical exercise – it's a vital framework that ensures AI technologies benefit humanity. By promoting fairness, inclusivity, and improving the quality of life, these principles help guide AI to serve our best interests.
Ethical Considerations in AI Development
As AI systems become increasingly integrated into every facet of human life, from healthcare and education to finance and governance, we need to rigorously examine and implement the ethical imperatives guiding their design and deployment.
The fundamental ethical question revolves around how AI can be crafted to embody and uphold human values and moral principles. This question is central to the way AI will shape the future of societies worldwide.
At the heart of this ethical discourse is the principle of beneficence, a cornerstone of moral philosophy that dictates actions should aim to do good and enhance the well-being of individuals and society at large (Floridi & Cowls, 2019).
In the context of AI, beneficence translates into designing systems that actively contribute to human flourishing—systems that improve healthcare outcomes, augment educational opportunities, and facilitate equitable economic growth.
But the application of beneficence in AI is far from straightforward. It demands a nuanced approach that carefully weighs the potential benefits of AI against the possible risks and harms.
One of the key challenges in applying the principle of beneficence to AI development is the need for a delicate balance between innovation and safety.
AI has the potential to revolutionize fields such as medicine, where predictive algorithms can diagnose diseases earlier and with greater accuracy than human doctors. But without stringent ethical oversight, these same technologies could exacerbate existing inequalities.
This could happen, for instance, if they are primarily deployed in wealthy regions while underserved communities continue to lack basic healthcare access.
Because of this, ethical AI development requires not only a focus on the maximization of benefits but also a proactive approach to risk mitigation. This involves implementing robust safeguards to prevent the misuse of AI and ensuring that these technologies do not inadvertently cause harm.
The ethical framework for AI must also be inherently inclusive, ensuring that the benefits of AI are distributed equitably across all societal groups, including those who are traditionally marginalized. This calls for a commitment to justice and fairness, ensuring that AI does not simply reinforce the status quo but actively works to dismantle systemic inequalities.
For instance, AI-driven job automation has the potential to boost productivity and economic growth. But it could also lead to significant job displacement, disproportionately affecting low-income workers.
So as you can see, an ethically sound AI framework must include strategies for equitable benefit-sharing and the provision of support systems for those adversely impacted by AI advancements.
The ethical development of AI requires continuous engagement with diverse stakeholders, including ethicists, technologists, policymakers, and the communities that will be most affected by these technologies. This interdisciplinary collaboration ensures that AI systems are not developed in a vacuum but are instead shaped by a broad spectrum of perspectives and experiences.
It is through this collective effort that we can create AI systems that not only reflect but also uphold the values that define our humanity—compassion, fairness, respect for autonomy, and a commitment to the common good.
The ethical considerations in AI development are not just guidelines, but essential elements that will determine whether AI serves as a force for good in the world. By grounding AI in the principles of beneficence, justice, and inclusivity, and by maintaining a vigilant approach to the balance of innovation and risk, we can ensure that AI development does not just advance technology, but also enhances the quality of life for all members of society.
As we continue to explore the capabilities of AI, it is imperative that these ethical considerations remain at the forefront of our endeavors, guiding us toward a future where AI truly benefits humanity.
The Imperative of Human-Centric AI Design
Human-centric AI design transcends mere technical considerations. It's rooted in deep philosophical principles that prioritize human dignity, autonomy, and agency.
This approach to AI development is fundamentally anchored in the Kantian ethical framework, which asserts that humans must be regarded as ends in themselves, not merely as instruments for achieving other goals (Kant, 1785).
The implications of this principle for AI design are profound, requiring that AI systems be developed with an unwavering focus on serving human interests, preserving human agency, and respecting individual autonomy.
Technical Implementation of Human-Centric Principles
Enhancing Human Autonomy through AI: The concept of autonomy in AI systems is critical, particularly in ensuring that these technologies empower users rather than controlling or unduly influencing them.
In technical terms, this involves designing AI systems that prioritize user autonomy by providing them with the tools and information needed to make informed decisions. This requires AI models to be context-aware, meaning that they must understand the specific context in which a decision is made and adjust their recommendations accordingly.
From a systems design perspective, this involves the integration of contextual intelligence into AI models, which allows these systems to dynamically adapt to the user's environment, preferences, and needs.
For example, in healthcare, an AI system that assists doctors in diagnosing conditions must consider the patient's unique medical history, current symptoms, and even psychological state to offer recommendations that support the doctor's expertise rather than supplanting it.
This contextual adaptation ensures that AI remains a supportive tool that enhances, rather than diminishes, human autonomy.
Ensuring Transparent Decision-Making Processes: Transparency in AI systems is a fundamental requirement for ensuring that users can trust and understand the decisions made by these technologies. Technically, this translates into the need for explainable AI (XAI), which involves developing algorithms that can clearly articulate the rationale behind their decisions.
This is especially crucial in domains like finance, healthcare, and criminal justice, where opaque decision-making can lead to mistrust and ethical concerns.
Explainability can be achieved through several technical approaches. One common method is post-hoc interpretability, where the AI model generates an explanation after the decision is made. This might involve breaking down the decision into its constituent factors and showing how each one contributed to the final outcome.
Another approach is inherently interpretable models, where the model's architecture is designed in such a way that its decisions are transparent by default. For instance, models like decision trees and linear models are naturally interpretable because their decision-making process is easy to follow and understand.
The challenge in implementing explainable AI lies in balancing transparency with performance. Often, more complex models, such as deep neural networks, are less interpretable but more accurate. Thus, the design of human-centric AI must consider the trade-off between the interpretability of the model and its predictive power, ensuring that users can trust and comprehend AI decisions without sacrificing accuracy.
Enabling Meaningful Human Oversight: Meaningful human oversight is critical in ensuring that AI systems operate within ethical and operational boundaries. This oversight involves designing AI systems with fail-safes and override mechanisms that allow human operators to intervene when necessary.
The technical implementation of human oversight can be approached in several ways.
One approach is to incorporate human-in-the-loop systems, where AI decision-making processes are continuously monitored and evaluated by human operators. These systems are designed to allow human intervention at critical junctures, ensuring that AI does not act autonomously in situations where ethical judgments are required.
For example, in the case of autonomous weapons systems, human oversight is essential to prevent the AI from making life-or-death decisions without human input. This could involve setting strict operational boundaries that the AI cannot cross without human authorization, thus embedding ethical safeguards into the system.
Another technical consideration is the development of audit trails, which are records of all decisions and actions taken by the AI system. These trails provide a transparent history that can be reviewed by human operators to ensure compliance with ethical standards.
Audit trails are particularly important in sectors such as finance and law, where decisions must be documented and justifiable to maintain public trust and meet regulatory requirements.
Balancing Autonomy and Control: A key technical challenge in human-centric AI is finding the right balance between autonomy and control. While AI systems are designed to operate autonomously in many scenarios, it is crucial that this autonomy does not undermine human control or oversight.
This balance can be achieved through the implementation of autonomy levels, which dictate the degree of independence the AI has in making decisions.
For instance, in semi-autonomous systems like self-driving cars, autonomy levels range from basic driver assistance (where the human driver remains in full control) to full automation (where the AI is responsible for all driving tasks).
The design of these systems must ensure that, at any given autonomy level, the human operator retains the ability to intervene and override the AI if necessary. This requires sophisticated control interfaces and decision-support systems that allow humans to quickly and effectively take control when needed.
Additionally, the development of ethical AI frameworks is essential for guiding the autonomous actions of AI systems. These frameworks are sets of rules and guidelines embedded within the AI that dictate how it should behave in ethically complex situations.
For example, in healthcare, an ethical AI framework might include rules about patient consent, privacy, and the prioritization of treatments based on medical need rather than financial considerations.
By embedding these ethical principles directly into the AI's decision-making processes, developers can ensure that the system's autonomy is exercised in a way that aligns with human values.
The integration of human-centric principles into AI design is not merely a philosophical ideal but a technical necessity. By enhancing human autonomy, ensuring transparency, enabling meaningful oversight, and carefully balancing autonomy with control, AI systems can be developed in a way that truly serves humanity.
These technical considerations are essential for creating AI that not only augments human capabilities but also respects and upholds the values that are fundamental to our society.
As AI continues to evolve, the commitment to human-centric design will be crucial in ensuring that these powerful technologies are used ethically and responsibly.
How to Ensure that AI Benefits Humanity: Enhancing Quality of Life
As you engage in the development of AI systems, it’s essential to ground your efforts in the ethical framework of utilitarianism—a philosophy that emphasizes the enhancement of overall happiness and well-being.
Within this context, AI holds the potential to address critical societal challenges, particularly in areas like healthcare, education, and environmental sustainability.
The goal is to create technologies that significantly improve the quality of life for all. But this pursuit comes with complexities. Utilitarianism offers a compelling reason to deploy AI widely, but it also brings to the fore important ethical questions about who benefits and who might be left behind, especially among vulnerable populations.
To navigate these challenges, we need a sophisticated, technically informed approach—one that balances the broad pursuit of societal good with the need for justice and fairness.
When applying utilitarian principles to AI, your focus should be on optimizing outcomes in specific domains. In healthcare, for example, AI-driven diagnostic tools have the potential to vastly improve patient outcomes by enabling earlier and more accurate diagnoses. These systems can analyze extensive datasets to detect patterns that might elude human practitioners, thus expanding access to quality care, particularly in under-resourced settings.
But, deploying these technologies requires careful consideration to avoid reinforcing existing inequalities. The data used to train AI models can vary significantly across regions, affecting the accuracy and reliability of these systems.
This disparity highlights the importance of establishing robust data governance frameworks that ensure your AI-driven healthcare solutions are both representative and fair.
In the educational sphere, AI’s ability to personalize learning is promising. AI systems can adapt educational content to meet the specific needs of individual students, thereby enhancing learning outcomes. By analyzing data on student performance and behavior, AI can identify where a student might be struggling and provide targeted support.
But as you work towards these benefits, it’s crucial to be aware of the risks—such as the potential to reinforce biases or marginalize students who don’t fit typical learning patterns.
Mitigating these risks requires the integration of fairness mechanisms into AI models, ensuring they do not inadvertently favor certain groups. And maintaining the role of educators is critical. Their judgment and experience are indispensable in making AI tools truly effective and supportive.
In terms of environmental sustainability, AI’s potential is considerable. AI systems can optimize resource use, monitor environmental changes, and predict the impacts of climate change with unprecedented precision.
For example, AI can analyze vast amounts of environmental data to forecast weather patterns, optimize energy consumption, and minimize waste—actions that contribute to the well-being of current and future generations.
But this technological advancement comes with its own set of challenges, particularly regarding the environmental impact of the AI systems themselves.
The energy consumption required to operate large-scale AI systems can offset the environmental benefits they aim to achieve. So developing energy-efficient AI systems is crucial to ensuring that their positive impact on sustainability is not undermined.
As you develop AI systems with utilitarian goals, it’s important to also consider the implications for social justice. Utilitarianism focuses on maximizing overall happiness but doesn’t inherently address the distribution of benefits and harms across different societal groups.
This raises the potential for AI systems to disproportionately benefit those who are already privileged, while marginalized groups may see little to no improvement in their circumstances.
To counteract this, your AI development process should incorporate equity-focused principles, ensuring that the benefits are distributed fairly and that any potential harms are addressed. This might involve designing algorithms that specifically aim to reduce biases and involving a diverse range of perspectives in the development process.
As you work to develop AI systems aimed at improving quality of life, it’s essential to balance the utilitarian goal of maximizing well-being with the need for justice and fairness. This requires a nuanced, technically grounded approach that considers the broader implications of AI deployment.
By carefully designing AI systems that are both effective and equitable, you can contribute to a future where technological advancements truly serve the diverse needs of society.
Implement Safeguards Against Potential Harm
When developing AI technologies, you must recognize the inherent potential for harm and proactively establish robust safeguards to mitigate these risks. This responsibility is deeply rooted in deontological ethics. This branch of ethics emphasizes the moral duty to adhere to established rules and ethical standards, ensuring that the technology you create aligns with fundamental moral principles.
Implementing stringent safety protocols is not just a precaution but an ethical obligation. These protocols should encompass comprehensive bias testing, transparency in algorithmic processes, and clear mechanisms for accountability.
Such safeguards are essential to preventing AI systems from causing unintended harm, whether through biased decision-making, opaque processes, or lack of oversight.
In practice, implementing these safeguards requires a deep understanding of both the technical and ethical dimensions of AI.
Bias testing, for example, involves not only identifying and correcting biases in data and algorithms but also understanding the broader societal implications of those biases. You must ensure that your AI models are trained on diverse, representative datasets and are regularly evaluated to detect and correct any biases that may emerge over time.
Transparency, on the other hand, demands that AI systems are designed in such a way that their decision-making processes can be easily understood and scrutinized by users and stakeholders. This involves developing explainable AI models that provide clear, interpretable outputs, allowing users to see how decisions are made and ensuring that those decisions are justifiable and fair.
Also, accountability mechanisms are crucial for maintaining trust and ensuring that AI systems are used responsibly. These mechanisms should include clear guidelines for who is responsible for the outcomes of AI decisions, as well as processes for addressing and rectifying any harms that may occur.
You must establish a framework where ethical considerations are integrated into every stage of AI development, from initial design to deployment and beyond. This includes not only following ethical guidelines but also continuously monitoring and adjusting AI systems as they interact with the real world.
By embedding these safeguards into the very fabric of AI development, you can help ensure that technological progress serves the greater good without leading to unintended negative consequences.
The Role of Human Oversight and Feedback Loops
Human oversight in AI systems is a critical component of ensuring ethical AI deployment. The principle of responsibility underpins the need for continuous human involvement in the operation of AI, particularly in high-stakes environments such as healthcare and criminal justice.
Feedback loops, where human input is used to refine and improve AI systems, are essential for maintaining accountability and adaptability (Raji et al., 2020). These loops allow for the correction of errors and the integration of new ethical considerations as societal values evolve.
By embedding human oversight into AI systems, developers can create technologies that are not only effective but also aligned with ethical norms and human expectations.
Coding Ethics: Translating Philosophical Principles into AI Systems
The translation of philosophical principles into AI systems is a complex but necessary task. This process involves embedding ethical considerations into the very code that drives AI algorithms.
Concepts such as fairness, justice, and autonomy must be codified within AI systems to ensure that they operate in ways that reflect societal values. This requires a multidisciplinary approach, where ethicists, engineers, and social scientists collaborate to define and implement ethical guidelines in the coding process.
The goal is to create AI systems that are not only technically proficient but also morally sound, capable of making decisions that respect human dignity and promote social good (Mittelstadt et al., 2016).
Promote Inclusivity and Equitable Access in AI Development and Deployment
Inclusivity and equitable access are fundamental to the ethical development of AI. The Rawlsian concept of justice as fairness provides a philosophical foundation for ensuring that AI systems are designed and deployed in ways that benefit all members of society, particularly those who are most vulnerable (Rawls, 1971).
This involves proactive efforts to include diverse perspectives in the development process, especially from underrepresented groups and the Global South.
By incorporating these diverse viewpoints, AI developers can create systems that are more equitable and responsive to the needs of a broader range of users. Also, ensuring equitable access to AI technologies is crucial for preventing the exacerbation of existing social inequalities.
Address Algorithmic Bias and Fairness
Algorithmic bias is a significant ethical concern in AI development, as biased algorithms can perpetuate and even exacerbate societal inequalities. Addressing this issue requires a commitment to procedural justice, ensuring that AI systems are developed through fair processes that consider the impact on all stakeholders (Nissenbaum, 2001).
This involves identifying and mitigating biases in training data, developing algorithms that are transparent and explainable, and implementing fairness checks throughout the AI lifecycle.
By addressing algorithmic bias, developers can create AI systems that contribute to a more just and equitable society, rather than reinforcing existing disparities.
Incorporate Diverse Perspectives in AI Development
Incorporating diverse perspectives into AI development is essential for creating systems that are inclusive and equitable. The inclusion of voices from underrepresented groups ensures that AI technologies do not simply reflect the values and priorities of a narrow segment of society.
This approach aligns with the philosophical principle of deliberative democracy, which emphasizes the importance of inclusive and participatory decision-making processes (Habermas, 1996).
By fostering diverse participation in AI development, we can ensure that these technologies are designed to serve the interests of all humanity, rather than a privileged few.
Strategies for Bridging the AI Divide
The AI divide, characterized by unequal access to AI technologies and their benefits, poses a significant challenge to global equity. Bridging this divide requires a commitment to distributive justice, ensuring that the benefits of AI are shared broadly across different socioeconomic groups and regions (Sen, 2009).
We can do this through initiatives that promote access to AI education and resources in underserved communities, as well as policies that support the equitable distribution of AI-driven economic gains. By addressing the AI divide, we can ensure that AI contributes to global development in a way that is inclusive and equitable.
Balance Innovation with Ethical Constraints
Balancing the pursuit of innovation with ethical constraints is crucial for responsible AI advancement. The precautionary principle, which advocates for caution in the face of uncertainty, is particularly relevant in the context of AI development (Sandin, 1999).
While innovation drives progress, it must be tempered by ethical considerations that protect against potential harms. This requires a careful assessment of the risks and benefits of new AI technologies, as well as the implementation of regulatory frameworks that ensure ethical standards are upheld.
By balancing innovation with ethical constraints, we can foster the development of AI technologies that are both cutting-edge and aligned with the broader goals of societal well-being.
As you can see, the philosophical foundation of intelligent systems provides a critical framework for ensuring that AI technologies are developed and deployed in ways that are ethical, inclusive, and beneficial to all of humanity.
By grounding AI development in these philosophical principles, we can create intelligent systems that not only advance technological capabilities but also enhance the quality of life, promote justice, and ensure that the benefits of AI are shared equitably across society.
Chapter 5: AI Agents as LLM Enhancers
The fusion of AI agents with Large Language Models (LLMs) represents a fundamental shift in artificial intelligence, addressing critical limitations in LLMs that have constrained their broader applicability.
This integration enables machines to transcend their traditional roles, advancing from passive text generators to autonomous systems capable of dynamic reasoning and decision-making.
As AI systems increasingly drive critical processes across various domains, understanding how AI agents fill the gaps in LLM capabilities is essential for realizing their full potential.
Bridging the Gaps in LLM Capabilities
LLMs, while powerful, are inherently constrained by the data they were trained on and the static nature of their architecture. These models operate within a fixed set of parameters, typically defined by the corpus of text used during their training phase.
This limitation means that LLMs cannot autonomously seek out new information or update their knowledge base post-training. Consequently, LLMs are often outdated and lack the ability to provide contextually relevant responses that require real-time data or insights beyond their initial training data.
AI agents bridge these gaps by dynamically integrating external data sources, which can extend the functional horizon of LLMs.
For example, an LLM trained on financial data up until 2022 might provide accurate historical analyses but would struggle to generate up-to-date market forecasts. An AI agent can augment this LLM by pulling in real-time data from financial markets, applying these inputs to generate more relevant and current analyses.
This dynamic integration ensures that the outputs are not just historically accurate but also contextually appropriate for present conditions.
Enhancing Decision-Making Autonomy
Another significant limitation of LLMs is their lack of autonomous decision-making capabilities. LLMs excel at generating language-based outputs but fall short in tasks that require complex decision-making, especially in environments characterized by uncertainty and change.
This shortfall is primarily due to the model's reliance on pre-existing data and the absence of mechanisms for adaptive reasoning or learning from new experiences post-deployment.
AI agents address this by providing the necessary infrastructure for autonomous decision-making. They can take the static outputs of an LLM and process them through advanced reasoning frameworks such as rule-based systems, heuristics, or reinforcement learning models.
For instance, in a healthcare setting, an LLM might generate a list of potential diagnoses based on a patient’s symptoms and medical history. But without an AI agent, the LLM cannot weigh these options or recommend a course of action.
An AI agent can step in to evaluate these diagnoses against current medical literature, patient data, and contextual factors, ultimately making a more informed decision and suggesting actionable next steps. This synergy transforms LLM outputs from mere suggestions into executable, context-aware decisions.
Addressing Completeness and Consistency
Completeness and consistency are critical factors in ensuring the reliability of LLM outputs, particularly in complex reasoning tasks. Due to their parameterized nature, LLMs often generate responses that are either incomplete or lack logical coherence, especially when dealing with multi-step processes or requiring comprehensive understanding across various domains.
These issues stem from the isolated environment in which LLMs operate, where they are unable to cross-reference or validate their outputs against external standards or additional information.
AI agents play a pivotal role in mitigating these issues by introducing iterative feedback mechanisms and validation layers.
For instance, in the legal domain, an LLM might draft an initial version of a legal brief based on its training data. But this draft may overlook certain precedents or fail to logically structure the argument.
An AI agent can review this draft, ensuring it meets the required standards of completeness by cross-referencing with external legal databases, checking for logical consistency, and requesting additional information or clarification where necessary.
This iterative process enables the production of a more robust and reliable document that meets the stringent requirements of legal practice.
Overcoming Isolation Through Integration
One of the most profound limitations of LLMs is their inherent isolation from other systems and sources of knowledge.
LLMs, as designed, are closed systems that do not natively interact with external environments or databases. This isolation significantly limits their ability to adapt to new information or operate in real-time, making them less effective in applications requiring dynamic interaction or real-time decision-making.
AI agents overcome this isolation by acting as integrative platforms that connect LLMs with a broader ecosystem of data sources and computational tools. Through APIs and other integration frameworks, AI agents can access real-time data, collaborate with other AI systems, and even interface with physical devices.
For instance, in customer service applications, an LLM might generate standard responses based on pre-trained scripts. But these responses can be static and lack the personalization required for effective customer engagement.
An AI agent can enrich these interactions by integrating real-time data from customer profiles, previous interactions, and sentiment analysis tools, which helps generate responses that are not only contextually relevant but are also tailored to the specific needs of the customer.
This integration transforms the customer experience from a series of scripted interactions into a dynamic, personalized conversation.
Expanding Creativity and Problem-Solving
While LLMs are powerful tools for content generation, their creativity and problem-solving abilities are inherently limited by the data on which they were trained. These models are often unable to apply theoretical concepts to new or unforeseen challenges, as their problem-solving capabilities are bounded by their pre-existing knowledge and training parameters.
AI agents enhance the creative and problem-solving potential of LLMs by leveraging advanced reasoning techniques and a broader array of analytical tools. This capability allows AI agents to push beyond the limitations of LLMs, applying theoretical frameworks to practical problems in innovative ways.
For example, consider the issue of combating misinformation on social media platforms. An LLM might identify patterns of misinformation based on textual analysis, but it could struggle to develop a comprehensive strategy for mitigating the spread of false information.
An AI agent can take these insights, apply interdisciplinary theories from fields such as sociology, psychology, and network theory, and develop a robust, multi-faceted approach that includes real-time monitoring, user education, and automated moderation techniques.
This ability to synthesize diverse theoretical frameworks and apply them to real-world challenges exemplifies the enhanced problem-solving capabilities that AI agents bring to the table.
More Specific Examples
AI agents, with their ability to interact with diverse systems, access real-time data, and execute actions, address these limitations head-on, transforming LLMs from powerful yet passive language models into dynamic, real-world problem solvers. Let's look at some examples:
1. From Static Data to Dynamic Insights: Keeping LLMs in the Loop
The Problem: Imagine asking an LLM trained on pre-2023 medical research, "What are the latest breakthroughs in cancer treatment?" Its knowledge would be outdated.
The AI Agent Solution: An AI agent can connect the LLM to medical journals, research databases, and news feeds. Now, the LLM can provide up-to-date information on the latest clinical trials, treatment options, and research findings.
2. From Analysis to Action: Automating Tasks Based on LLM Insights
The Problem: An LLM monitoring social media for a brand might identify a surge in negative sentiment but can't do anything to address it.
The AI Agent Solution: An AI agent connected to the brand's social media accounts and equipped with pre-approved responses can automatically address concerns, answer questions, and even escalate complex issues to human representatives.
3. From First Draft to Polished Product: Ensuring Quality and Accuracy
The Problem: An LLM tasked with translating a technical manual might produce grammatically correct but technically inaccurate translations due to its lack of domain-specific knowledge.
The AI Agent Solution: An AI agent can integrate the LLM with specialized dictionaries, glossaries, and even connect it to subject-matter experts for real-time feedback, ensuring the final translation is both linguistically accurate and technically sound.
4. Breaking Down Barriers: Connecting LLMs to the Real World
The Problem: An LLM designed for smart home control might struggle to adapt to a user's changing routines and preferences.
The AI Agent Solution: An AI agent can connect the LLM to sensors, smart devices, and user calendars. By analyzing user behavior patterns, the LLM can learn to anticipate needs, adjust lighting and temperature settings automatically, and even suggest personalized music playlists based on the time of day and user activity.
5. From Imitation to Innovation: Expanding LLM Creativity
The Problem: An LLM tasked with composing music might create pieces that sound derivative or lack emotional depth, as it primarily relies on patterns found in its training data.
The AI Agent Solution: An AI agent can connect the LLM to biofeedback sensors that measure a composer's emotional responses to different musical elements. By incorporating this real-time feedback, the LLM can create music that is not only technically proficient but also emotionally evocative and original.
The integration of AI agents as LLM enhancers is not merely an incremental improvement—it represents a fundamental expansion of what artificial intelligence can achieve. By addressing the limitations inherent in traditional LLMs, such as their static knowledge base, limited decision-making autonomy, and isolated operational environment, AI agents enable these models to operate at their full potential.
As AI technology continues to evolve, the role of AI agents in enhancing LLMs will become increasingly critical, not only in expanding the capabilities of these models but also in redefining the boundaries of artificial intelligence itself. This fusion is paving the way for the next generation of AI systems, capable of autonomous reasoning, real-time adaptation, and innovative problem-solving in an ever-changing world.
Chapter 6: Architectural Design for Integrating AI Agents with LLMs
The integration of AI agents with LLMs hinges on the architectural design, which is crucial for enhancing decision-making, adaptability, and scalability. The architecture should be carefully crafted to enable seamless interaction between the AI agents and LLMs, ensuring that each component functions optimally.
A modular architecture, where the AI agent acts as an orchestrator, directing the LLM's capabilities, is one approach that supports dynamic task management. This design leverages the LLM’s strengths in natural language processing while allowing the AI agent to manage more complex tasks, such as multi-step reasoning or contextual decision-making in real-time environments.
Alternatively, a hybrid model, combining LLMs with specialized, fine-tuned models, offers flexibility by enabling the AI agent to delegate tasks to the most appropriate model. This approach optimizes performance and enhances efficiency across a broad range of applications, making it particularly effective in diverse and variable operational contexts (Liang et al., 2021).

Training Methodologies and Best Practices
Training AI agents integrated with LLMs requires a methodical approach that balances generalization with task-specific optimization.
Transfer learning is a key technique here, allowing an LLM that has been pre-trained on a large, diverse corpus to be fine-tuned on domain-specific data relevant to the AI agent’s tasks. This method retains the broad knowledge base of the LLM while enabling it to specialize in particular applications, enhancing overall system effectiveness.
Also, reinforcement learning (RL) plays a critical role, especially in scenarios where the AI agent must adapt to changing environments. Through interaction with its environment, the AI agent can continuously improve its decision-making processes, becoming more adept at handling novel challenges.
To ensure reliable performance across different scenarios, rigorous evaluation metrics are essential. These should include both standard benchmarks and task-specific criteria, ensuring that the system's training is robust and comprehensive (Silver et al., 2016).
Introduction to Fine-Tuning a Large Language Model (LLM) and Reinforcement Learning Concepts
This code demonstrates a variety of techniques involving machine learning and natural language processing (NLP), focusing on fine-tuning large language models (LLMs) for specific tasks and implementing reinforcement learning (RL) agents. The code spans several key areas:
Fine-tuning an LLM: Leveraging pre-trained models like BERT for tasks such as sentiment analysis, using the Hugging Face
transformerslibrary. This involves tokenizing datasets and using training arguments to guide the fine-tuning process.Reinforcement Learning (RL): Introducing the basics of RL with a simple Q-learning agent, where an agent learns through trial and error by interacting with an environment and updating its knowledge via Q-tables.
Reward Modeling with OpenAI API: A conceptual method for using OpenAI’s API to dynamically provide reward signals to an RL agent, allowing a language model to evaluate actions.
Model Evaluation and Logging: Using libraries like
scikit-learnto evaluate model performance through accuracy and F1 scores, and PyTorch’sSummaryWriterfor visualizing the training progress.Advanced RL Concepts: Implementing more advanced concepts such as policy gradient networks, curriculum learning, and early stopping to enhance model training efficiency.
This holistic approach covers both supervised learning, with sentiment analysis fine-tuning, and reinforcement learning, offering insights into how modern AI systems are built, evaluated, and optimized.
Code Example
Step 1: Importing the Necessary Libraries
Before diving into model fine-tuning and agent implementation, it's essential to set up the necessary libraries and modules. This code includes imports from popular libraries such as Hugging Face's transformers and PyTorch for handling neural networks, scikit-learn for evaluating model performance, and some general-purpose modules like random and pickle.
Hugging Face Libraries: These allow you to use and fine-tune pre-trained models and tokenizers from the Model Hub.
PyTorch: This is the core deep learning framework used for operations, including neural network layers and optimizers.
scikit-learn: Provides metrics like accuracy and F1-score to evaluate model performance.
OpenAI API: Accessing OpenAI’s language models for various tasks such as reward modeling.
TensorBoard: Used for visualizing training progress.
Here's the code for importing the necessary libraries:
# Import the random module for random number generation.
import random
# Import necessary modules from transformers library.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Import load_dataset for loading datasets.
from datasets import load_dataset
# Import metrics for evaluating model performance.
from sklearn.metrics import accuracy_score, f1_score
# Import SummaryWriter for logging training progress.
from torch.utils.tensorboard import SummaryWriter
# Import pickle for saving and loading trained models.
import pickle
# Import openai for using OpenAI's API (requires an API key).
import openai
# Import PyTorch for deep learning operations.
import torch
# Import neural network module from PyTorch.
import torch.nn as nn
# Import optimizer module from PyTorch (not used directly in this example).
import torch.optim as optim
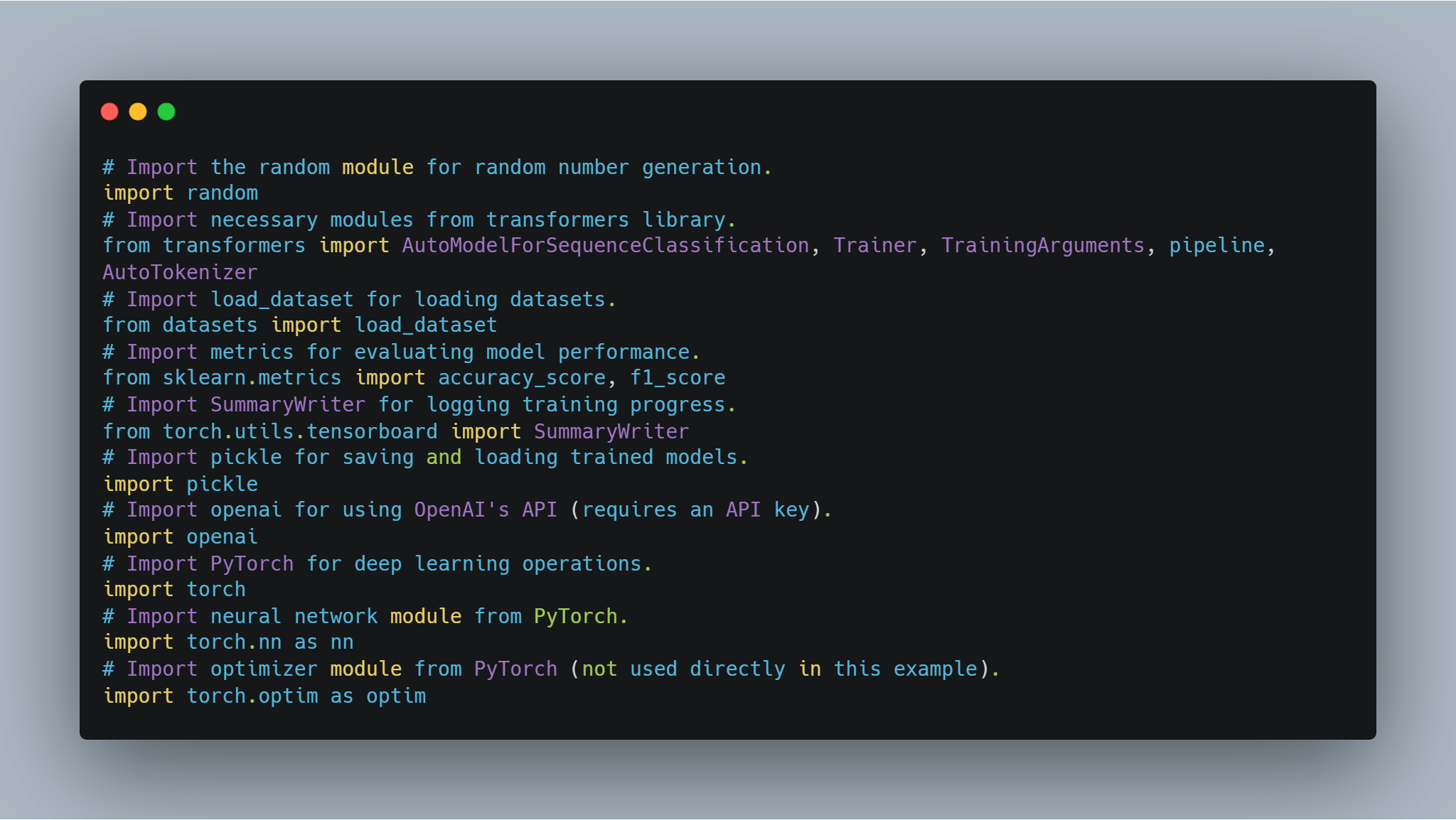
Each of these imports plays a crucial role in different parts of the code, from model training and evaluation to logging results and interacting with external APIs.
Step 2: Fine-tuning a Language Model for Sentiment Analysis
Fine-tuning a pre-trained model for a specific task such as sentiment analysis involves loading a pre-trained model, adjusting it for the number of output labels (positive/negative in this case), and using a suitable dataset.
In this example, we use the AutoModelForSequenceClassification from the transformers library, with the IMDB dataset. This pre-trained model can be fine-tuned on a smaller portion of the dataset to save computation time. The model is then trained using a custom set of training arguments, which includes the number of epochs and batch size.
Below is the code for loading and fine-tuning the model:
# Specify the pre-trained model name from Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Load the pre-trained model with specified number of output classes.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Load a tokenizer for the model.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load the IMDB dataset from Hugging Face Datasets, using only 10% for training.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenize the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Map the dataset to tokenized inputs
tokenized_dataset = dataset.map(tokenize_function, batched=True)
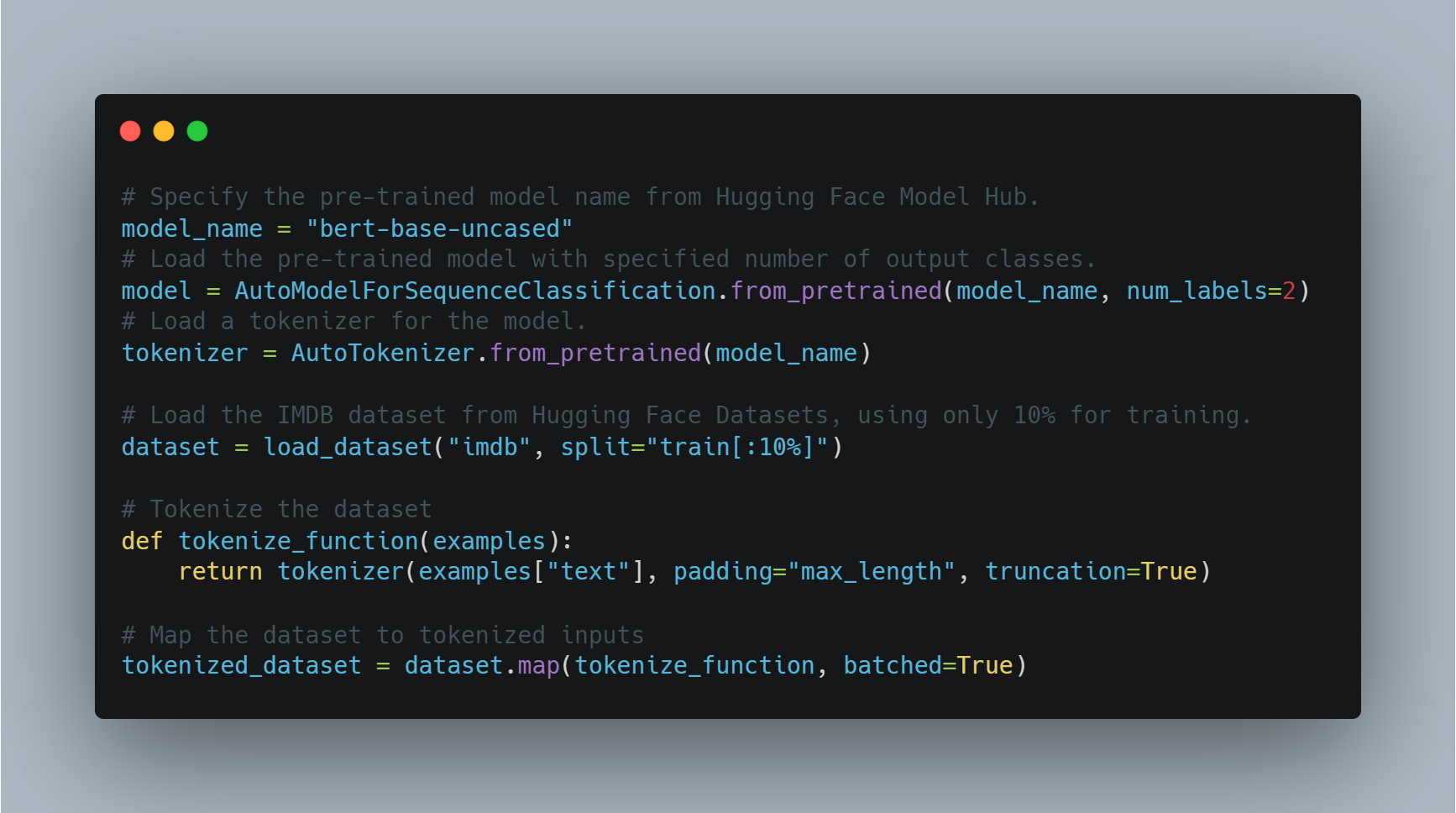
Here, the model is loaded using a BERT-based architecture and the dataset is prepared for training. Next, we define the training arguments and initialize the Trainer.
# Define training arguments.
training_args = TrainingArguments(
output_dir="./results", # Specify the output directory for saving the model.
num_train_epochs=3, # Set the number of training epochs.
per_device_train_batch_size=8, # Set the batch size per device.
logging_dir='./logs', # Directory for storing logs.
logging_steps=10 # Log every 10 steps.
)
# Initialize the Trainer with the model, training arguments, and dataset.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Start the training process.
trainer.train()
# Save the fine-tuned model.
model.save_pretrained("./fine_tuned_sentiment_model")
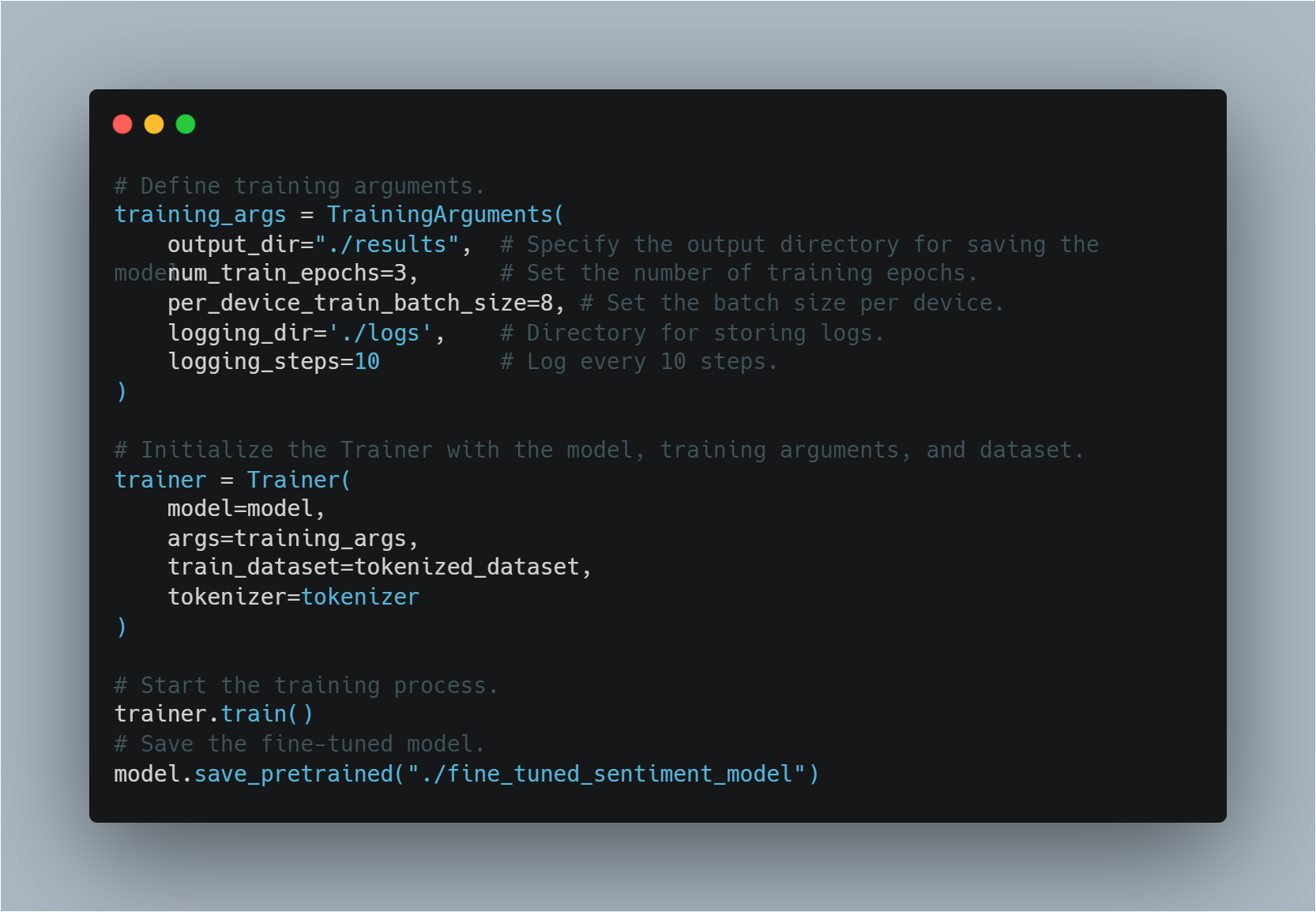
Step 3: Implementing a Simple Q-Learning Agent
Q-learning is a reinforcement learning technique where an agent learns to take actions in a way that maximizes the cumulative reward.
In this example, we define a basic Q-learning agent that stores state-action pairs in a Q-table. The agent can either explore randomly or exploit the best known action based on the Q-table. The Q-table is updated after each action using a learning rate and a discount factor to weigh future rewards.
Below is the code that implements this Q-learning agent:
# Define the Q-learning agent class.
class QLearningAgent:
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialize the Q-table.
self.q_table = {}
# Store the possible actions.
self.actions = actions
# Set the exploration rate.
self.epsilon = epsilon
# Set the learning rate.
self.alpha = alpha
# Set the discount factor.
self.gamma = gamma
# Define the get_action method to select an action based on the current state.
def get_action(self, state):
if random.uniform(0, 1) < self.epsilon:
# Explore randomly.
return random.choice(self.actions)
else:
# Exploit the best action.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
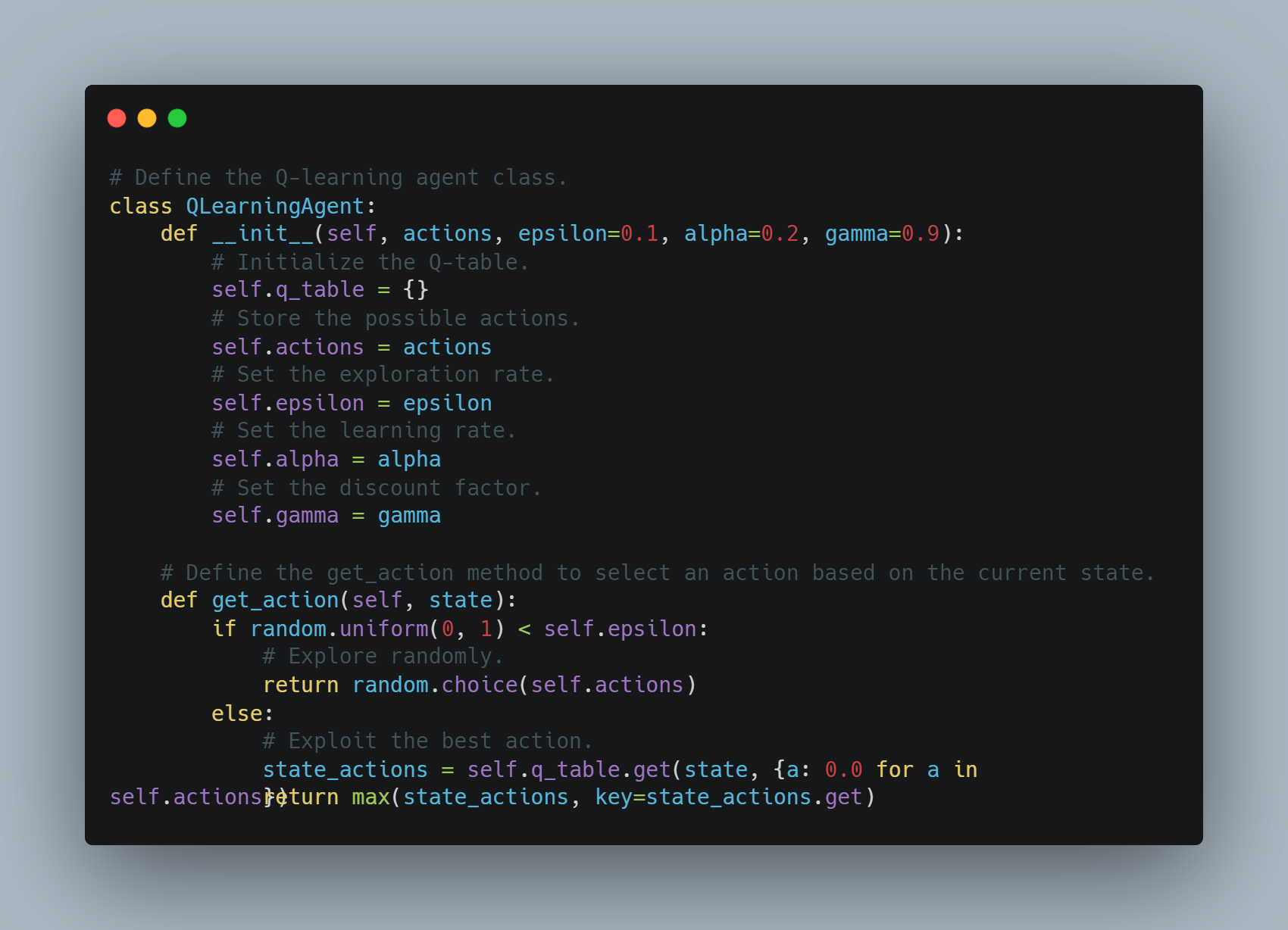
The agent selects actions based on either exploration or exploitation and updates the Q-values after each step.
# Define the update_q_table method to update the Q-table.
def update_q_table(self, state, action, reward, next_state):
if state not in self.q_table:
self.q_table[state] = {a: 0.0 for a in self.actions}
if next_state not in self.q_table:
self.q_table[next_state] = {a: 0.0 for a in self.actions}
old_value = self.q_table[state][action]
next_max = max(self.q_table[next_state].values())
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
self.q_table[state][action] = new_value
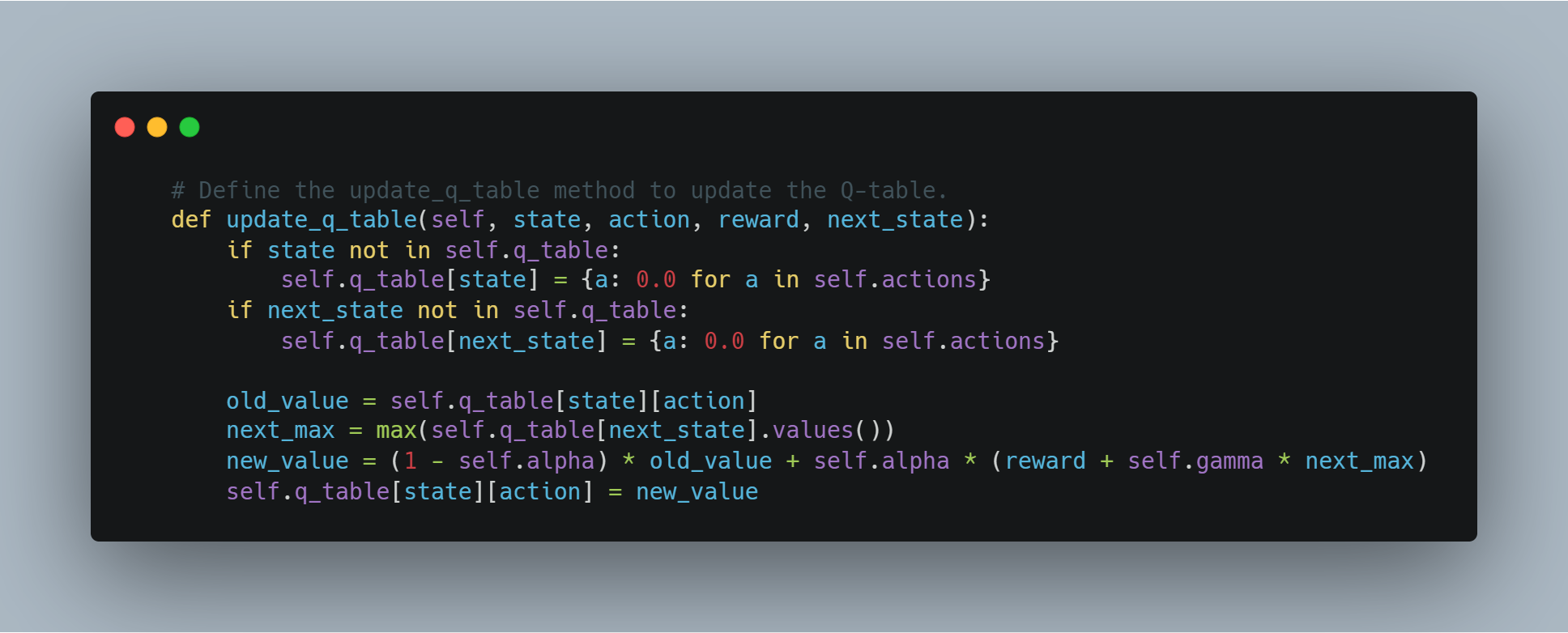
Step 4: Using OpenAI's API for Reward Modeling
In some scenarios, instead of defining a manual reward function, we can use a powerful language model like OpenAI’s GPT to evaluate the quality of actions taken by the agent.
In this example, the get_reward function sends a state, action, and next state to OpenAI’s API to receive a reward score, allowing us to leverage large language models to understand complex reward structures.
# Define the get_reward function to get a reward signal from OpenAI's API.
def get_reward(state, action, next_state):
openai.api_key = "your-openai-api-key" # Replace with your actual OpenAI API key.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=1
)
return int(response.choices[0].text.strip())
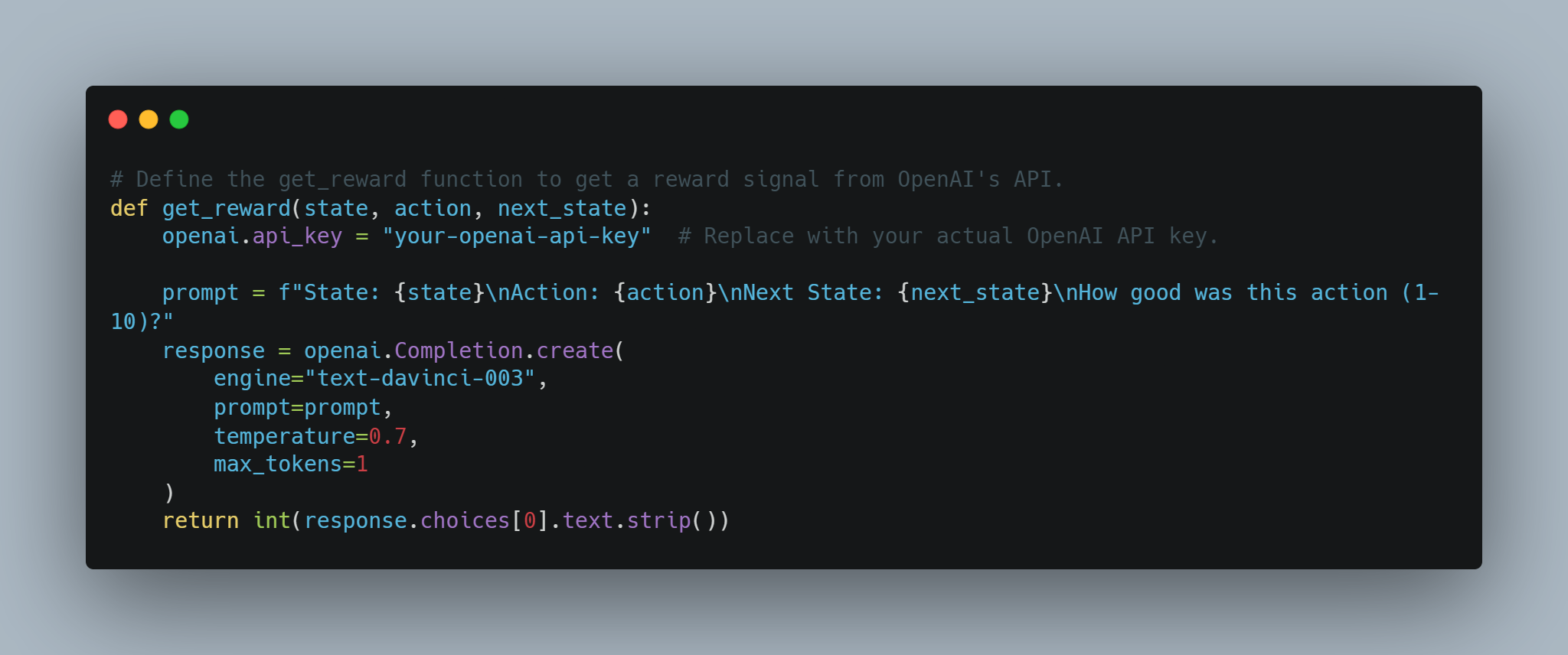
This allows for a conceptual approach where the reward system is determined dynamically using OpenAI's API, which could be useful for complex tasks where rewards are hard to define.
Step 5: Evaluating Model Performance
Once a machine learning model is trained, it’s essential to evaluate its performance using standard metrics like accuracy and F1-score.
This section calculates both using true and predicted labels. Accuracy provides an overall measure of correctness, while the F1-score balances precision and recall, especially useful in imbalanced datasets.
Here is the code for evaluating the model's performance:
# Define the true labels for evaluation.
true_labels = [0, 1, 1, 0, 1]
# Define the predicted labels for evaluation.
predicted_labels = [0, 0, 1, 0, 1]
# Calculate the accuracy score.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calculate the F1-score.
f1 = f1_score(true_labels, predicted_labels)
# Print the accuracy score.
print(f"Accuracy: {accuracy:.2f}")
# Print the F1-score.
print(f"F1-Score: {f1:.2f}")
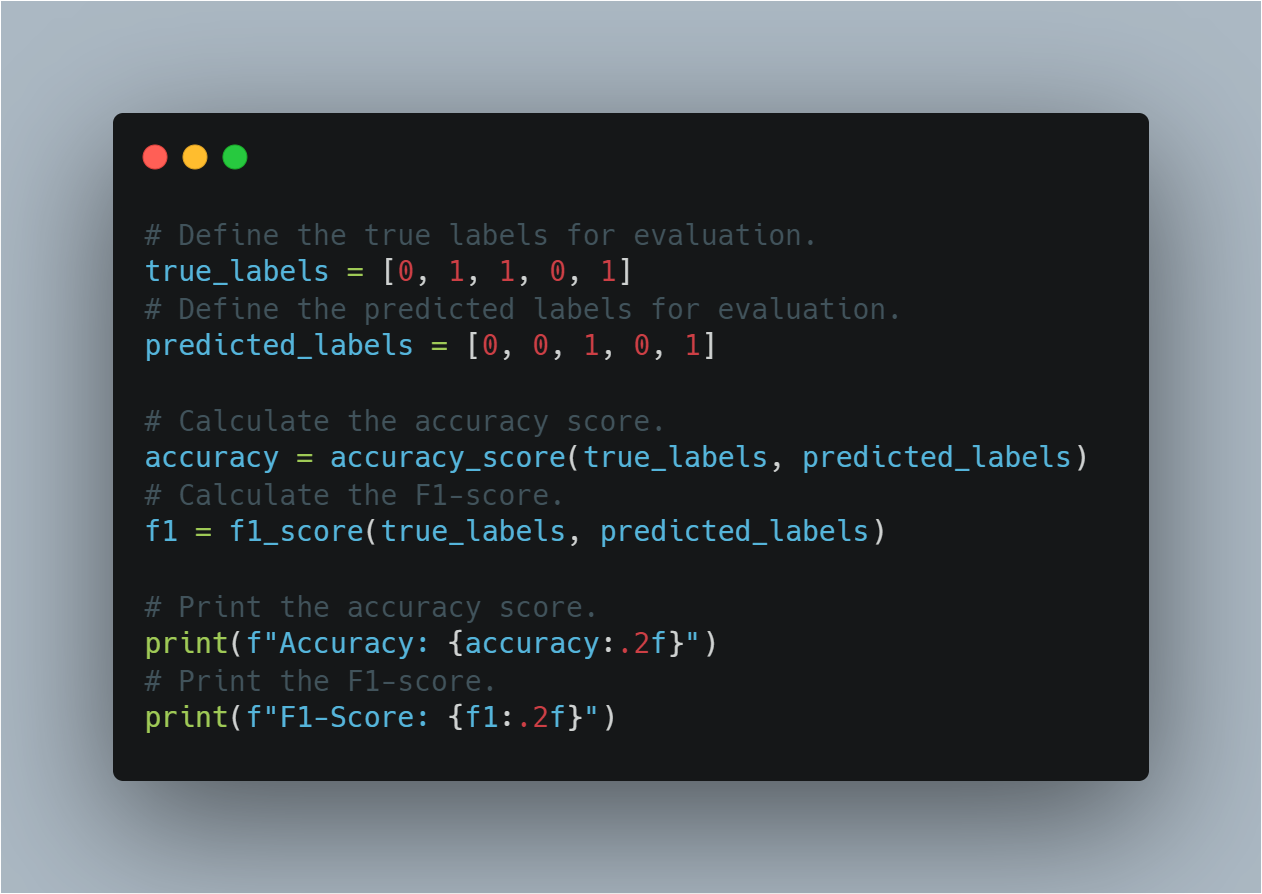
This section helps in assessing how well the model has generalized to unseen data by using well-established evaluation metrics.
Step 6: Basic Policy Gradient Agent (Using PyTorch)
Policy gradient methods in reinforcement learning directly optimize the policy by maximizing the expected reward.
This section demonstrates a simple implementation of a policy network using PyTorch, which can be used for decision-making in RL. The policy network uses a linear layer to output probabilities for different actions, and softmax is applied to ensure these outputs form a valid probability distribution.
Here is the conceptual code for defining a basic policy gradient agent:
# Define the policy network class.
class PolicyNetwork(nn.Module):
# Initialize the policy network.
def __init__(self, input_size, output_size):
super(PolicyNetwork, self).__init__()
# Define a linear layer.
self.linear = nn.Linear(input_size, output_size)
# Define the forward pass of the network.
def forward(self, x):
# Apply softmax to the output of the linear layer.
return torch.softmax(self.linear(x), dim=1)
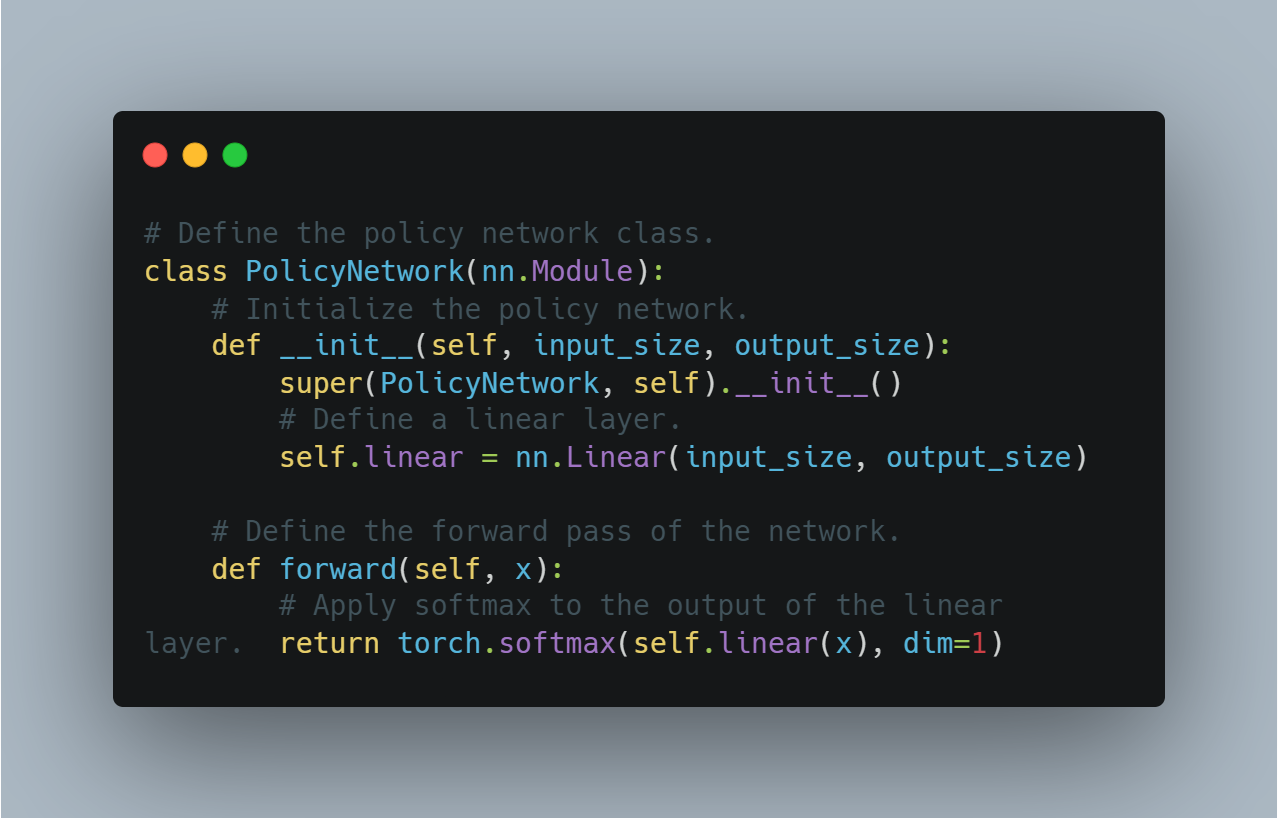
This serves as a foundational step for implementing more advanced reinforcement learning algorithms that use policy optimization.
Step 7: Visualizing Training Progress with TensorBoard
Visualizing training metrics, such as loss and accuracy, is vital for understanding how a model’s performance evolves over time. TensorBoard, a popular tool for this, can be used to log metrics and visualize them in real time.
In this section, we create a SummaryWriter instance and log random values to simulate the process of tracking loss and accuracy during training.
Here's how you can log and visualize training progress using TensorBoard:
# Create a SummaryWriter instance.
writer = SummaryWriter()
# Example training loop for TensorBoard visualization:
num_epochs = 10 # Define the number of epochs.
for epoch in range(num_epochs):
# Simulate random loss and accuracy values.
loss = random.random()
accuracy = random.random()
# Log the loss and accuracy to TensorBoard.
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", accuracy, epoch)
# Close the SummaryWriter.
writer.close()
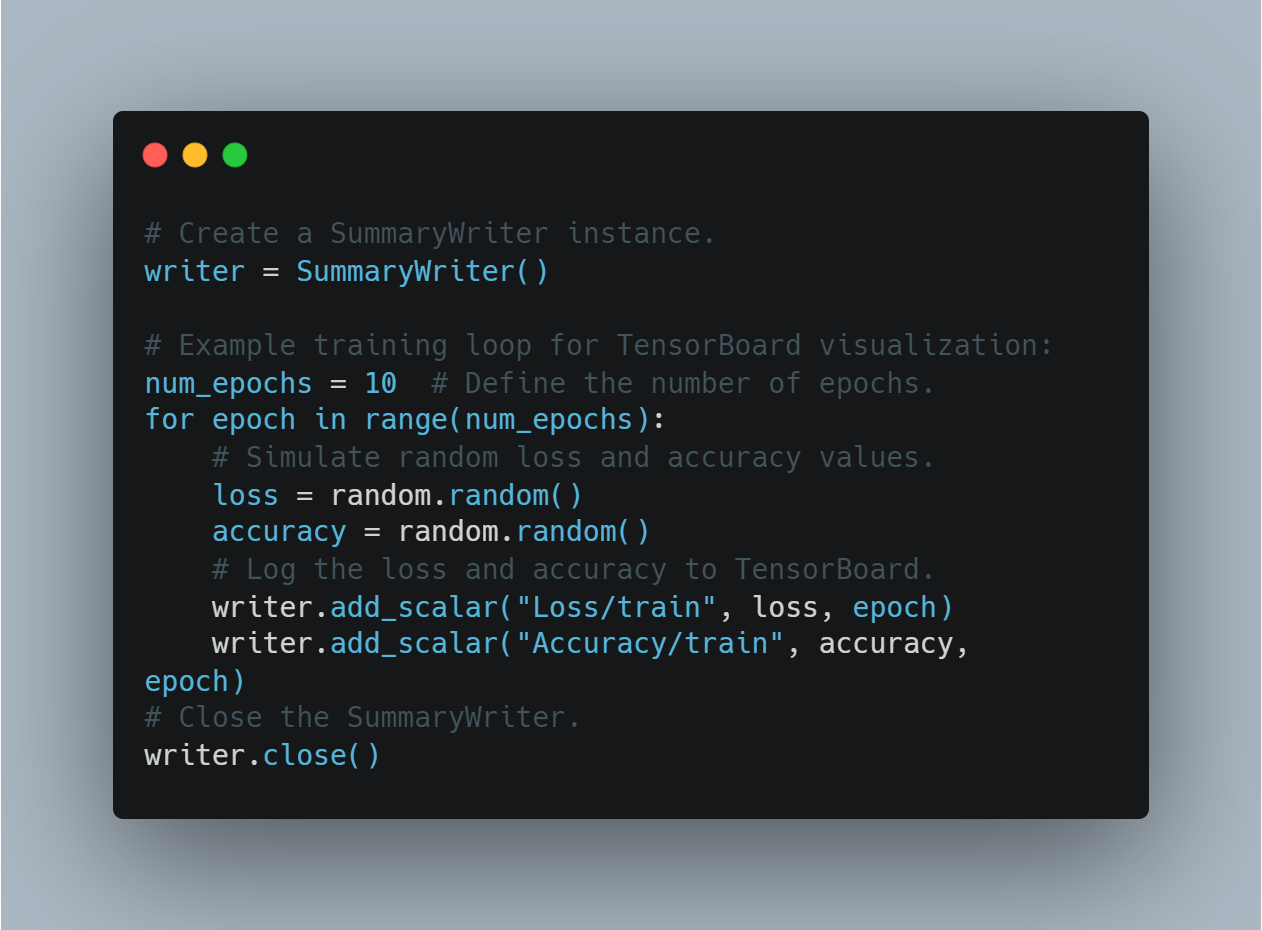
This allows users to monitor model training and make real-time adjustments based on visual feedback.
Step 8: Saving and Loading Trained Agent Checkpoints
After training an agent, it is crucial to save its learned state (for example, Q-values or model weights) so that it can be reused or evaluated later.
This section shows how to save a trained agent using Python's pickle module and how to reload it from disk.
Here is the code for saving and loading a trained Q-learning agent:
# Create an instance of the Q-learning agent.
agent = QLearningAgent(actions=["up", "down", "left", "right"])
# Train the agent (not shown here).
# Saving the agent.
with open("trained_agent.pkl", "wb") as f:
pickle.dump(agent, f)
# Loading the agent.
with open("trained_agent.pkl", "rb") as f:
loaded_agent = pickle.load(f)
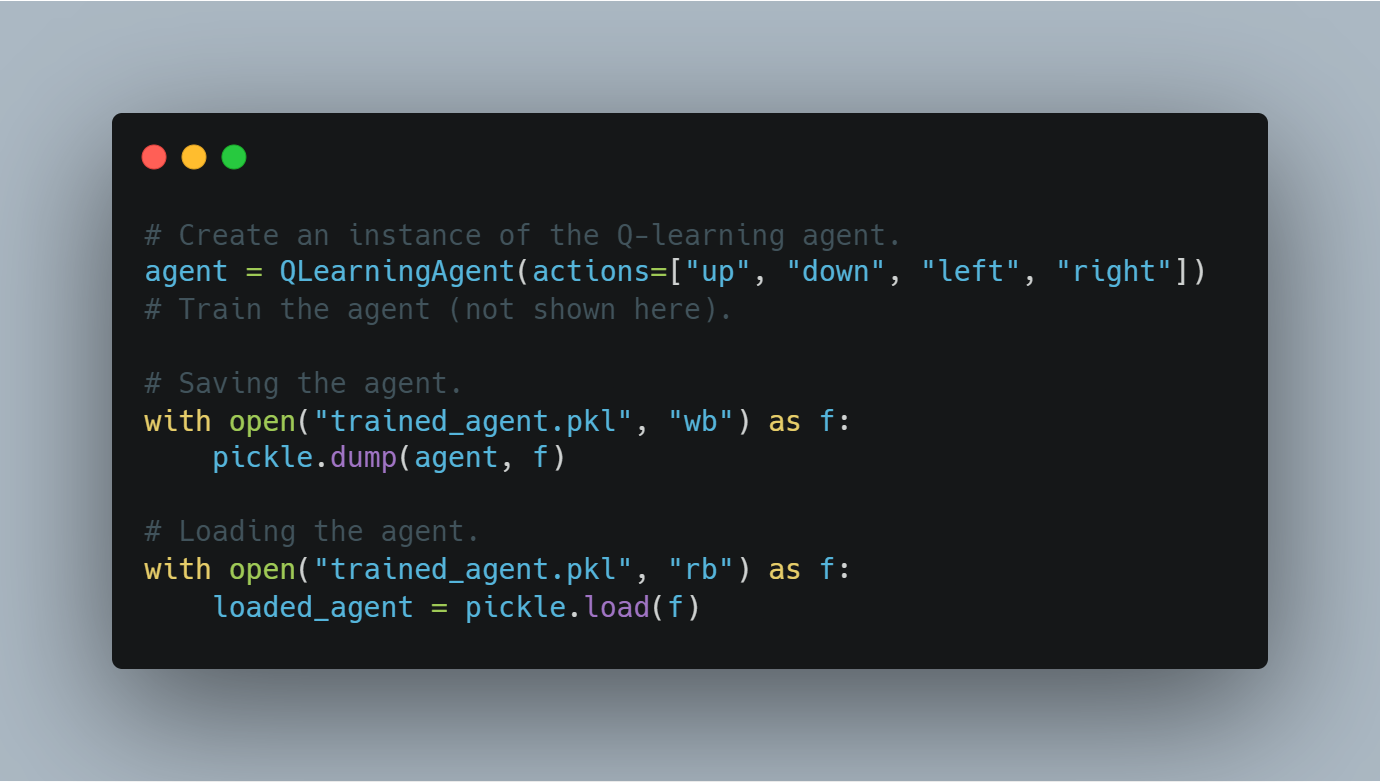
This process of checkpointing ensures that training progress is not lost and models can be reused in future experiments.
Step 9: Curriculum Learning
Curriculum learning involves gradually increasing the difficulty of tasks presented to the model, starting with easier examples and moving toward more challenging ones. This can help improve model performance and stability during training.
Here's an example of using curriculum learning in a training loop:
# Set the initial task difficulty.
initial_task_difficulty = 0.1
# Example training loop with curriculum learning:
for epoch in range(num_epochs):
# Gradually increase the task difficulty.
task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# Generate training data with adjusted difficulty.
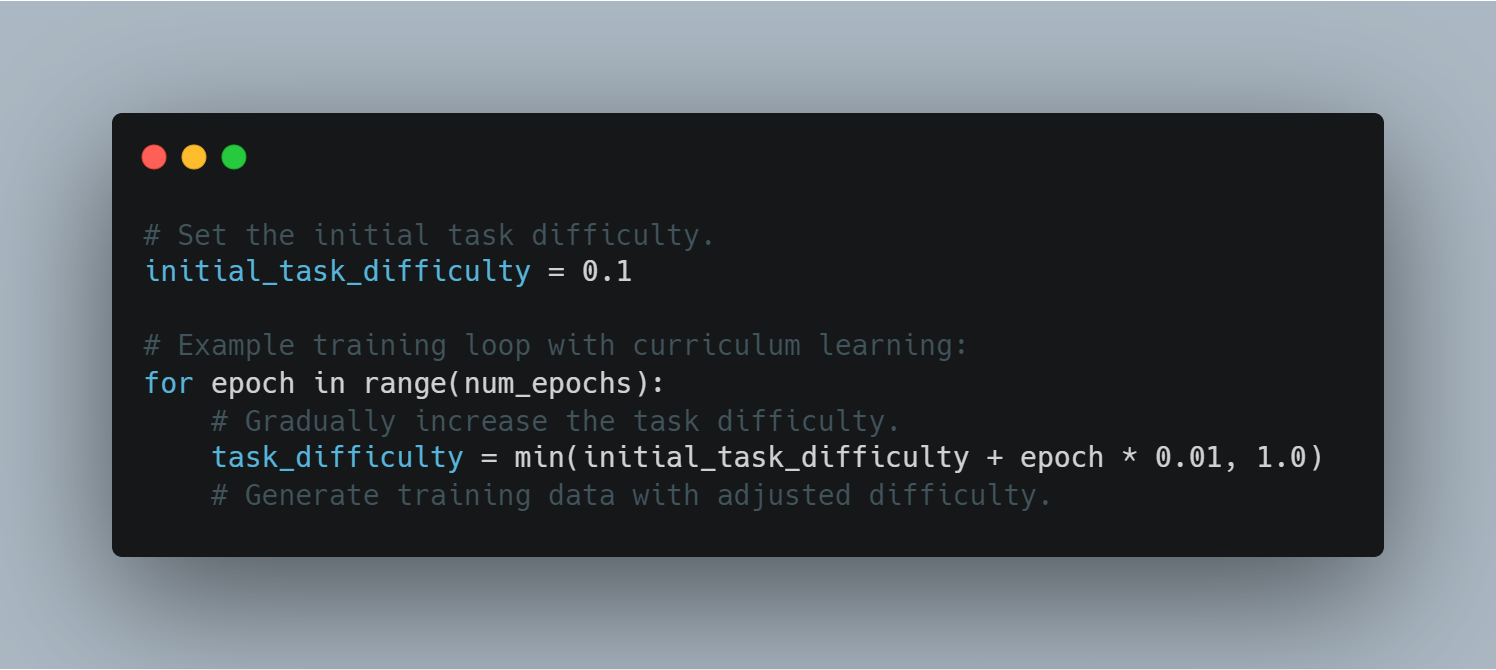
By controlling task difficulty, the agent can progressively handle more complex challenges, leading to improved learning efficiency.
Step 10: Implementing Early Stopping
Early stopping is a technique to prevent overfitting during training by halting the process if the validation loss does not improve after a certain number of epochs (patience).
This section shows how to implement early stopping in a training loop, using validation loss as the key indicator.
Here's the code for implementing early stopping:
# Initialize the best validation loss to infinity.
best_validation_loss = float("inf")
# Set the patience value (number of epochs without improvement).
patience = 5
# Initialize the counter for epochs without improvement.
epochs_without_improvement = 0
# Example training loop with early stopping:
for epoch in range(num_epochs):
# Simulate random validation loss.
validation_loss = random.random()
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
epochs_without_improvement = 0
else:
epochs_without_improvement += 1
if epochs_without_improvement >= patience:
print("Early stopping triggered!")
break
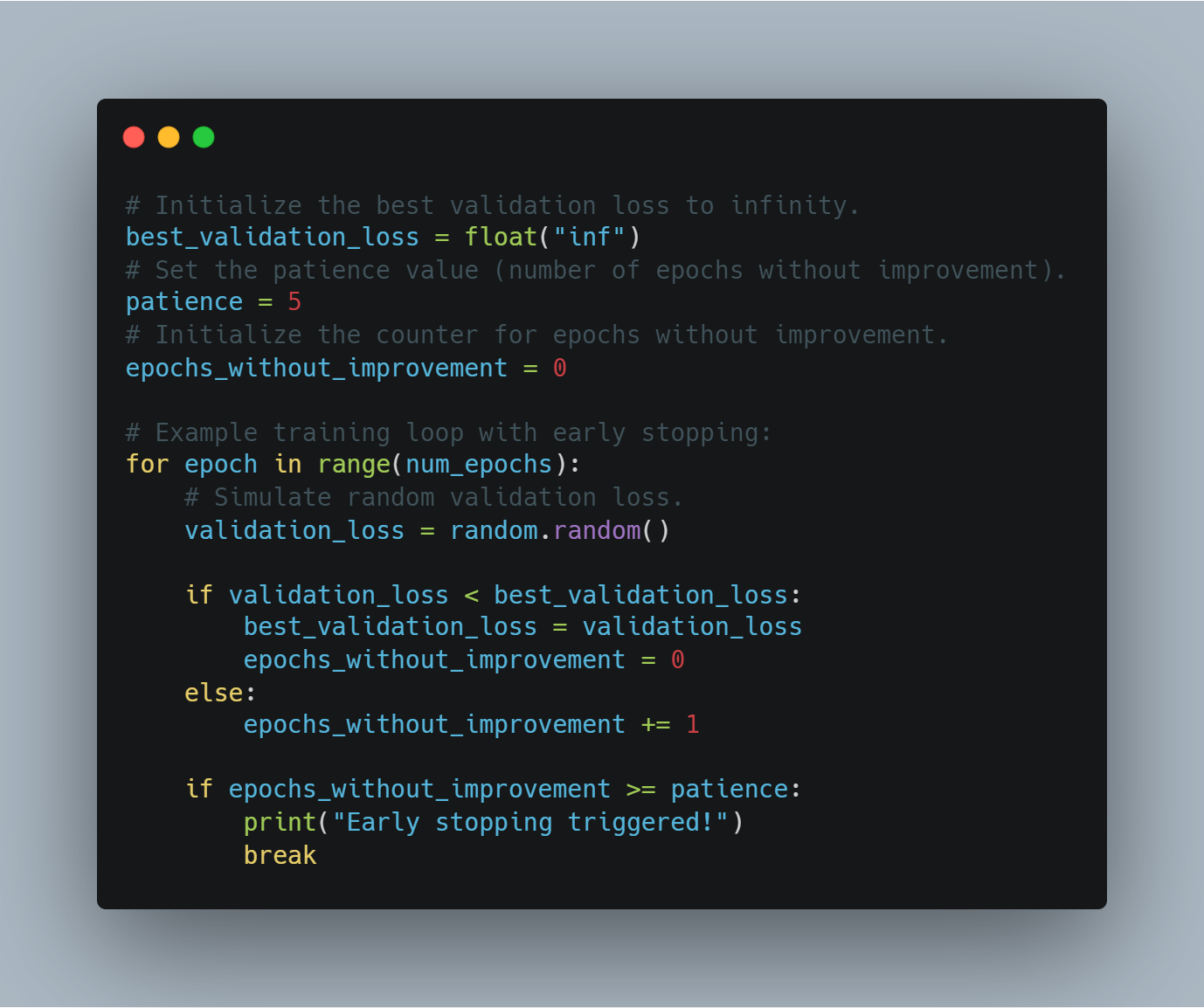
Early stopping improves model generalization by preventing unnecessary training once the model starts overfitting.
Step 11: Using a Pre-trained LLM for Zero-Shot Task Transfer
In zero-shot task transfer, a pre-trained model is applied to a task it wasn’t specifically fine-tuned for.
Using Hugging Face’s pipeline, this section demonstrates how to apply a pre-trained BART model for summarization without additional training, illustrating the concept of transfer learning.
Here’s the code for using a pre-trained LLM for summarization:
# Load a pre-trained summarization pipeline.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Define the text to summarize.
text = "This is an example text about AI agents and LLMs."
# Generate the summary.
summary = summarizer(text)[0]["summary_text"]
# Print the summary.
print(f"Summary: {summary}")
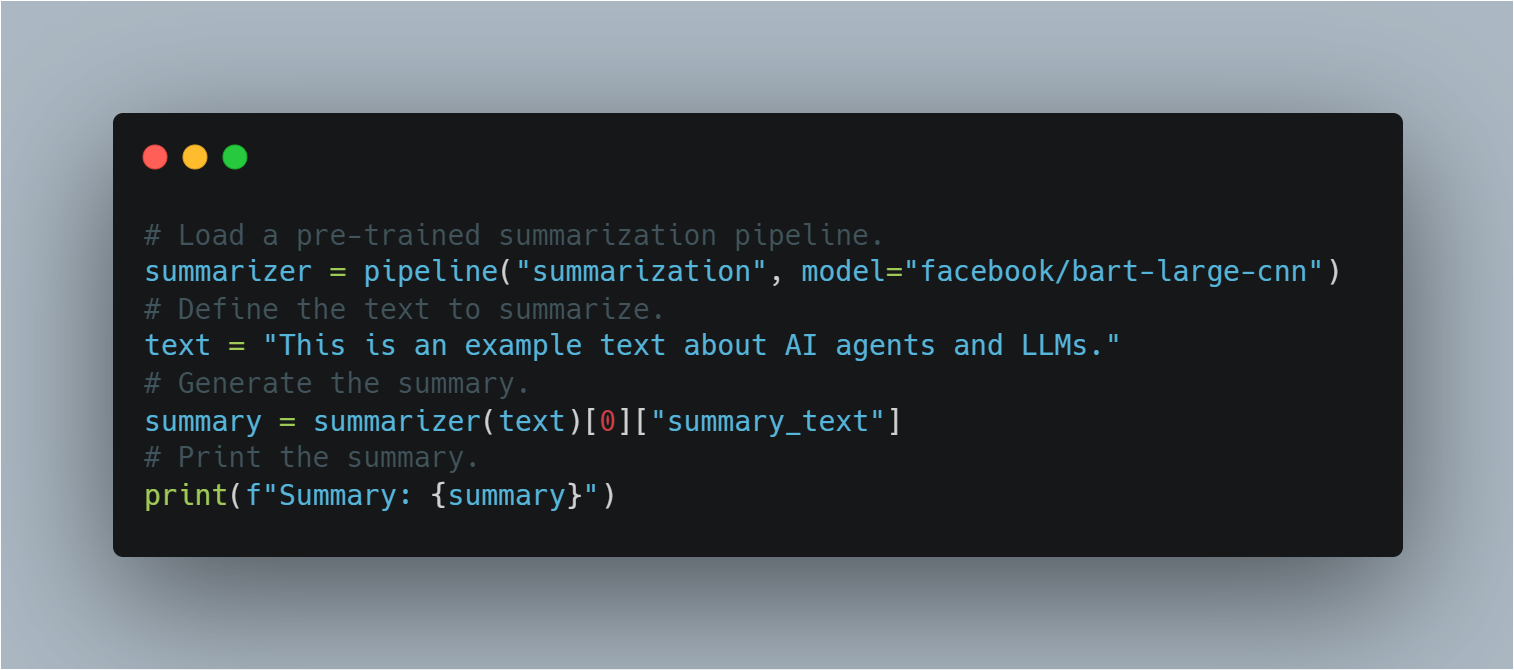
This illustrates the flexibility of LLMs in performing diverse tasks without the need for further training, leveraging their pre-existing knowledge.
The Full Code Example
# Import the random module for random number generation.
import random
# Import necessary modules from transformers library.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments, pipeline, AutoTokenizer
# Import load_dataset for loading datasets.
from datasets import load_dataset
# Import metrics for evaluating model performance.
from sklearn.metrics import accuracy_score, f1_score
# Import SummaryWriter for logging training progress.
from torch.utils.tensorboard import SummaryWriter
# Import pickle for saving and loading trained models.
import pickle
# Import openai for using OpenAI's API (requires an API key).
import openai
# Import PyTorch for deep learning operations.
import torch
# Import neural network module from PyTorch.
import torch.nn as nn
# Import optimizer module from PyTorch (not used directly in this example).
import torch.optim as optim
# --------------------------------------------------
# 1. Fine-tuning an LLM for Sentiment Analysis
# --------------------------------------------------
# Specify the pre-trained model name from Hugging Face Model Hub.
model_name = "bert-base-uncased"
# Load the pre-trained model with specified number of output classes.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# Load a tokenizer for the model.
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load the IMDB dataset from Hugging Face Datasets, using only 10% for training.
dataset = load_dataset("imdb", split="train[:10%]")
# Tokenize the dataset
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# Map the dataset to tokenized inputs
tokenized_dataset = dataset.map(tokenize_function, batched=True)
# Define training arguments.
training_args = TrainingArguments(
output_dir="./results", # Specify the output directory for saving the model.
num_train_epochs=3, # Set the number of training epochs.
per_device_train_batch_size=8, # Set the batch size per device.
logging_dir='./logs', # Directory for storing logs.
logging_steps=10 # Log every 10 steps.
)
# Initialize the Trainer with the model, training arguments, and dataset.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer
)
# Start the training process.
trainer.train()
# Save the fine-tuned model.
model.save_pretrained("./fine_tuned_sentiment_model")
# --------------------------------------------------
# 2. Implementing a Simple Q-Learning Agent
# --------------------------------------------------
# Define the Q-learning agent class.
class QLearningAgent:
# Initialize the agent with actions, epsilon (exploration rate), alpha (learning rate), and gamma (discount factor).
def __init__(self, actions, epsilon=0.1, alpha=0.2, gamma=0.9):
# Initialize the Q-table.
self.q_table = {}
# Store the possible actions.
self.actions = actions
# Set the exploration rate.
self.epsilon = epsilon
# Set the learning rate.
self.alpha = alpha
# Set the discount factor.
self.gamma = gamma
# Define the get_action method to select an action based on the current state.
def get_action(self, state):
# Explore randomly with probability epsilon.
if random.uniform(0, 1) < self.epsilon:
# Return a random action.
return random.choice(self.actions)
else:
# Exploit the best action based on the Q-table.
state_actions = self.q_table.get(state, {a: 0.0 for a in self.actions})
return max(state_actions, key=state_actions.get)
# Define the update_q_table method to update the Q-table after taking an action.
def update_q_table(self, state, action, reward, next_state):
# If the state is not in the Q-table, add it.
if state not in self.q_table:
# Initialize the Q-values for the new state.
self.q_table[state] = {a: 0.0 for a in self.actions}
# If the next state is not in the Q-table, add it.
if next_state not in self.q_table:
# Initialize the Q-values for the new next state.
self.q_table[next_state] = {a: 0.0 for a in self.actions}
# Get the old Q-value for the state-action pair.
old_value = self.q_table[state][action]
# Get the maximum Q-value for the next state.
next_max = max(self.q_table[next_state].values())
# Calculate the updated Q-value.
new_value = (1 - self.alpha) * old_value + self.alpha * (reward + self.gamma * next_max)
# Update the Q-table with the new Q-value.
self.q_table[state][action] = new_value
# --------------------------------------------------
# 3. Using OpenAI's API for Reward Modeling (Conceptual)
# --------------------------------------------------
# Define the get_reward function to get a reward signal from OpenAI's API.
def get_reward(state, action, next_state):
# Ensure OpenAI API key is set correctly.
openai.api_key = "your-openai-api-key" # Replace with your actual OpenAI API key.
# Construct the prompt for the API call.
prompt = f"State: {state}\nAction: {action}\nNext State: {next_state}\nHow good was this action (1-10)?"
# Make the API call to OpenAI's Completion endpoint.
response = openai.Completion.create(
engine="text-davinci-003", # Specify the engine to use.
prompt=prompt, # Pass the constructed prompt.
temperature=0.7, # Set the temperature parameter.
max_tokens=1 # Set the maximum number of tokens to generate.
)
# Extract and return the reward value from the API response.
return int(response.choices[0].text.strip())
# --------------------------------------------------
# 4. Evaluating Model Performance
# --------------------------------------------------
# Define the true labels for evaluation.
true_labels = [0, 1, 1, 0, 1]
# Define the predicted labels for evaluation.
predicted_labels = [0, 0, 1, 0, 1]
# Calculate the accuracy score.
accuracy = accuracy_score(true_labels, predicted_labels)
# Calculate the F1-score.
f1 = f1_score(true_labels, predicted_labels)
# Print the accuracy score.
print(f"Accuracy: {accuracy:.2f}")
# Print the F1-score.
print(f"F1-Score: {f1:.2f}")
# --------------------------------------------------
# 5. Basic Policy Gradient Agent (using PyTorch) - Conceptual
# --------------------------------------------------
# Define the policy network class.
class PolicyNetwork(nn.Module):
# Initialize the policy network.
def __init__(self, input_size, output_size):
# Initialize the parent class.
super(PolicyNetwork, self).__init__()
# Define a linear layer.
self.linear = nn.Linear(input_size, output_size)
# Define the forward pass of the network.
def forward(self, x):
# Apply softmax to the output of the linear layer.
return torch.softmax(self.linear(x), dim=1)
# --------------------------------------------------
# 6. Visualizing Training Progress with TensorBoard
# --------------------------------------------------
# Create a SummaryWriter instance.
writer = SummaryWriter()
# Example training loop for TensorBoard visualization:
# num_epochs = 10 # Define the number of epochs.
# for epoch in range(num_epochs):
# # ... (Your training loop here)
# loss = random.random() # Example: Random loss value.
# accuracy = random.random() # Example: Random accuracy value.
# # Log the loss to TensorBoard.
# writer.add_scalar("Loss/train", loss, epoch)
# # Log the accuracy to TensorBoard.
# writer.add_scalar("Accuracy/train", accuracy, epoch)
# # ... (Log other metrics)
# # Close the SummaryWriter.
# writer.close()
# --------------------------------------------------
# 7. Saving and Loading Trained Agent Checkpoints
# --------------------------------------------------
# Example:
# Create an instance of the Q-learning agent.
# agent = QLearningAgent(actions=["up", "down", "left", "right"])
# # ... (Train your agent)
# # Saving the agent
# # Open a file in binary write mode.
# with open("trained_agent.pkl", "wb") as f:
# # Save the agent to the file.
# pickle.dump(agent, f)
# # Loading the agent
# # Open the file in binary read mode.
# with open("trained_agent.pkl", "rb") as f:
# # Load the agent from the file.
# loaded_agent = pickle.load(f)
# --------------------------------------------------
# 8. Curriculum Learning
# --------------------------------------------------
# Set the initial task difficulty.
initial_task_difficulty = 0.1
# Example training loop with curriculum learning:
# for epoch in range(num_epochs):
# # Gradually increase the task difficulty.
# task_difficulty = min(initial_task_difficulty + epoch * 0.01, 1.0)
# # ... (Generate training data with adjusted difficulty)
# --------------------------------------------------
# 9. Implementing Early Stopping
# --------------------------------------------------
# Initialize the best validation loss to infinity.
best_validation_loss = float("inf")
# Set the patience value (number of epochs without improvement).
patience = 5
# Initialize the counter for epochs without improvement.
epochs_without_improvement = 0
# Example training loop with early stopping:
# for epoch in range(num_epochs):
# # ... (Training and validation steps)
# # Calculate the validation loss.
# validation_loss = random.random() # Example: Random validation loss.
# # If the validation loss improves.
# if validation_loss < best_validation_loss:
# # Update the best validation loss.
# best_validation_loss = validation_loss
# # Reset the counter.
# epochs_without_improvement = 0
# else:
# # Increment the counter.
# epochs_without_improvement += 1
# # If no improvement for 'patience' epochs.
# if epochs_without_improvement >= patience:
# # Print a message.
# print("Early stopping triggered!")
# # Stop the training.
# break
# --------------------------------------------------
# 10. Using a Pre-trained LLM for Zero-Shot Task Transfer
# --------------------------------------------------
# Load a pre-trained summarization pipeline.
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
# Define the text to summarize.
text = "This is an example text about AI agents and LLMs."
# Generate the summary.
summary = summarizer(text)[0]["summary_text"]
# Print the summary.
print(f"Summary: {summary}")

Challenges in Deployment and Scaling
Deploying and scaling integrated AI agents with LLMs presents significant technical and operational challenges. One of the primary challenges is the computational cost, particularly as LLMs grow in size and complexity.
Addressing this issue involves resource-efficient strategies such as model pruning, quantization, and distributed computing. These can help reduce the computational burden without sacrificing performance.
Maintaining reliability and robustness in real-world applications is also crucial, necessitating ongoing monitoring, regular updates, and the development of fail-safe mechanisms to manage unexpected inputs or system failures.
As these systems are deployed across various industries, adherence to ethical standards—including fairness, transparency, and accountability—becomes increasingly important. These considerations are central to the system’s acceptance and long-term success, impacting public trust and the ethical implications of AI-driven decisions in diverse societal contexts (Bender et al., 2021).
The technical implementation of AI agents integrated with LLMs involves careful architectural design, rigorous training methodologies, and thoughtful consideration of deployment challenges.
The effectiveness and reliability of these systems in real-world environments depend on addressing both technical and ethical concerns, ensuring that AI technologies function smoothly and responsibly across various applications.
Chapter 7: The Future of AI Agents and LLMs
Convergence of LLMs with Reinforcement Learning
As you explore the future of AI agents and Large Language Models (LLMs), the convergence of LLMs with reinforcement learning stands out as a particularly transformative development. This integration pushes the boundaries of traditional AI by enabling systems to not only generate and understand language but also to learn from their interactions in real-time.
Through reinforcement learning, AI agents can adaptively modify their strategies based on feedback from their environment, resulting in a continuous refinement of their decision-making processes. This means that, unlike static models, AI systems enhanced with reinforcement learning can handle increasingly complex and dynamic tasks with minimal human oversight.
The implications for such systems are profound: in applications ranging from autonomous robotics to personalized education, AI agents could autonomously improve their performance over time, making them more efficient and responsive to the evolving demands of their operational contexts.
Example: Text-Based Game Playing
Imagine an AI agent playing a text-based adventure game.
Environment: The game itself (rules, state descriptions, and so on)
LLM: Processes the game's text, understands the current situation, and generates possible actions (for example, "go north", "take sword").
Reward: Given by the game based on the outcome of the action (for example, positive reward for finding treasure, negative for losing health).
Code Example (Conceptual using Python and OpenAI's API):
import openai
import random
# ... (Game environment logic - not shown here) ...
def get_agent_action(state_description):
"""Uses the LLM to get an action based on the game state."""
prompt = f"""You are playing a text adventure game.
Current state: {state_description}
What do you do next?"""
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
temperature=0.7,
max_tokens=50
)
action = response.choices[0].text.strip()
return action
# ... (RL training loop - simplified) ...
for episode in range(num_episodes):
state = game_environment.reset()
done = False
while not done:
action = get_agent_action(state)
next_state, reward, done = game_environment.step(action)
# ... (Update the RL agent based on reward - not shown) ...
state = next_state
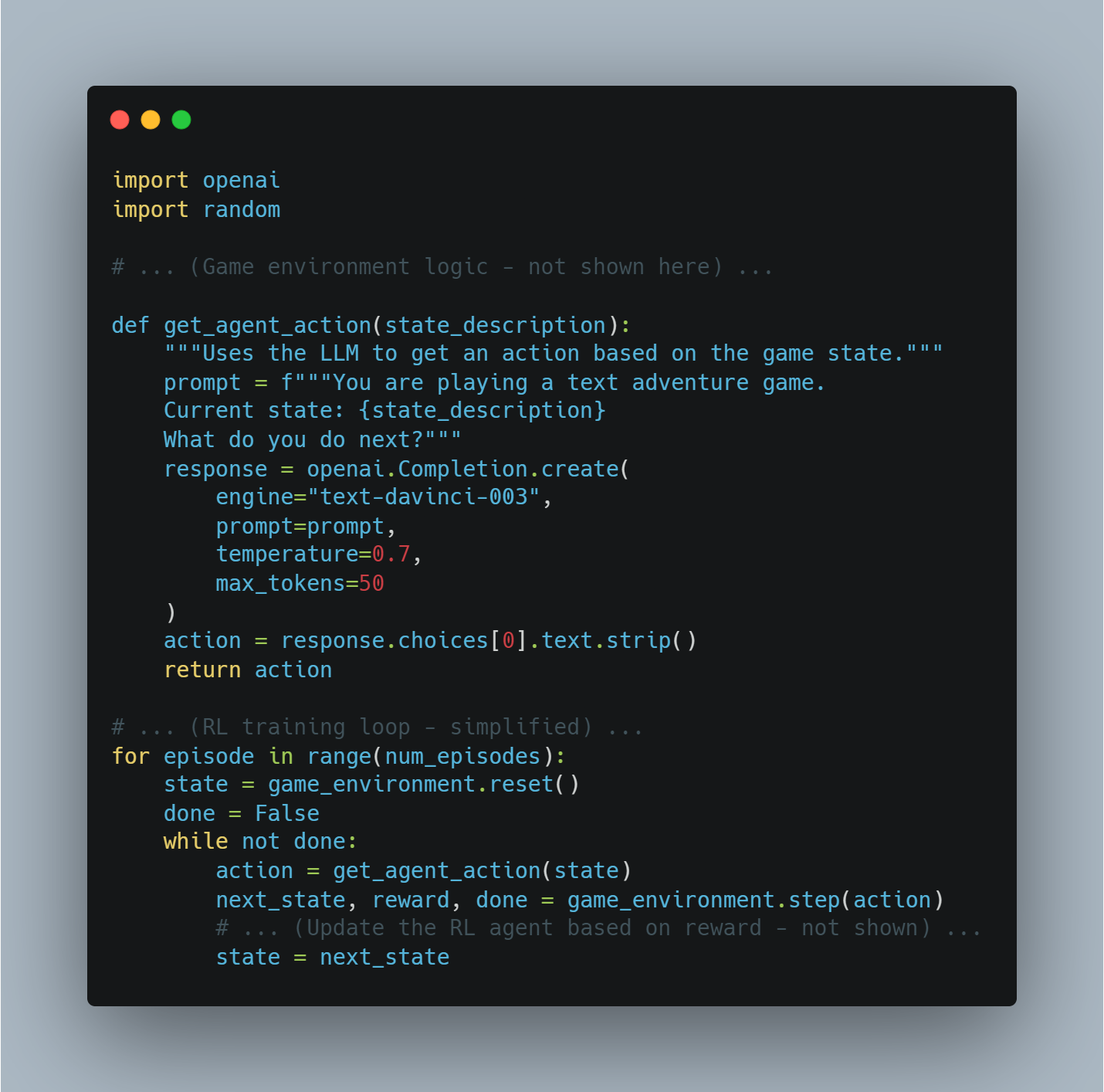
Multimodal AI Integration
The integration of multimodal AI is another critical trend shaping the future of AI agents. By enabling systems to process and combine data from various sources—such as text, images, audio, and sensory inputs—multimodal AI offers a more comprehensive understanding of the environments in which these systems operate.
For instance, in autonomous vehicles, the ability to synthesize visual data from cameras, contextual data from maps, and real-time traffic updates allows the AI to make more informed and safer driving decisions.
This capability extends to other domains like healthcare, where an AI agent could integrate patient data from medical records, diagnostic imaging, and genomic information to deliver more accurate and personalized treatment recommendations.
The challenge here lies in the seamless integration and real-time processing of diverse data streams, which requires advances in model architecture and data fusion techniques.
Successfully overcoming these challenges will be pivotal in deploying AI systems that are truly intelligent and capable of functioning in complex, real-world environments.
Multimodal AI example 1: Image Captioning for Visual Question Answering
Goal: An AI agent that can answer questions about images.
Modalities: Image, Text
Process:
Image Feature Extraction: Use a pre-trained Convolutional Neural Network (CNN) to extract features from the image.
Caption Generation: Use an LLM (like a Transformer model) to generate a caption describing the image based on the extracted features.
Question Answering: Use another LLM to process both the question and the generated caption to provide an answer.
Code Example (Conceptual using Python and Hugging Face Transformers):
from transformers import ViTFeatureExtractor, VisionEncoderDecoderModel, AutoTokenizer, AutoModelForQuestionAnswering
from PIL import Image
import requests
# Load pre-trained models
image_model_name = "nlpconnect/vit-gpt2-image-captioning"
feature_extractor = ViTFeatureExtractor.from_pretrained(image_model_name)
image_caption_model = VisionEncoderDecoderModel.from_pretrained(image_model_name)
qa_model_name = "distilbert-base-cased-distilled-squad"
qa_tokenizer = AutoTokenizer.from_pretrained(qa_model_name)
qa_model = AutoModelForQuestionAnswering.from_pretrained(qa_model_name)
# Function to generate image caption
def generate_caption(image_url):
image = Image.open(requests.get(image_url, stream=True).raw)
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
generated_caption = image_caption_model.generate(pixel_values, max_length=50, num_beams=4, early_stopping=True)
caption = tokenizer.decode(generated_caption[0], skip_special_tokens=True)
return caption
# Function to answer questions about the image
def answer_question(question, caption):
inputs = qa_tokenizer(question, caption, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
outputs = qa_model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
answer_start = torch.argmax(answer_start_scores)
answer_end = torch.argmax(answer_end_scores) + 1
answer = qa_tokenizer.convert_tokens_to_string(qa_tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
return answer
# Example usage
image_url = "https://example.com/image.jpg"
caption = generate_caption(image_url)
question = "What is in the image?"
answer = answer_question(question, caption)
print(f"Caption: {caption}")
print(f"Answer: {answer}")
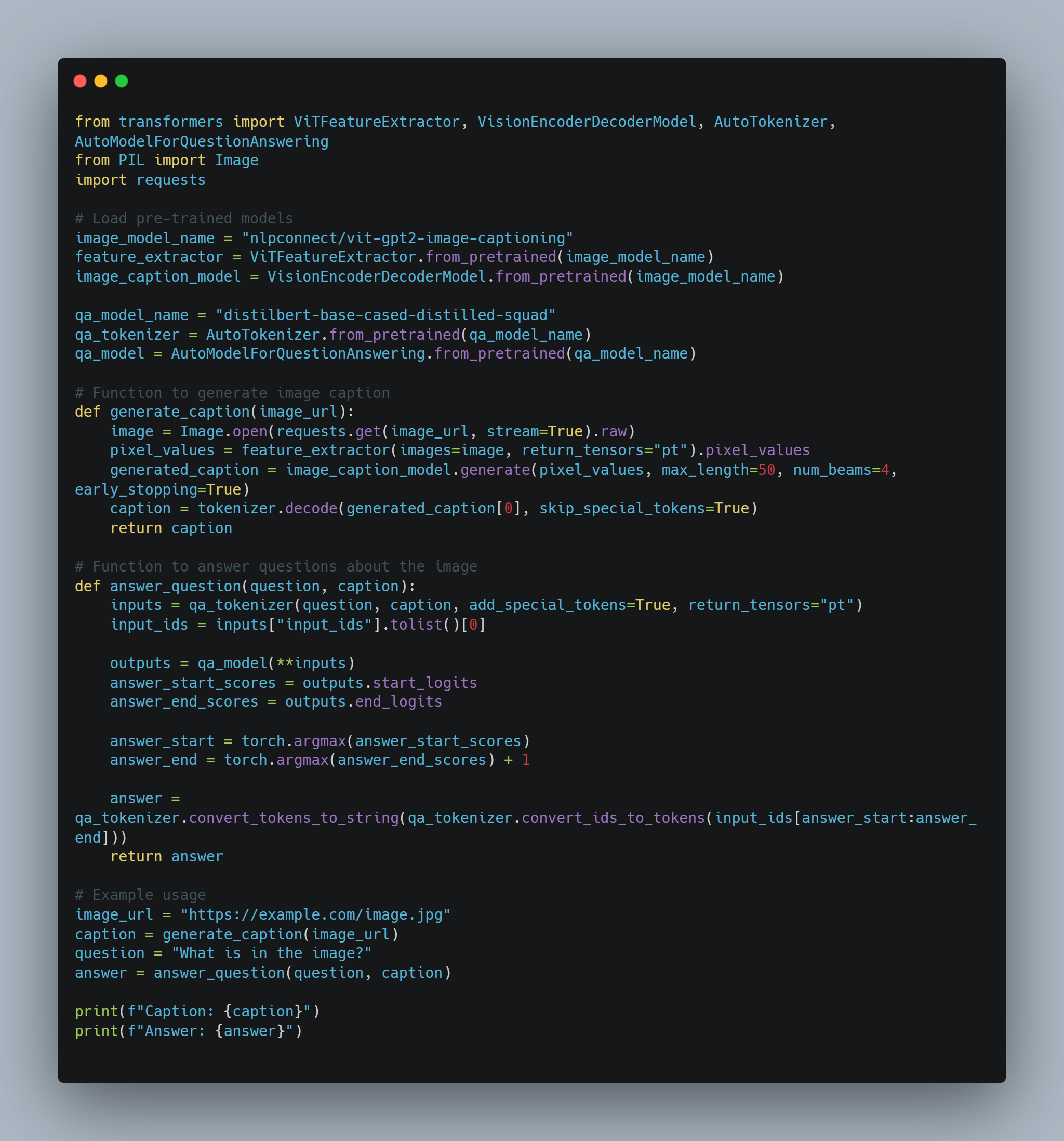
Multimodal AI example 2: Sentiment Analysis from Text and Audio
Goal: An AI agent that analyzes sentiment from both the text and tone of a message.
Modalities: Text, Audio
Process:
Text Sentiment: Use a pre-trained sentiment analysis model on the text.
Audio Sentiment: Use an audio processing model to extract features like tone and pitch, then use these features to predict sentiment.
Fusion: Combine the text and audio sentiment scores (for example, weighted average) to get the overall sentiment.
Code Example (Conceptual using Python):
from transformers import pipeline # For text sentiment
# ... (Import audio processing and sentiment libraries - not shown) ...
# Load pre-trained models
text_sentiment_model = pipeline("sentiment-analysis")
def analyze_sentiment(text, audio_file):
# Text sentiment
text_result = text_sentiment_model(text)[0]
text_sentiment = text_result['label']
text_confidence = text_result['score']
# Audio sentiment
# ... (Process audio, extract features, predict sentiment - not shown) ...
audio_sentiment = # ... (Result from audio sentiment model)
audio_confidence = # ... (Confidence score from audio model)
# Combine sentiment (example: weighted average)
overall_sentiment = 0.7 * text_confidence * (1 if text_sentiment=="POSITIVE" else -1) + \
0.3 * audio_confidence * (1 if audio_sentiment=="POSITIVE" else -1)
return overall_sentiment
# Example usage
text = "This is great!"
audio_file = "recording.wav"
sentiment = analyze_sentiment(text, audio_file)
print(f"Overall Sentiment Score: {sentiment}")
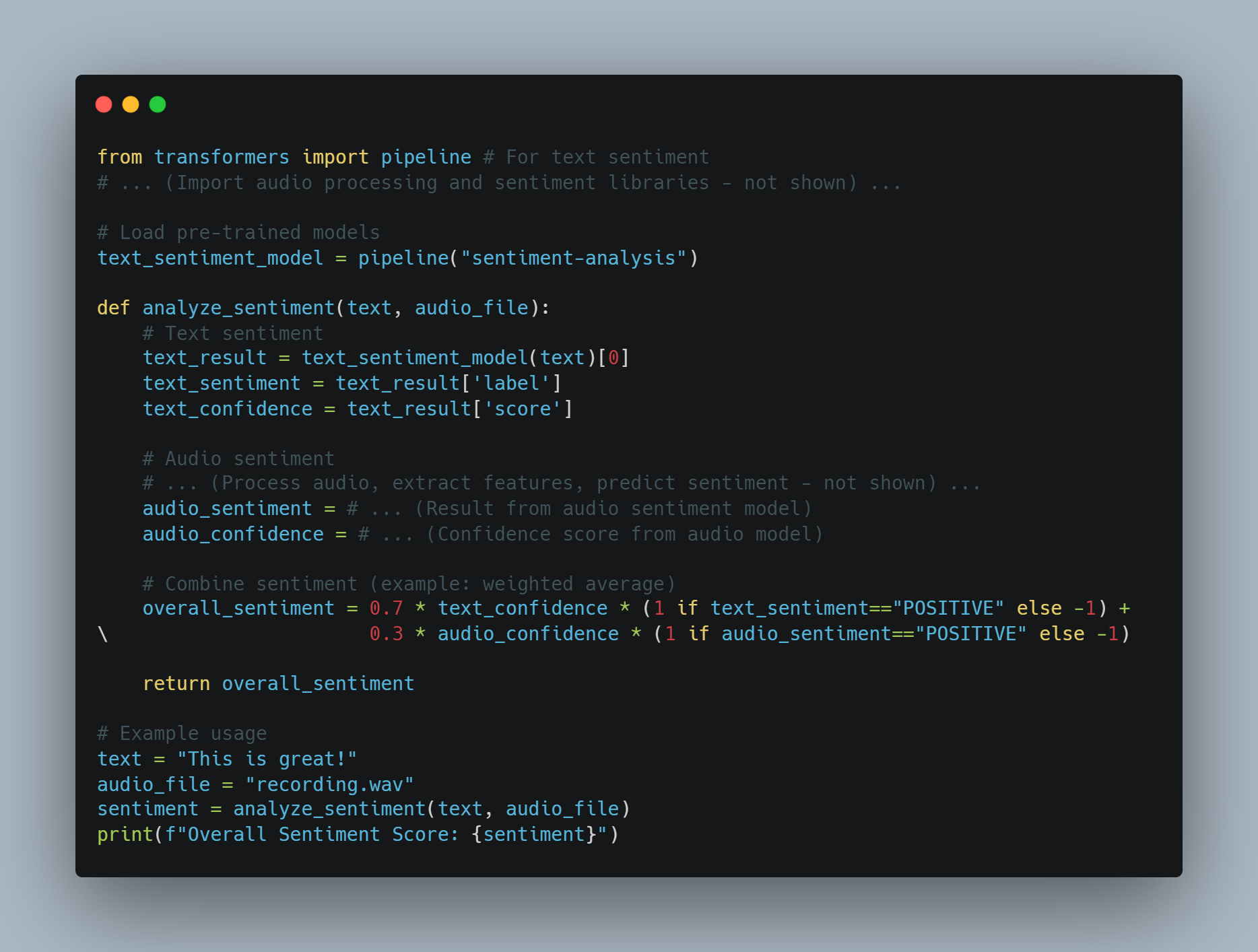
Challenges and Considerations:
Data Alignment: Ensuring that data from different modalities is synchronized and aligned is crucial.
Model Complexity: Multimodal models can be complex to train and require large, diverse datasets.
Fusion Techniques: Choosing the right method to combine information from different modalities is important and problem-specific.
Multimodal AI is a rapidly evolving field with the potential to revolutionize how AI agents perceive and interact with the world.
Distributed AI Systems and Edge Computing
Looking towards the evolution of AI infrastructures, the shift towards distributed AI systems, supported by edge computing, represents a significant advancement.
Distributed AI systems decentralize computational tasks by processing data closer to the source—such as IoT devices or local servers—rather than relying on centralized cloud resources. This approach not only reduces latency, which is crucial for time-sensitive applications like autonomous drones or industrial automation, but also enhances data privacy and security by keeping sensitive information local.
Also, distributed AI systems improve scalability, allowing for the deployment of AI across vast networks, such as smart cities, without overwhelming centralized data centers.
The technical challenges associated with distributed AI include ensuring consistency and coordination across distributed nodes, as well as optimizing resource allocation to maintain performance across diverse and potentially resource-constrained environments.
As you develop and deploy AI systems, embracing distributed architectures will be key to creating resilient, efficient, and scalable AI solutions that meet the demands of future applications.
Distributed AI Systems and Edge Computing example 1: Federated Learning for Privacy-Preserving Model Training
Goal: Train a shared model across multiple devices (for example, smartphones) without directly sharing sensitive user data.
Approach:
Local Training: Each device trains a local model on its own data.
Parameter Aggregation: Devices send model updates (gradients or parameters) to a central server.
Global Model Update: The server aggregates the updates, improves the global model, and sends the updated model back to the devices.
Code Example (Conceptual using Python and PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim
# ... (Code for communication between devices and server - not shown) ...
class SimpleModel(nn.Module):
# ... (Define your model architecture here) ...
# Device-side training function
def train_on_device(device_data, global_model):
local_model = SimpleModel()
local_model.load_state_dict(global_model.state_dict()) # Start with global model
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(local_model.parameters(), lr=0.01)
for epoch in range(local_epochs):
# ... (Train local_model on device_data) ...
loss = ...
loss.backward()
optimizer.step()
return local_model.state_dict()
# Server-side aggregation function
def aggregate_updates(global_model, device_updates):
for key in global_model.state_dict().keys():
update = torch.stack([device_update[key] for device_update in device_updates]).mean(0)
global_model.state_dict()[key].data.add_(update)
# ... (Main Federated Learning loop - simplified) ...
global_model = SimpleModel()
for round in range(num_rounds):
device_updates = []
for device_data in get_data_from_devices():
device_update = train_on_device(device_data, global_model)
device_updates.append(device_update)
aggregate_updates(global_model, device_updates)
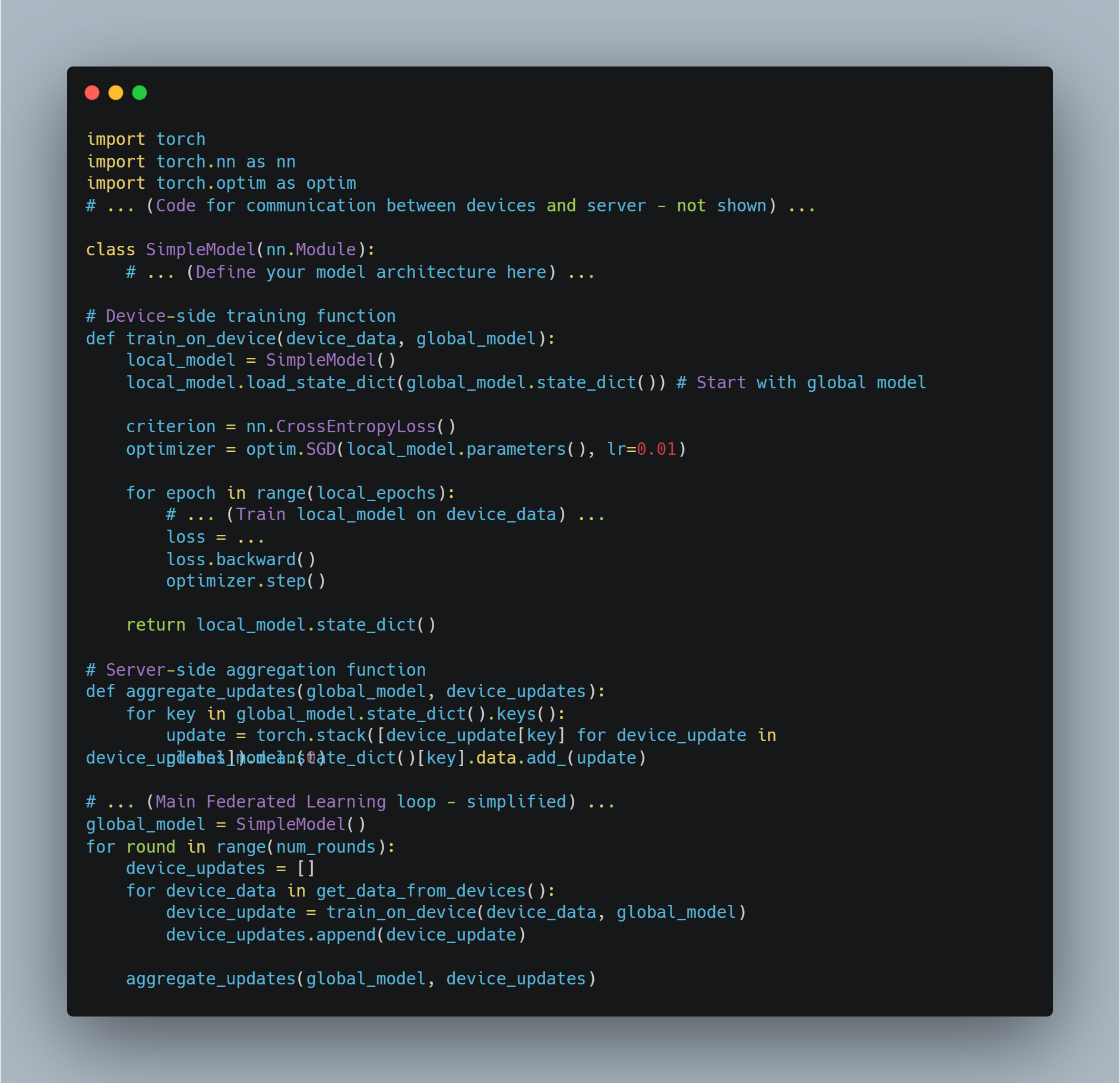
Example 2: Real-Time Object Detection on Edge Devices
Goal: Deploy an object detection model on a resource-constrained device (for example, Raspberry Pi) for real-time inference.
Approach:
Model Optimization: Use techniques like model quantization or pruning to reduce the model size and computational requirements.
Edge Deployment: Deploy the optimized model to the edge device.
Local Inference: The device performs object detection locally, reducing latency and reliance on cloud communication.
Code Example (Conceptual using Python and TensorFlow Lite):
import tensorflow as tf
# Load the pre-trained model (assuming it's already optimized for TensorFlow Lite)
interpreter = tf.lite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Get input and output details
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# ... (Capture image from camera or load from file - not shown) ...
# Preprocess the image
input_data = ... # Resize, normalize, etc.
interpreter.set_tensor(input_details[0]['index'], input_data)
# Run inference
interpreter.invoke()
# Get the output
output_data = interpreter.get_tensor(output_details[0]['index'])
# ... (Process output_data to get bounding boxes, classes, etc.) ...
Challenges and Considerations:
Communication Overhead: Efficiently coordinating and communicating between distributed nodes is crucial.
Resource Management: Optimizing resource allocation (CPU, memory, bandwidth) across devices is important.
Security: Securing distributed systems and protecting data privacy are paramount concerns.
Distributed AI and edge computing are essential for building scalable, efficient, and privacy-aware AI systems, especially as we move towards a future with billions of interconnected devices.
Advancements in Natural Language Processing
Natural Language Processing (NLP) continues to be at the forefront of AI advancements, driving significant improvements in how machines understand, generate, and interact with human language.
Recent developments in NLP, such as the evolution of transformers and attention mechanisms, have drastically enhanced the ability of AI to process complex linguistic structures, making interactions more natural and contextually aware.
This progress has enabled AI systems to understand nuances, sentiments, and even cultural references within text, leading to more accurate and meaningful communication.
For instance, in customer service, advanced NLP models can not only handle queries with precision but also detect emotional cues from customers, enabling more empathetic and effective responses.
Looking ahead, the integration of multilingual capabilities and deeper semantic understanding in NLP models will further expand their applicability, allowing for seamless communication across different languages and dialects, and even enabling AI systems to serve as real-time translators in diverse global contexts.
Natural Language Processing (NLP) is rapidly evolving, with breakthroughs in areas like transformer models and attention mechanisms. Here are some examples and code snippets to illustrate these advancements:
NLP example 1: Sentiment Analysis with Fine-tuned Transformers
Goal: Analyze the sentiment of text with high accuracy, capturing nuances and context.
Approach: Fine-tune a pre-trained transformer model (like BERT) on a sentiment analysis dataset.
Code Example (using Python and Hugging Face Transformers):
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Load pre-trained model and dataset
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # 3 labels: Positive, Negative, Neutral
dataset = load_dataset("imdb", split="train[:10%]")
# Define training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8,
)
# Fine-tune the model
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./fine_tuned_sentiment_model")
# Load the fine-tuned model for inference
from transformers import pipeline
sentiment_classifier = pipeline("sentiment-analysis", model="./fine_tuned_sentiment_model")
# Example usage
text = "This movie was absolutely amazing! I loved the plot and the characters."
result = sentiment_classifier(text)[0]
print(f"Sentiment: {result['label']}, Confidence: {result['score']:.4f}")
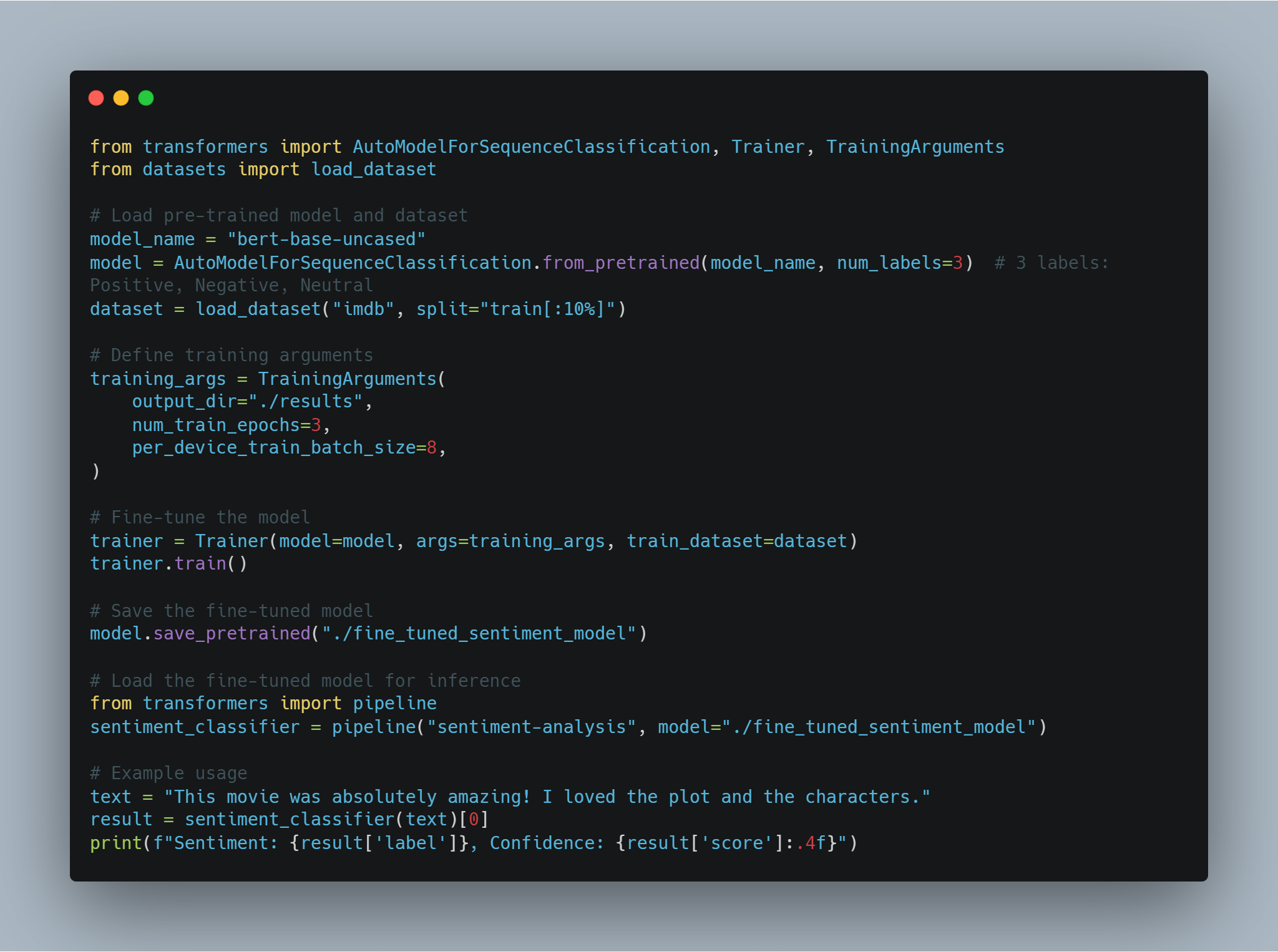
NLP Example 2: Multilingual Machine Translation with a Single Model
Goal: Translate between multiple languages using a single model, leveraging shared linguistic representations.
Approach: Use a large, multilingual transformer model (like mBART or XLM-R) that has been trained on a massive dataset of parallel text in multiple languages.
Code Example (using Python and Hugging Face Transformers):
from transformers import pipeline
# Load a pre-trained multilingual translation pipeline
translator = pipeline("translation", model="facebook/mbart-large-50-many-to-many-mmt")
# Example usage: English to French
text_en = "This is an example of multilingual translation."
translation_fr = translator(text_en, src_lang="en_XX", tgt_lang="fr_XX")[0]['translation_text']
print(f"French Translation: {translation_fr}")
# Example usage: French to Spanish
translation_es = translator(translation_fr, src_lang="fr_XX", tgt_lang="es_XX")[0]['translation_text']
print(f"Spanish Translation: {translation_es}")
NLP Example 3: Contextual Word Embeddings for Semantic Similarity
Goal: Determine the similarity between words or sentences, taking context into account.
Approach: Use a transformer model (like BERT) to generate contextual word embeddings, which capture the meaning of words within a specific sentence.
Code Example (using Python and Hugging Face Transformers):
from transformers import AutoModel, AutoTokenizer
import torch
# Load pre-trained model and tokenizer
model_name = "bert-base-uncased"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Function to get sentence embeddings
def get_sentence_embedding(sentence):
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Use the [CLS] token embedding as the sentence embedding
sentence_embedding = outputs.last_hidden_state[:, 0, :]
return sentence_embedding
# Example usage
sentence1 = "The cat sat on the mat."
sentence2 = "A fluffy feline is resting on the rug."
embedding1 = get_sentence_embedding(sentence1)
embedding2 = get_sentence_embedding(sentence2)
# Calculate cosine similarity
similarity = torch.cosine_similarity(embedding1, embedding2)
print(f"Similarity: {similarity.item():.4f}")
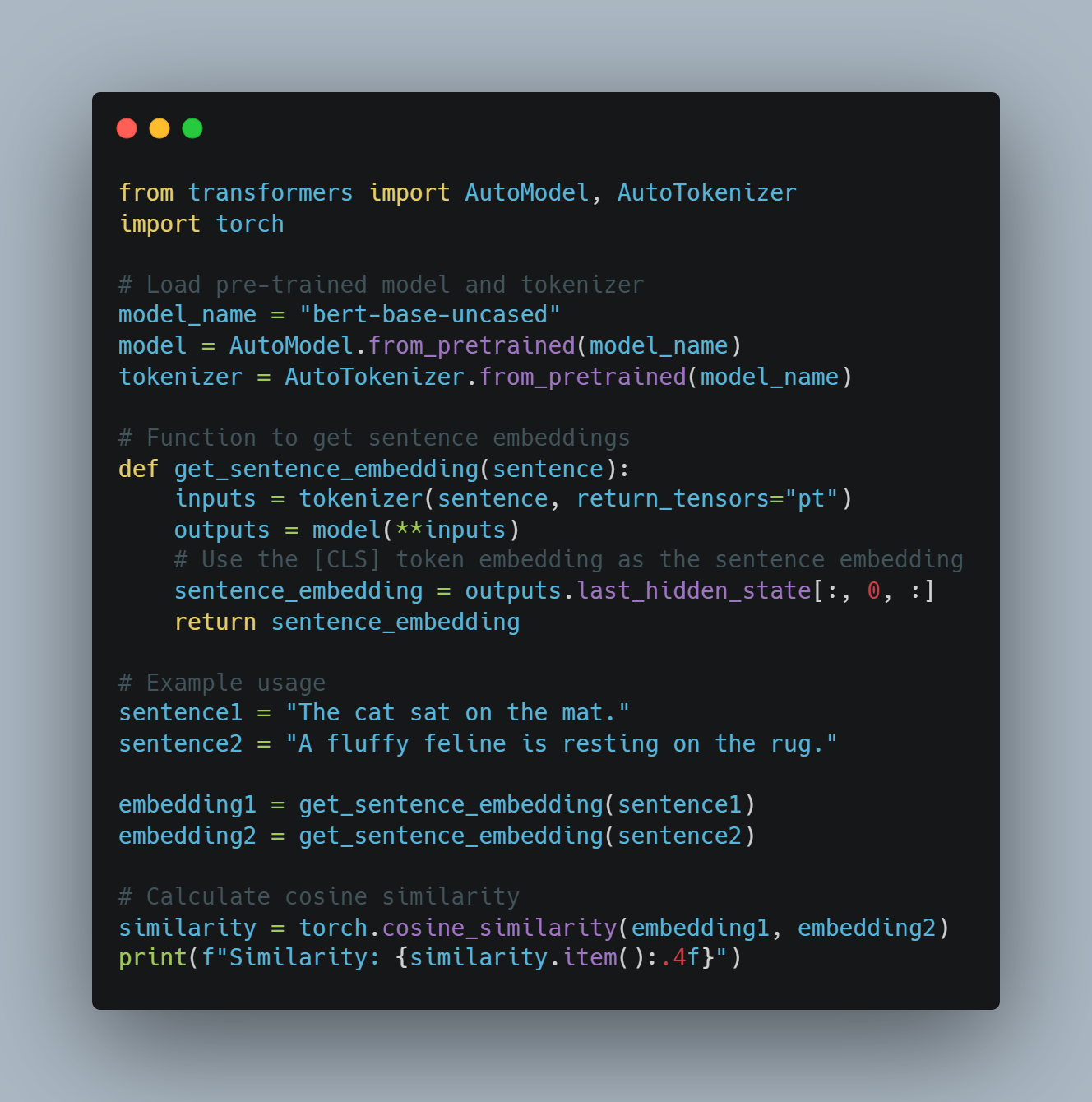
Challenges and Future Directions:
Bias and Fairness: NLP models can inherit biases from their training data, leading to unfair or discriminatory outcomes. Addressing bias is crucial.
Common Sense Reasoning: LLMs still struggle with common sense reasoning and understanding implicit information.
Explainability: The decision-making process of complex NLP models can be opaque, making it difficult to understand why they generate certain outputs.
Despite these challenges, NLP is rapidly advancing. The integration of multimodal information, improved common sense reasoning, and enhanced explainability are key areas of ongoing research that will further revolutionize how AI interacts with human language.
Personalized AI Assistants
The future of personalized AI assistants is poised to become increasingly sophisticated, moving beyond basic task management to truly intuitive, proactive support tailored to individual needs.
These assistants will leverage advanced machine learning algorithms to continuously learn from your behaviors, preferences, and routines, offering increasingly personalized recommendations and automating more complex tasks.
For example, a personalized AI assistant could manage not only your schedule but also anticipate your needs by suggesting relevant resources or adjusting your environment based on your mood or past preferences.
As AI assistants become more integrated into daily life, their ability to adapt to changing contexts and provide seamless, cross-platform support will become a key differentiator. The challenge lies in balancing personalization with privacy, requiring robust data protection mechanisms to ensure that sensitive information is managed securely while delivering a deeply personalized experience.
AI Assistants example 1: Context-Aware Task Suggestion
Goal: An assistant that suggests tasks based on the user's current context (location, time, past behavior).
Approach: Combine user data, contextual signals, and a task recommendation model.
Code Example (Conceptual using Python):
# ... (Code for user data management, context detection - not shown) ...
def get_task_suggestions(user_profile, current_context):
"""Generates task suggestions based on user and context."""
possible_tasks = []
# Example: Time-based suggestions
if current_context["time_of_day"] == "morning":
possible_tasks.extend(user_profile["morning_routines"])
# Example: Location-based suggestions
if current_context["location"] == "office":
possible_tasks.extend(user_profile["work_tasks"])
# ... (Add more rules or use a machine learning model for suggestions) ...
# Rank and filter suggestions
ranked_tasks = rank_tasks_by_relevance(possible_tasks, user_profile, current_context)
top_suggestions = filter_tasks(ranked_tasks)
return top_suggestions
# --- Example Usage ---
user_profile = {
"morning_routines": ["Check email", "Meditate", "Make coffee"],
"work_tasks": ["Prepare presentation", "Schedule meeting", "Answer emails"],
# ... other preferences ...
}
current_context = {
"time_of_day": "morning",
"location": "home",
# ... other context data ...
}
suggestions = get_task_suggestions(user_profile, current_context)
print("Here are some tasks you might want to do:", suggestions)
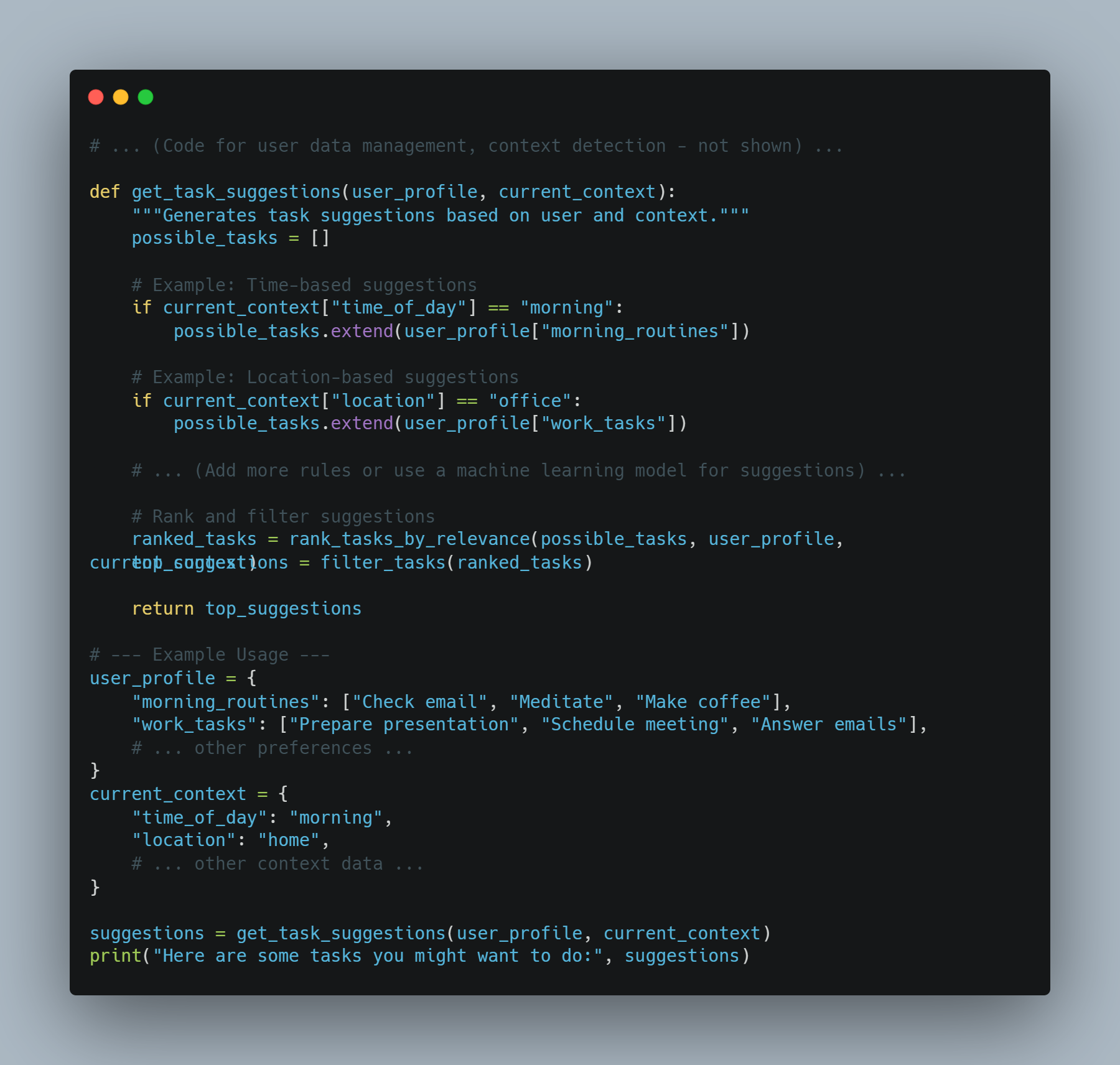
AI Assistants example 2: Proactive Information Delivery
Goal: An assistant that proactively provides relevant information based on user's schedule and preferences.
Approach: Integrate calendar data, user interests, and a content retrieval system.
Code Example (Conceptual using Python):
# ... (Code for calendar access, user interest profile - not shown) ...
def get_relevant_info(user_profile, calendar_events):
"""Retrieves information relevant to upcoming events."""
relevant_info = []
for event in calendar_events:
if "meeting" in event["title"].lower():
# ... (Retrieve company info, participant profiles, etc.) ...
relevant_info.append(f"Meeting '{event['title']}': {meeting_info}")
elif "travel" in event["title"].lower():
# ... (Retrieve flight status, destination info, etc.) ...
relevant_info.append(f"Trip '{event['title']}': {travel_info}")
return relevant_info
# --- Example Usage ---
calendar_events = [
{"title": "Team Meeting", "time": "10:00 AM"},
{"title": "Flight to New York", "time": "6:00 PM"}
]
user_profile = {
"interests": ["technology", "travel", "business"]
# ... other preferences ...
}
info = get_relevant_info(user_profile, calendar_events)
for item in info:
print(item)
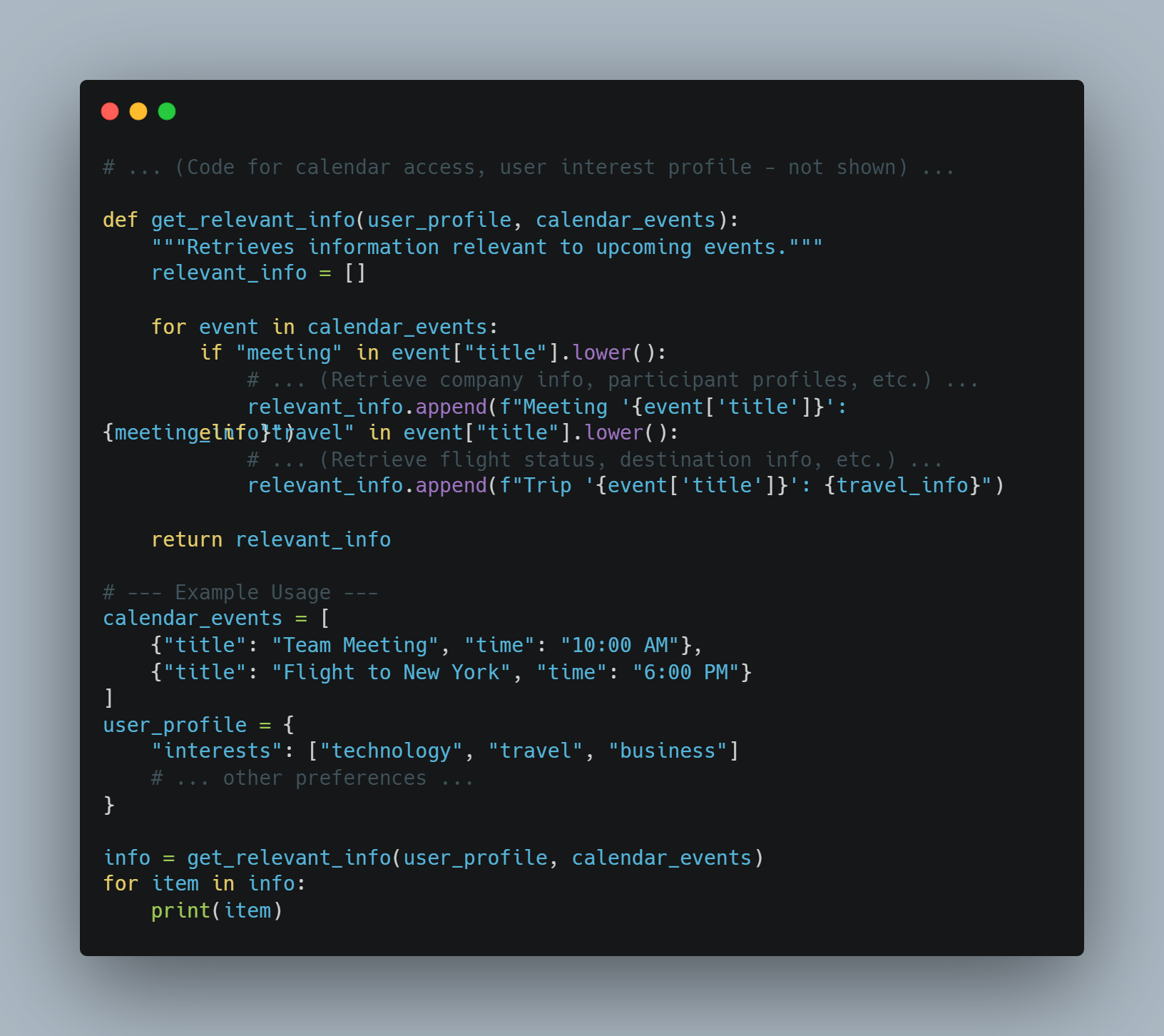
AI Assistants example 3: Personalized Content Recommendation
Goal: An assistant that recommends content (articles, videos, music) tailored to user preferences.
Approach: Use collaborative filtering or content-based recommendation systems.
Code Example (Conceptual using Python and a library like Surprise):
from surprise import Dataset, Reader, SVD
# ... (Code for managing user ratings, content database - not shown) ...
def train_recommendation_model(ratings_data):
"""Trains a collaborative filtering model."""
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings_data[["user_id", "item_id", "rating"]], reader)
algo = SVD()
algo.fit(data.build_full_trainset())
return algo
def get_recommendations(user_id, model, n=5):
"""Gets top N recommendations for a user."""
# ... (Get predictions for all items, rank, and return top N) ...
# --- Example Usage ---
ratings_data = [
{"user_id": 1, "item_id": "article_1", "rating": 5},
{"user_id": 1, "item_id": "video_2", "rating": 4},
{"user_id": 2, "item_id": "article_1", "rating": 3},
# ... more ratings ...
]
model = train_recommendation_model(ratings_data)
recommendations = get_recommendations(user_id=1, model=model, n=3)
print("Recommended for you:", recommendations)
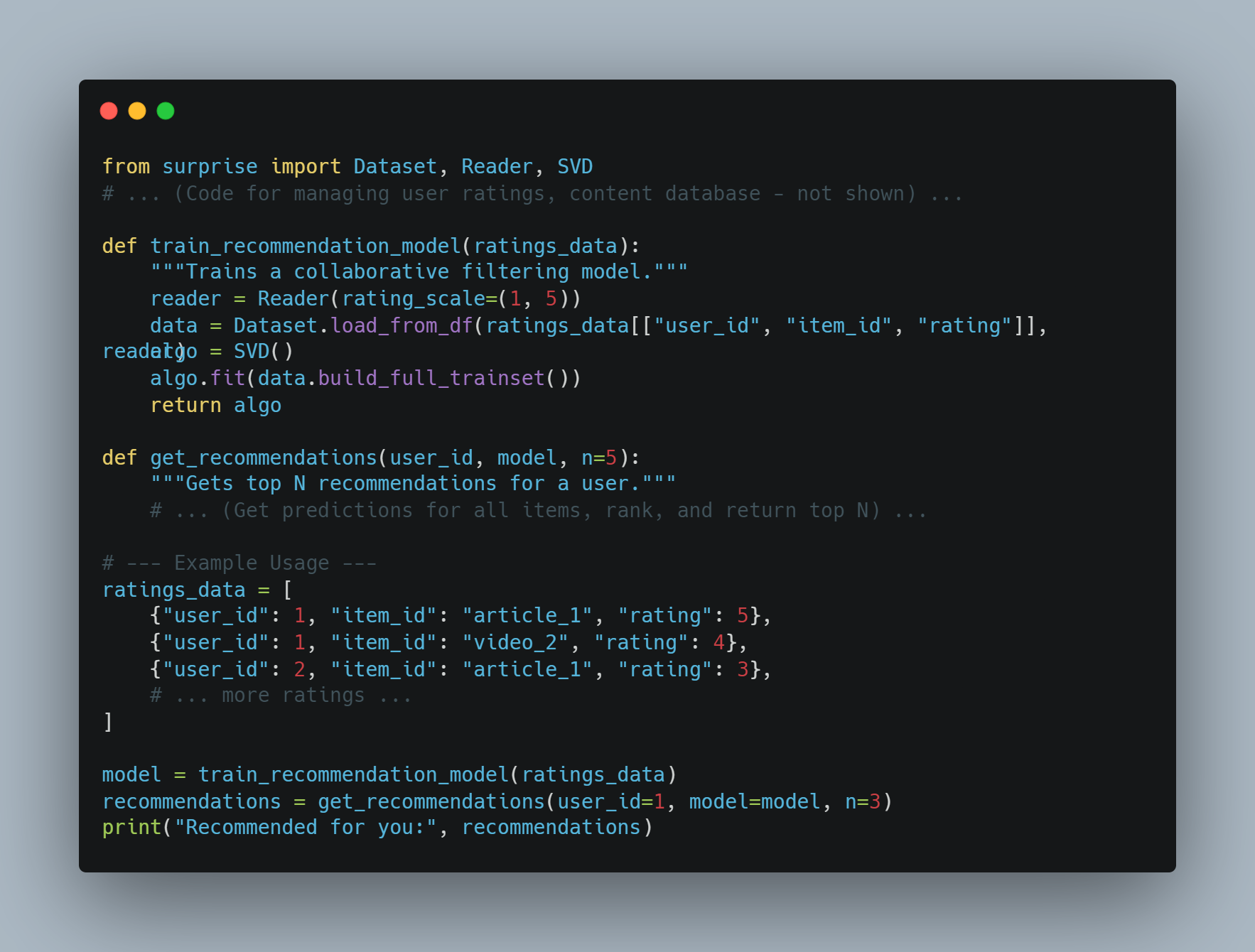
Challenges and Ethical Considerations:
Data Privacy: Handling user data responsibly and transparently is crucial.
Bias and Fairness: Personalization should not amplify existing biases.
User Control: Users should have control over their data and personalization settings.
Building personalized AI assistants requires careful consideration of both technical and ethical aspects to create systems that are helpful, trustworthy, and respect user privacy.
AI in Creative Industries
AI is making significant inroads into the creative industries, transforming how art, music, film, and literature are produced and consumed. With advancements in generative models, such as Generative Adversarial Networks (GANs) and transformer-based models, AI can now generate content that rivals human creativity.
For instance, AI can compose music that reflects specific genres or moods, create digital art that mimics the style of famous painters, or even draft narrative plots for films and novels.
In the advertising industry, AI is being used to generate personalized content that resonates with individual consumers, enhancing engagement and effectiveness.
But the rise of AI in creative fields also raises questions about authorship, originality, and the role of human creativity. As you engage with AI in these domains, it will be crucial to explore how AI can complement human creativity rather than replace it, fostering collaboration between humans and machines to produce innovative and impactful content.
Here's an example of how GPT-4 can be integrated into a Python project for creative tasks, specifically in the realm of writing. This code demonstrates how to leverage GPT-4's capabilities to generate creative text formats, like poetry.
import openai
# Set your OpenAI API key
openai.api_key = "YOUR_API_KEY"
# Define a function to generate poetry
def generate_poetry(topic, style):
"""
Generates a poem based on the given topic and style.
Args:
topic (str): The subject of the poem.
style (str): The desired poetic style (e.g., free verse, sonnet, haiku).
Returns:
str: The generated poem.
"""
prompt = f"""
Write a {style} poem about {topic}.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
poem = response.choices[0].message.content
return poem
# Example usage
topic = "the beauty of nature"
style = "free verse"
poem = generate_poetry(topic, style)
print(poem)
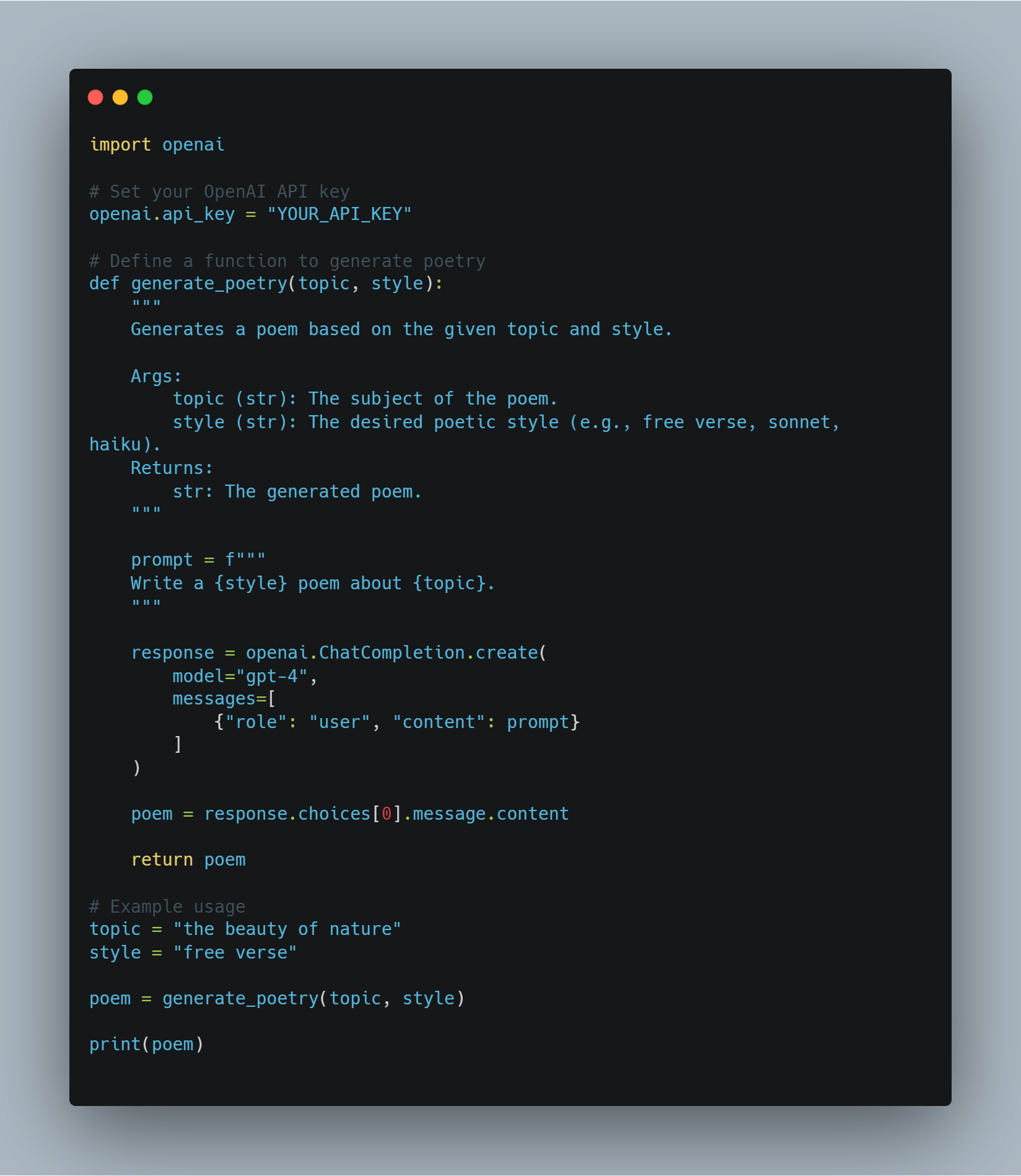
Let’s see what’s going on here:
Import OpenAI library: The code first imports the
openailibrary to access the OpenAI API.Set API key: Replace
"YOUR_API_KEY"with your actual OpenAI API key.Define
generate_poetryfunction: This function takes the poem'stopicandstyleas input and uses OpenAI's ChatCompletion API to generate the poem.Construct the prompt: The prompt combines the
topicandstyleinto a clear instruction for GPT-4.Send prompt to GPT-4: The code uses
openai.ChatCompletion.createto send the prompt to GPT-4 and receive the generated poem as a response.Return the poem: The generated poem is then extracted from the response and returned by the function.
Example usage: The code demonstrates how to call the
generate_poetryfunction with a specific topic and style. The resulting poem is then printed to the console.
AI-Powered Virtual Worlds
The development of AI-powered virtual worlds represents a significant leap in immersive experiences, where AI agents can create, manage, and evolve virtual environments that are both interactive and responsive to user input.
These virtual worlds, driven by AI, can simulate complex ecosystems, social interactions, and dynamic narratives, offering users a deeply engaging and personalized experience.
For example, in the gaming industry, AI can be used to create non-playable characters (NPCs) that learn from player behavior, adapting their actions and strategies to provide a more challenging and realistic experience.
Beyond gaming, AI-powered virtual worlds have potential applications in education, where virtual classrooms can be tailored to the learning styles and progress of individual students, or in corporate training, where realistic simulations can prepare employees for various scenarios.
The future of these virtual environments will depend on advancements in AI's ability to generate and manage vast, complex digital ecosystems in real-time, as well as on ethical considerations around user data and the psychological impacts of highly immersive experiences.
import random
from typing import List, Dict, Tuple
class VirtualWorld:
"""
Represents a simple AI-powered virtual world with dynamic environments and agents.
"""
def __init__(self, environment_size: Tuple[int, int], agent_types: List[str],
agent_properties: Dict[str, Dict]):
"""
Initializes the virtual world with specified parameters.
Args:
environment_size (Tuple[int, int]): Dimensions of the world (width, height).
agent_types (List[str]): List of different agent types (e.g., "player", "npc", "animal").
agent_properties (Dict[str, Dict]): Dictionary mapping agent types to their properties,
including initial number, movement speed, and other attributes.
"""
self.environment = [[' ' for _ in range(environment_size[0])] for _ in range(environment_size[1])]
self.agents = []
self.agent_types = agent_types
self.agent_properties = agent_properties
# Initialize agents
for agent_type in agent_types:
for _ in range(agent_properties[agent_type]['initial_number']):
self.add_agent(agent_type)
def add_agent(self, agent_type: str):
"""
Adds a new agent of the specified type to the world.
Args:
agent_type (str): The type of agent to add.
"""
# Assign random position within the environment
x = random.randint(0, len(self.environment[0]) - 1)
y = random.randint(0, len(self.environment) - 1)
# Create and add the agent
agent = Agent(agent_type, (x, y), self.agent_properties[agent_type])
self.agents.append(agent)
def update(self):
"""
Updates the virtual world for a single time step.
This involves moving agents, handling interactions, and potentially modifying the environment.
"""
# Move agents (simplified movement for demonstration)
for agent in self.agents:
agent.move(self.environment)
# TODO: Implement more complex logic for interactions, environment changes, etc.
def display(self):
"""
Prints a simple representation of the virtual world.
"""
for row in self.environment:
print(''.join(row))
class Agent:
"""
Represents a single agent in the virtual world.
"""
def __init__(self, agent_type: str, position: Tuple[int, int], properties: Dict):
"""
Initializes an agent with its type, position, and properties.
Args:
agent_type (str): The type of the agent.
position (Tuple[int, int]): The agent's initial position in the world.
properties (Dict): A dictionary containing the agent's properties.
"""
self.agent_type = agent_type
self.position = position
self.properties = properties
def move(self, environment: List[List[str]]):
"""
Moves the agent within the environment based on its properties.
Args:
environment (List[List[str]]): The environment's grid representation.
"""
# Determine movement direction (random for this example)
direction = random.choice(['N', 'S', 'E', 'W'])
# Apply movement based on direction
if direction == 'N' and self.position[1] > 0:
self.position = (self.position[0], self.position[1] - 1)
elif direction == 'S' and self.position[1] < len(environment) - 1:
self.position = (self.position[0], self.position[1] + 1)
elif direction == 'E' and self.position[0] < len(environment[0]) - 1:
self.position = (self.position[0] + 1, self.position[1])
elif direction == 'W' and self.position[0] > 0:
self.position = (self.position[0] - 1, self.position[1])
# Update the environment to reflect the agent's new position
environment[self.position[1]][self.position[0]] = self.agent_type[0]
# Example Usage
if __name__ == "__main__":
# Define world parameters
environment_size = (10, 10)
agent_types = ["player", "npc", "animal"]
agent_properties = {
"player": {"initial_number": 1, "movement_speed": 2},
"npc": {"initial_number": 5, "movement_speed": 1},
"animal": {"initial_number": 10, "movement_speed": 0.5},
}
# Create the virtual world
world = VirtualWorld(environment_size, agent_types, agent_properties)
# Simulate the world for several steps
for _ in range(10):
world.update()
world.display()
print() # Add an empty line for better readability
Here’s what’s going on in this code:
VirtualWorld Class:
Defines the core of the virtual world.
Contains the environment grid, a list of agents, and agent-related information.
__init__(): Initializes the world with size, agent types, and properties.add_agent(): Adds a new agent of a specified type to the world.update(): Performs a single time step update of the world.- It currently just moves agents, but you can add complex logic for agent interactions, environment changes, etc.
display(): Prints a basic representation of the environment.
Agent Class:
Represents an individual agent within the world.
__init__(): Initializes the agent with its type, position, and properties.move(): Handles agent movement, updating its position within the environment. This method currently provides a simple random movement, but can be expanded to include complex AI behaviors.
Example Usage:
Sets up world parameters like size, agent types, and their properties.
Creates a VirtualWorld object.
Executes the
update()method multiple times to simulate the world's evolution.Calls
display()after each update to visualize the changes.
Enhancements:
More Complex Agent AI: Implement more sophisticated AI for agent behavior. You can use:
Pathfinding Algorithms: Help agents navigate the environment efficiently.
Decision Trees/Machine Learning: Enable agents to make more intelligent decisions based on their surroundings and goals.
Reinforcement Learning: Teach agents to learn and adapt their behavior over time.
Environment Interaction: Add more dynamic elements to the environment, like obstacles, resources, or points of interest.
Agent-to-Agent Interaction: Implement interactions between agents, such as communication, combat, or cooperation.
Visual Representation: Use libraries like Pygame or Tkinter to create a visual representation of the virtual world.
This example is a basic foundation for creating an AI-powered virtual world. The level of complexity and sophistication can be further expanded to match your specific needs and creative goals.
Neuromorphic Computing and AI
Neuromorphic computing, inspired by the structure and functioning of the human brain, is set to revolutionize AI by offering new ways to process information efficiently and in parallel.
Unlike traditional computing architectures, neuromorphic systems are designed to mimic the neural networks of the brain, enabling AI to perform tasks such as pattern recognition, sensory processing, and decision-making with greater speed and energy efficiency.
This technology holds immense promise for developing AI systems that are more adaptive, capable of learning from minimal data, and effective in real-time environments.
For instance, in robotics, neuromorphic chips could enable robots to process sensory inputs and make decisions with a level of efficiency and speed that current architectures cannot match.
The challenge moving forward will be to scale neuromorphic computing to handle the complexity of large-scale AI applications, integrating it with existing AI frameworks to fully leverage its potential.
AI Agents in Space Exploration
AI agents are increasingly playing a crucial role in space exploration, where they are tasked with navigating harsh environments, making real-time decisions, and conducting scientific experiments autonomously.
As missions venture further into deep space, the need for AI systems that can operate independently of Earth-based control becomes more pressing. Future AI agents will be designed to handle the unpredictability of space, such as unanticipated obstacles, changes in mission parameters, or the need for self-repair.
For instance, AI could be used to guide rovers on Mars to autonomously explore terrain, identify scientifically valuable sites, and even drill for samples with minimal input from mission control. These AI agents could also manage life-support systems on long-duration missions, optimize energy usage, and adapt to the psychological needs of astronauts by providing companionship and mental stimulation.
The integration of AI in space exploration not only enhances mission capabilities but also opens up new possibilities for human exploration of the cosmos, where AI will be an indispensable partner in the quest to understand our universe.
Chapter 8: AI Agents in Mission-Critical Fields
Healthcare
In healthcare, AI agents are not merely supporting roles but are becoming integral to the entire patient care continuum. Their impact is most evident in telemedicine, where AI systems have redefined the approach to remote healthcare delivery.
By utilizing advanced natural language processing (NLP) and machine learning algorithms, these systems perform intricate tasks like symptom triage and preliminary data collection with a high degree of accuracy. They analyze patient-reported symptoms and medical histories in real-time, cross-referencing this information against extensive medical databases to identify potential conditions or red flags.
This enables healthcare providers to make informed decisions more quickly, reducing the time to treatment and potentially saving lives. Also, AI-driven diagnostic tools in medical imaging are transforming radiology by detecting patterns and anomalies in X-rays, MRIs, and CT scans that may be imperceptible to the human eye.
These systems are trained on vast datasets comprising millions of annotated images, enabling them to not only replicate but often surpass human diagnostic capabilities.
The integration of AI into healthcare also extends to administrative tasks, where automation of appointment scheduling, medication reminders, and patient follow-ups significantly reduces the operational burden on healthcare staff, allowing them to focus on more critical aspects of patient care.
Finance
In the financial sector, AI agents have revolutionized operations by introducing unprecedented levels of efficiency and precision.
Algorithmic trading, which relies heavily on AI, has transformed the way trades are executed in financial markets.
These systems are capable of analyzing massive datasets in milliseconds, identifying market trends, and executing trades at the optimal moment to maximize profits and minimize risks. They leverage complex algorithms that incorporate machine learning, deep learning, and reinforcement learning techniques to adapt to changing market conditions, making split-second decisions that human traders could never match.
Beyond trading, AI plays a pivotal role in risk management by assessing credit risks and detecting fraudulent activities with remarkable accuracy. AI models utilize predictive analytics to evaluate a borrower’s likelihood of default by analyzing patterns in credit histories, transaction behaviors, and other relevant factors.
Also, in the realm of regulatory compliance, AI automates the monitoring of transactions to detect and report suspicious activities, ensuring that financial institutions adhere to stringent regulatory requirements. This automation not only mitigates the risk of human error but also streamlines compliance processes, reducing costs and improving efficiency.
Emergency Management
AI's role in emergency management is transformative, fundamentally altering how crises are predicted, managed, and mitigated.
In disaster response, AI agents process vast amounts of data from multiple sources—ranging from satellite imagery to social media feeds—to provide a comprehensive overview of the situation in real-time. Machine learning algorithms analyze this data to identify patterns and predict the progression of events, enabling emergency responders to allocate resources more effectively and make informed decisions under pressure.
For instance, during a natural disaster like a hurricane, AI systems can predict the storm’s path and intensity, allowing authorities to issue timely evacuation orders and deploy resources to the most vulnerable areas.
In predictive analytics, AI models are utilized to forecast potential emergencies by analyzing historical data alongside real-time inputs, enabling proactive measures that can prevent disasters or mitigate their impact.
AI-powered public communication systems also play a crucial role in ensuring that accurate and timely information reaches affected populations. These systems can generate and disseminate emergency alerts across multiple platforms, tailoring the messaging to different demographics to ensure comprehension and compliance.
And AI enhances the preparedness of emergency responders by creating highly realistic training simulations using generative models. These simulations replicate the complexities of real-world emergencies, allowing responders to hone their skills and improve their readiness for actual events.
Transportation
AI systems are becoming indispensable in the transportation sector, where they enhance safety, efficiency, and reliability across various domains, including air traffic control, autonomous vehicles, and public transit.
In air traffic control, AI agents are instrumental in optimizing flight paths, predicting potential conflicts, and managing airport operations. These systems use predictive analytics to foresee potential air traffic bottlenecks, rerouting flights in real-time to ensure safety and efficiency.
In the realm of autonomous vehicles, AI is at the core of enabling vehicles to process sensor data and make split-second decisions in complex environments. These systems employ deep learning models trained on extensive datasets to interpret visual, auditory, and spatial data, allowing for safe navigation through dynamic and unpredictable conditions.
Public transit systems also benefit from AI through optimized route planning, predictive maintenance of vehicles, and management of passenger flow. By analyzing historical and real-time data, AI systems can adjust transit schedules, predict and prevent vehicle breakdowns, and manage crowd control during peak hours, thus improving the overall efficiency and reliability of transportation networks.
Energy Sector
AI is playing a crucial role in the energy sector, particularly in grid management, renewable energy optimization, and fault detection.
In grid management, AI agents monitor and control power grids by analyzing real-time data from sensors distributed across the network. These systems use predictive analytics to optimize energy distribution, ensuring that supply meets demand while minimizing energy waste. AI models also predict potential failures in the grid, allowing for preemptive maintenance and reducing the risk of outages.
In the domain of renewable energy, AI systems are utilized to forecast weather patterns, which is critical for optimizing the production of solar and wind energy. These models analyze meteorological data to predict sunlight intensity and wind speed, allowing for more accurate predictions of energy production and better integration of renewable sources into the grid.
Fault detection is another area where AI is making significant contributions. AI systems analyze sensor data from equipment such as transformers, turbines, and generators to identify signs of wear and tear or potential malfunctions before they lead to failures. This predictive maintenance approach not only extends the lifespan of equipment but also ensures continuous and reliable energy supply.
Cybersecurity
In the field of cybersecurity, AI agents are essential for maintaining the integrity and security of digital infrastructures. These systems are designed to continuously monitor network traffic, using machine learning algorithms to detect anomalies that could indicate a security breach.
By analyzing vast amounts of data in real-time, AI agents can identify patterns of malicious behavior, such as unusual login attempts, data exfiltration activities, or the presence of malware. Once a potential threat is detected, AI systems can automatically initiate countermeasures, such as isolating compromised systems and deploying patches, to prevent further damage.
Vulnerability assessment is another critical application of AI in cybersecurity. AI-powered tools analyze code and system configurations to identify potential security weaknesses before they can be exploited by attackers. These tools use static and dynamic analysis techniques to evaluate the security posture of software and hardware components, providing actionable insights to cybersecurity teams.
The automation of these processes not only enhances the speed and accuracy of threat detection and response but also reduces the workload on human analysts, allowing them to focus on more complex security challenges.
Manufacturing
In manufacturing, AI is driving significant advancements in quality control, predictive maintenance, and supply chain optimization. AI-powered computer vision systems are now capable of inspecting products for defects at a level of speed and precision that far surpasses human capabilities. These systems use deep learning algorithms trained on thousands of images to detect even the smallest imperfections in products, ensuring consistent quality in high-volume production environments.
Predictive maintenance is another area where AI is having a profound impact. By analyzing data from sensors embedded in machinery, AI models can predict when equipment is likely to fail, allowing for maintenance to be scheduled before a breakdown occurs. This approach not only reduces downtime but also extends the lifespan of machinery, leading to significant cost savings.
In supply chain management, AI agents optimize inventory levels and logistics by analyzing data from across the supply chain, including demand forecasts, production schedules, and transportation routes. By making real-time adjustments to inventory and logistics plans, AI ensures that production processes run smoothly, minimizing delays and reducing costs.
These applications demonstrate the critical role of AI in improving operational efficiency and reliability in manufacturing, making it an indispensable tool for companies looking to stay competitive in a rapidly evolving industry.
Conclusion
The integration of AI agents with large language models (LLMs) marks a significant milestone in the evolution of artificial intelligence, unlocking unprecedented capabilities across various industries and scientific domains. This synergy enhances the functionality, adaptability, and applicability of AI systems, addressing the inherent limitations of LLMs and enabling more dynamic, context-aware, and autonomous decision-making processes.
From revolutionizing healthcare and finance to transforming transportation and emergency management, AI agents are driving innovation and efficiency, paving the way for a future where AI technologies are deeply embedded in our daily lives.
As we continue to explore the potential of AI agents and LLMs, it is crucial to ground their development in ethical principles that prioritize human well-being, fairness, and inclusivity. By ensuring that these technologies are designed and deployed responsibly, we can harness their full potential to improve the quality of life, promote social justice, and address global challenges.
The future of AI lies in the seamless integration of advanced AI agents with sophisticated LLMs, creating intelligent systems that not only augment human capabilities but also uphold the values that define our humanity.
The convergence of AI agents and LLMs represents a new paradigm in artificial intelligence, where the collaboration between the agile and the powerful unlocks a realm of boundless possibilities. By leveraging this synergistic power, we can drive innovation, advance scientific discovery, and create a more equitable and prosperous future for all.
About the Author
Vahe Aslanyan here, at the nexus of computer science, data science, and AI. Visit vaheaslanyan.com to see a portfolio that's a testament to precision and progress. My experience bridges the gap between full-stack development and AI product optimization, driven by solving problems in new ways.
With a track record that includes launching a leading data science bootcamp and working with industry top-specialists, my focus remains on elevating tech education to universal standards.
How Can You Dive Deeper?
After studying this guide, if you're keen to dive even deeper and structured learning is your style, consider joining us at LunarTech, we offer individual courses and Bootcamp in Data Science, Machine Learning and AI.
We provide a comprehensive program that offers an in-depth understanding of the theory, hands-on practical implementation, extensive practice material, and tailored interview preparation to set you up for success at your own phase.
You can check out our Ultimate Data Science Bootcamp and join a free trial to try the content first hand. This has earned the recognition of being one of the Best Data Science Bootcamps of 2023, and has been featured in esteemed publications like Forbes, Yahoo, Entrepreneur and more. This is your chance to be a part of a community that thrives on innovation and knowledge. Here is the Welcome message!
Connect with Me

Follow me on LinkedIn for a ton of Free Resources in CS, ML and AI
Subscribe to my The Data Science and AI Newsletter
If you want to learn more about a career in Data Science, Machine Learning and AI, and learn how to secure a Data Science job, you can download this free Data Science and AI Career Handbook.