

While writing my Lisp interpreter (for the Scheme dialect, to be precise), I decided to include support for square brackets. I did this because some of the Scheme books use them interchangeably with parentheses. But I didn't want to make the parser too complex, so I didn't check if the pair of brackets matched.
In my Lisp interpreter, the brackets could be mixed like this:
(let [(x 10])
[+ x x)]
The above code is an example of an S-Expression where we have tokens, a sequence of characters with meaning (like name let or number 10), and brackets/parentheses. However, the code is not valid because it mixes pairs of parentheses and brackets.
(let [(x 10)]
[+ x x])
This is the proper Lisp syntax (if brackets are supported), where opening parentheses always match closing parenthesis and opening brackets always match closing brackets.
In this article, I'll show you how you can detect if the input is the second valid S-Expression and not the first invalid S-Expression.
We will also handle cases like this:
(define foo 10))))
In the code above, you see invalid syntax with more closing than opening parentheses.
So in simple terms, we will detect if pairs of opening and closing characters like (), [], and {} match inside the string like "[foo () {bar}]".
The solution to this problem can be useful when implementing a Lisp parser, but you can also use it for different purposes (like some kind of validation or part of a math expression evaluator). It's also a good exercise.
NOTE: to understand this article and code, you don't need to know anything about Lisp. But if you want some more context, you can read this article: What is Lisp and Scheme?
Pairing with the Stack Data Structure
You may think that the simplest way to solve this problem is using Regular Expressions (RegExp). It may be possible to use Regex for simple cases, but soon it will get too complex and have more problems than it solves.
Actually, the easiest way of pairing opening and closing characters is using the stack. Stack is the simplest data structure. We have two basic operations: push, for adding an item to the stack, and pop, for removing an item.
This works similarly to a stack of books. The last item that you put onto the stack will be the first one that you take out.
You can read more about this data structure from this article: Data Structures 101: Stacks.
With a stack, it's easier to process (parse) the characters, which have a beginning and end, like XML tags or simple parentheses.
For example, say we have this XML code:
<element><item><sub-item>text</sub-item></item></element>
When we use the stack, the last tag we open (inner <sub-item> for example) will always be the first we need to close (if the XML is valid).
So if we use the stack, we can push the item <sub-item> when we open it, and when we need to close it we can pop it from the stack. We only need to make sure that the last item on the stack (which is always the opening tag) matches the closing one.
We will have exact same logic with parentheses.
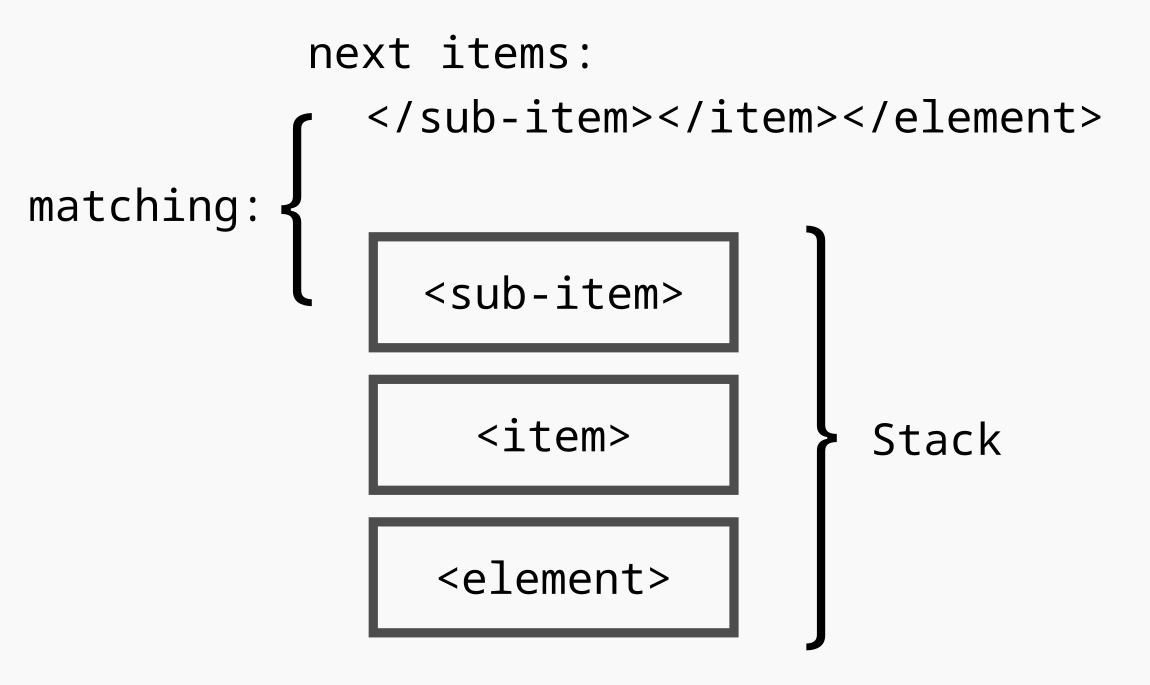
Note that if we have XML self-closing tags, we can skip them since they are open and automatically closed.
Arrays in JavaScript have both methods (push and pop), so they can be used as a Stack. But it's more convenient to create an abstraction in the form of a class, so we can add additional methods like top() and is_empty() that are easier to read.
But even if we didn't add new methods, it's always better to create abstractions like this, because it makes the code simpler and easier to read.
Most developers know common data structures and will immediately recognize them and not need to think about them. The most important thing with programming is forgetting not related stuff that are required at any given moment. The human memory is limited and can only hold about 4±1 items at the same time. You can read more about short-term memory on Wikipedia.
class Stack {
#data;
constructor() {
// creating new empty array as hiden property
this.#data = [];
}
push(item) {
// push method just use native Array::push()
// and add the item at the end of the array
this.#data.push(item);
}
len() {
// size of the Stack
return this.#data.length;
}
top() {
// sice the items are added at the end
// the top of the stack is the last item
return this.#data[this.len() - 1];
}
pop() {
// pop is similar to push and use native Array::pop()
// it removes and returns the last item in array
return this.#data.pop();
}
is_empty() {
// this comment shortcut !0 is true
// since 0 can is coerced to false
return !this.len();
}
}
The above code uses ES6 (ES2015) class and ES2022 private
properties.
The Parentheses Matching Algorithm
Now I will describe the algorithm (steps) needed to parse the parentheses.
We need a loop that will go through each token – and it's best if all other tokens are removed before processing.
When we have an opening parenthesis, we need to push that element into the stack. When we have a closing parenthesis, we need to check if the last element on the stack matches the one we are processing.
If the element is matching, we remove it from the stack. If not, it means that we have messed up parentheses, and we need to throw an exception.
When we have a closing bracket, but there is nothing on the stack, we also need to throw an exception, because there is no opening parenthesis that matches the closing one we have.
After checking all the characters (tokens), if something is left of the stack, it means that we didn't close all the parentheses. But this case is ok, because the user may be in the process of writing. So in this case, we return false, not an exception.
If the stack is empty, we return true. This means that we have a complete expression. If this was an S-Expression, we could use the parser to process it, and we would not need to worry about invalid results (of course if the parser was correct).
The Source Code
function balanced(str) {
// pairs of matching characters
const maching_pairs = {
'[': ']',
'(': ')',
'{': '}'
};
const open_tokens = Object.keys(maching_pairs);
const brackets = Object.values(maching_pairs).concat(open_tokens);
// we filter out what is not our matching characters
const tokens = tokenize(str).filter(token => {
return brackets.includes(token);
});
const stack = new Stack();
for (const token of tokens) {
if (open_tokens.includes(token)) {
stack.push(token);
} else if (!stack.is_empty()) {
// there are matching characters on the stack
const last = stack.top();
// the last opening character needs to match
// the closing bracket we have
const closing_token = maching_pairs[last];
if (token === closing_token) {
stack.pop();
} else {
// the character don't match
throw new Error(`Syntax error: missing closing ${closing_token}`);
}
} else {
// this case when we have closing token but no opening one,
// becauase the stack is empty
throw new Error(`Syntax error: not matched closing ${token}`);
}
}
return stack.is_empty();
}
The above code was implemented as part of my S-Expression parser, but the only thing I've used from that article is a function tokenize() that splits the string into tokens (where a token is a single object like number 123 or a string "hello"). If you want to process just the characters, you can use str.split(''), so the tokens would be an array of characters.
The code is much simpler than the S-Expression parser because we don't need to process all the tokens. But when we use the tokenize() function from the above article, we will be able to test input like this:
(this "))))")
The full source code (including the tokenize() function) can be found on GitHub.
Summary
You shouldn't even start processing expressions that have opening and closing characters with regular expressions. On StackOverflow there is this famous answer to this question:
RegEx match open tags except XHTML self-contained tags
Matching parentheses presents exactly the same problem, as parsing HTML. As you can see from the above code, it's a simpler problem to solve if we use the stack.
It's possible that we could write a Regular Expression that would check if the sequence of characters has matching parentheses. But it would soon get complicated if we had strings as tokens (sequence of characters), as with S-Expressions, and parentheses inside those stings should be ignored. It turns out that the solution is rather simple if we use the proper tools.
Personally, I love Regular Expressions, but you always need to decide if they're the right tool for the job.
NOTE: This article was based on an article in the Polish blog Głównie JavaScript (ang. Mostly JavaScript), with a title: Jak parować nawiasy lub inne znaki w
JavaScript?
If you like this article, you may want to follow me on Social Media: (Twitter/X and/or LinkedIn). You can also check my personal website and my new blog.