

Distributed systems generally involve the storage and exchange of huge amounts of data. Not all data is created the same, and some of it can even expire – by design.
As the Buddha said, "All conditioned things are impermanent."
In this article, we'll look at how the concept of time to live can help us with this type of data and when it makes sense to use it.
Table of Contents
- What is Time to Live (TTL) in Distributed Systems?
- How to use TTL in Message Queues (AWS SQS)
- How to use TTL in Object Storage Systems (AWS S3)
- How to use TTL in Databases (AWS DynamoDB)
- How to use TTL in Event Based Architecture
- Summary
What is Time to Live (TTL) in Distributed Systems?
TTL, as the name suggests, is the amount of time a piece of data stays relevant or stays stored in a distributed system or a component of a distributed system. A TTL may be set on any piece of data that isn't needed indefinitely.
Knowing when and when not to use a TTL can sometimes be tricky. It can also affect the way a system is designed, cost and scaling considerations. In the following sections, we learn about when and when not to use TTL.
Where does TTL make sense?
As mentioned above, it makes sense to use TTL for any piece of data that is ephemeral. Some common examples of use cases where you can set a TTL on data are:
- Cached data: Cached data is pretty much omnipresent in distributed systems. For instance, a very popular social media post's resources (image, video, audio) may be cached on a CDN (Content Delivery Network)'s servers. You don't want this data to live forever on the server, so in some cases it may make sense to add a TTL to this data, so that it is automatically removed after a certain period of time.
- Analytics Data: Most if not all large scale systems store some form of metrics that help analyze things like latency, system health, and product metrics amongst others. In a large number of cases, you wouldn't want these metrics to be stored in systems forever. Only recent data (say 60 days or 180 days) may be useful in most cases. A TTL on data in this case makes sense, especially if you have constraints on memory.
- Indexed data: Search is a feature that's ubiquitous across products. Be it social media apps, e-mail or search engines – indexed data is vital to blazing fast searches. Indexed data, however, can become stale after a while, so it makes sense for the index to expire after some time. Hence, a TTL here can be useful.
- Social media apps with short lived content: Social media apps with short lived content are extremely popular and images/videos posted are often short lived. In case these images do not need to be stored for posterity, they can benefit from a TTL being set on them. In addition to being memory efficient, it also aids privacy.
Where does TTL not make sense?
In the above section we looked at a few cases where TTL makes sense. What about cases where TTL isn't common and isn't useful? Let's look at some examples:
- Media stored for streaming platforms: Streaming platforms often use cloud storage solutions such as Amazon AWS S3 to store objects that correspond to the media they stream to customers. These forms of media are generally not ephemeral and are expected to stay on platforms for years if not decades. Since such data isn't expected to expire anytime, TTL does not make sense here.
- Bank transactions: Bank transactions produce some of the most sensitive data that are stored in cloud-based and distributed systems. For audit and book-keeping purposes, these pieces of data are generally stored for decades. So, since this data seemingly never expires, there's generally no use for a TTL here. This isn't to say that this form of data can't be moved from fast access databases/caches to slower and cheaper forms of data storage, though.
How to Use TTL in Message Queues (AWS SQS)
AWS SQS is a distributed message queuing solution that is the backbone of many versatile distributed systems across the world. Message queues can process billions of messages and are used almost universally across distributed systems around the world.
In this section, we'll look at how TTLs can be useful while we consider design options with respect to message queues.
What happens if a message queue's consumers have been backed up for several days, or messages simply haven't been consumed for a while? We have the option of setting a custom Time To Live on SQS messages.
By default, the retention period is 4 days. The maximum TTL at the time of writing is 14 days. So it's important to be aware of constraints such as these while using AWS SQS to design systems.
Note that with AWS SQS, a retention period is a set on the queue itself, and not individually for each message.
Boto is an AWS SDK for Python that enables developers to create, configure, and manage AWS services and resources programmatically. Boto is widely used for prototyping, production systems, and in general offers a user-friendly interface for accessing services like S3, EC2, and DynamoDB.
Here's a code snippet using Boto that will help you set the MessageRetentionPeriod attribute which is the formal name for TTL in this context.
sqs = boto3.client('sqs',
aws_access_key_id=your_aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name='your_region')
# Set the desired retention period in seconds
retention_period_seconds = 86400 # Example: 1 day
# Set the queue attributes
response = sqs.set_queue_attributes(
QueueUrl=your_queue_url,
Attributes={
'MessageRetentionPeriod': str(retention_period_seconds)
}
)
Visibility Timeout in Message Queues (AWS SQS)
Note that while it's tempting to think of Visibility Timeout in SQS as Time To Live, these aren't the same. Time To Live or Retention Period is different from Visibility Timeout.
Visibility timeout instead refers to a generally shorter period of time by which a message should be processed (once picked up by a consumer). If not, it is back in the SQS queue and visible to consumers again, with its receive count having been increased by one.
How to Use TTL in Object Storage Systems (AWS S3)
The all-versatile AWS S3, which is an object storage solution, gives users the ability to set a Time To Live on objects stored in S3 buckets.
S3 is extremely flexible with the way TTLs are set on objects / buckets. You can set Lifecycle rules to specify what objects or what versions of an object you'd like to remove.
Managing your storage lifecycle is a great read on the AWS Documentation website.
How to Use TTL in Databases (AWS DynamoDB)
Some types of data in databases are prime candidates to have a TTL set on them. Pieces of data such as logs and analytics data may become stale very fast, and/or they may lose utility with time.
TTL in DynamoDB provides a cost-effective approach that lets you automatically remove items that are no longer relevant. It is supported natively and can be set on the whole DynamoDB table.
Here's a code snippet that lets you set the TTL on a DynamoDB table (again, using Boto):
ddb_client = boto3.client('dynamodb')
# Enable Time To Live (TTL) on an existing DynamoDB table
ttl_response = ddb_client.update_time_to_live(
TableName=your_table_name,
TimeToLiveSpecification={
'Enabled': True,
'AttributeName': your_ttl_attribute_name
}
)
# Check for a successful status code in the response
if ttl_response['ResponseMetadata']['HTTPStatusCode'] == 200:
print("Time To Live (TTL) has been successfully enabled.")
else:
print(f"Failed to enable Time To Live (TTL)")
Here, the your_ttl_attribute_name attribute is the attribute that DynamoDB looks at to determine whether or not the item is to be deleted. The attribute is generally set to some timestamp in the future. When that timestamp is reached, DynamoDB removes the item from the table.
How to Use TTL in Event-Based Architecture
So far we've discussed Time To Live and where it can be useful. What about its implications? Lots of cloud based solutions provide notifications that can indicate that a piece of data has indeed reached it's expiration, and allow you to take actions based on the expiration of that data.
Let's look at a common use case. Suppose you have a social media app that you're building that lets users send each other ephemeral messages. Now while the contents of these messages themselves are ephemeral, you may still want to retain a log of what users a particular user exchanged messages with, even though the contents of the message (audio/video/image) may have expired.
The diagram below explains a possible architecture in a little more detail:
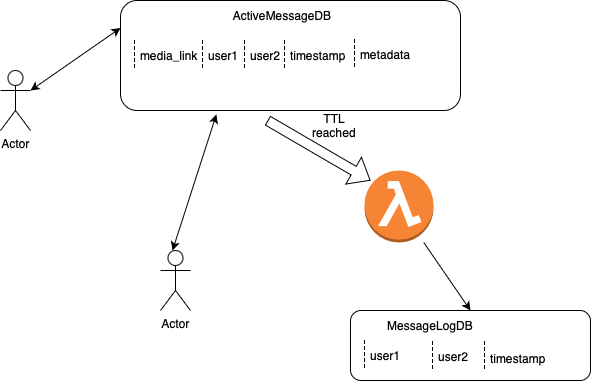 Social Media App Architecture Example
Social Media App Architecture Example
Suppose a user exchanges messages with another user. An entry corresponding to a message is stored in ActiveMessageDB which, for the purpose of simplicity, we'll suppose is a NoSQL database that stores messages.
If the app here allows for expiring messages, you could set a TTL on the entry. While the message entry itself is deleted after the TTL is reached, an event can be fired off to let a system know that the message is being deleted.
In the above diagram, the event is picked up by an AWS Lambda instance and a much smaller amount of data is written to another database MessageLogDB which isn't as frequently accessed as ActiveMessageDB. What we just saw is an instance of event-based architecture being coupled with TTL.
Summary
- TTL is the amount of time a piece of data stays relevant or stays stored in a distributed system or a component of a distributed system.
- TTL makes sense in use cases where data can be deleted, can expire, or its form can change after a certain period of time.
- TTL is popular and generally easy to set on many distributed systems offerings.
- TTL can be paired with event driven architecture to transform data.