


Artigo original: How to Use Google's Protocol Buffers in Python
Quando as pessoas que falam idiomas diferentes estão juntas e conversam, elas tentam usar uma linguagem que todos do grupo possam entender.
Para isso, todos precisam traduzir seus pensamentos, que normalmente estão na sua língua nativa, para todos do grupo. Essa "codificação e decodificação" do idioma, no entanto, leva a uma perda de eficiência, velocidade e precisão.
O mesmo conceito está presente nos sistemas do computador e em seus componentes. Por que deveríamos enviar dados em XML, JSON, ou em outra linguagem de humanos se não precisamos entender diretamente sobre o que eles estão falando? Basta que possamos traduzir para o formato da linguagem humana se precisarmos.
Os buffers de protocolo são uma forma de codificar dados antes do transporte, o que reduz de maneira eficiente os blocos de dados e, portanto, aumenta a velocidade de envio. Eles abstraem os dados em um formato neutro em termos de linguagem e plataforma.
Índice
- Por que precisamos dos buffers de protocolo?
- O que são os buffers de protocolo e como eles funcionam?
- Buffers de protocolo com o Python
- Considerações finais
Por que precisamos dos buffers de protocolo?
O objetivo inicial dos buffers de protocolos foi o de simplificar o trabalho com protocolos de solicitação/resposta. Antes do ProtoBuf, O Google usou um formato diferente para solicitação adicional de manipulação do marshaling para o envio de mensagens.
Além disso, as novas versões dos formatos anteriores exigiam que os desenvolvedores tivessem a certeza de que as novas versões fossem entendidas antes de substituir as antigas, tornando o trabalho com elas um problema.
Isso motivou a Google a projetar uma interface que resolvesse precisamente esses problemas.
Os buffers do protocolo permitem alterações no protocolo sem interferir na compatibilidade. Além disso, servidores podem transmitir os dados e executar operações de leitura nos dados sem modificar o conteúdo.
Como o formato se autodescreve, o ProtoBuf é usado como base para geração automática de código para serializadores e desserializadores.
Outro caso de uso interessante é como a Google o usa para chamadas de procedimento remoto (RPC – texto em inglês) de curta duração e para armazenar dados persistentemente na Bigtable. Devido ao seu caso de uso especifico, eles integraram interfaces de RPC aos buffers de protocolo. Isso permite a geração rápida e direta de códigos stub que podem ser usados como pontos de partidas para a implementação real (mais a respeito de ProtoBuf RPC aqui – texto em inglês).
Outros exemplos de onde o ProtoBuf pode ser usado são os dispositivos IoT conectados através de redes móveis, nas quais a quantidade de dados enviadas deve ser pequena ou para aplicações de países onde larguras de banda altas ainda são raras. O envio de cargas úteis, otimizada em formatos binários, pode levar a diferenças perceptíveis no custo e na velocidade de operação.
Usar a compactação gzip em sua comunicação por HTTPS pode melhorar ainda mais essas métricas.
O que são os buffers de protocolo e como eles funcionam?
De modo geral, os buffers de protocolo podem ser definidos como uma interface para serialização de dados estruturados. Isso define uma forma normalizada de comunicação, totalmente independente de linguagens e plataformas.
O Google anuncia o buffer de protocolo como:
Buffers de protocolo são os mecanismo extensível, neutro em termos de linguagem e de plataforma do Google para serializar dados estruturados – pense no XML, mas menor, mais rápido e mais simples. Você define como deseja que seus dados sejam estruturados uma vez…
A interface ProtoBuf descreve a estrutura de dados a serem enviados. As estruturas de cargas útil são definidas como "mensagens" no que é chamado de Proto-Arquivo. Esses arquivos sempre terminam com a extensão .proto
Por exemplo, a estrutura básica de um arquivo todolist.proto é semelhante a que vemos a seguir. Também veremos um exemplo completo na próxima seção.
syntax = "proto3";
// Não é necessário para Python, ainda deve ser declarado para evitar colisões de nomes
// no namespace Protocol Buffers e em linguagens além do Python
package protoblog;
message TodoList {
// Os elementos da lista de tarefas serão definidos aqui
...
}Esses arquivos são, então, usados para gerar classes de integração ou stubs para a linguagem de sua escolha usando geradores de código dentro do compilador protoc. A versão atual, Proto3, já suporta todas as principais linguagens de programação. A comunidade oferece suporte a muito mais implementações de código aberto de terceiros.
As classes geradas são os elementos principais dos buffers de protocolo. Eles permitem a criação de elementos instanciando novas mensagens, baseadas nos arquivos .proto, que são, então, utilizados para serialização. Veremos em detalhes como isso é feito com Python na próxima seção.
Independentemente da linguagem de serialização, as mensagens são serializadas em um formato binário, não auto descritivo, que é bastante inútil sem a definição inicial da estrutura.
Os dados binários podem, então, ser armazenados, enviados pela rede e usados de qualquer outra forma que os dados legíveis por humanos, como JSON ou XML, sejam. Após a transmissão ou armazenamento, o fluxo de bytes pode ser desserializado e restaurado usando qualquer classe protobuf compilada específica da linguagem que geramos a partir do arquivo .proto.
Usando Python como exemplo, o processo poderia ser mais ou menos assim:
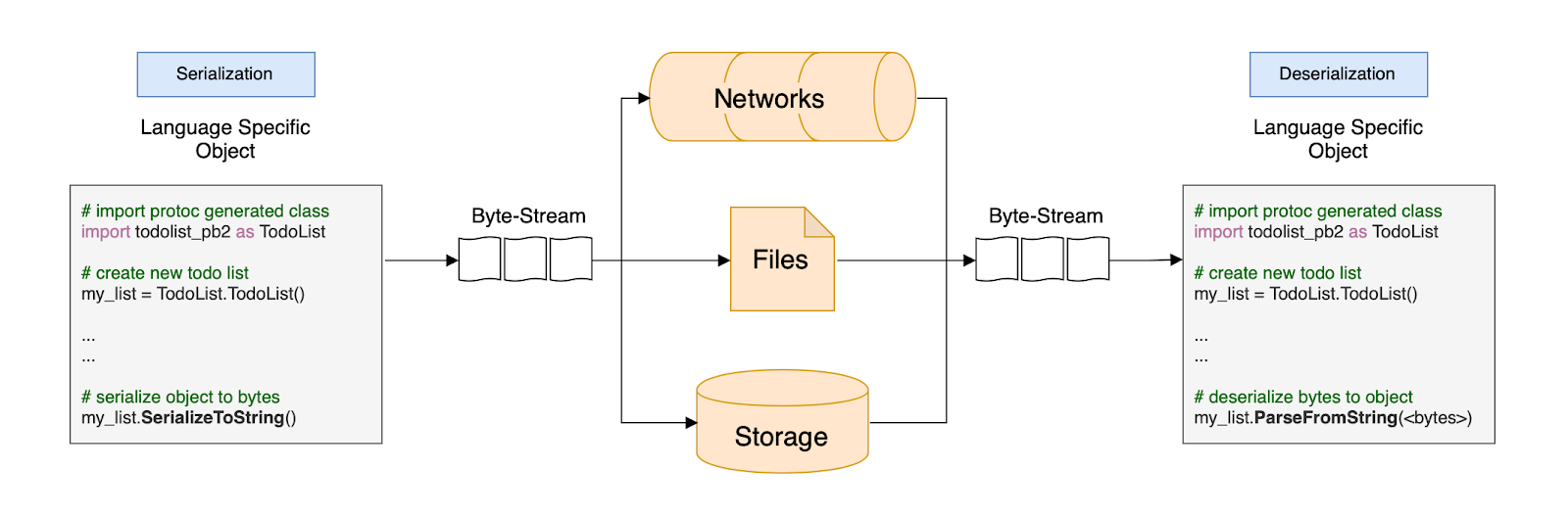
Primeiro, criamos uma lista de tarefas e a preenchemos com algumas tarefas. Essa lista de tarefas é, então, serializada e enviada pela rede, salva em um arquivo ou armazenada persistentemente em um banco de dados.
O fluxo de bytes enviado é desserializado usando o método parse de nossa classe compilada específica da linguagem.
A maioria das arquiteturas e infraestruturas atuais, especialmente microsserviços, é baseada em comunicação REST, WebSockets ou GraphQL. No entanto, quando a velocidade e a eficiência são essenciais, os RPCs de baixo nível podem fazer uma enorme diferença.
Em vez de protocolos de alta sobrecarga, podemos usar uma forma rápida e compacta de mover dados entre as diferentes entidades para o nosso serviço sem desperdiçar muitos recursos.
Por que isso ainda não é usado em todos os lugares?
Os buffers de protocolo são um pouco mais complicados do que outros formatos legíveis por humanos. Isso os torna comparativamente mais difíceis de depurar e integrar em suas aplicações.
Os tempos de iteração na engenharia também tendem a aumentar, pois as atualizações nos dados exigem a atualização dos arquivos proto antes do uso.
Considerações cuidadosas devem ser feitas, uma vez que o ProtoBuf pode ser uma solução com excesso de engenharia em muitos casos.
Que alternativas eu tenho?
Vários projetos adotam uma abordagem semelhante aos buffers de protocolo do Google.
Os Flatbuffer do Google e uma implementação de terceiros, chamada Cap’n Proto, estão mais focados em remover a etapa de análise e descompactação, que é necessária para acessar os dados reais ao usar ProtoBufs. Eles foram projetados explicitamente para aplicações de desempenho crítico, tornando-os ainda mais rápidos e mais eficientes em termos de memória do que o ProtoBuf.
Ao focar nos recursos RPC do ProtoBuf (usado com gRPC), existem projetos de outras grandes empresas como Facebook (Apache Thrift) ou Microsoft (protocolos Bond) que podem oferecer alternativas.
Buffers de protocolo com o Python
O Python já fornece algumas formas de persistência de dados usando decapagem. A decapagem é útil em aplicações que tenham somente Python. Ela não é adequada para cenários mais complexos onde está envolvido o compartilhamento de dados com outras linguagens ou a alteração de esquemas.
Os buffers de protocolo, por outro lado, são desenvolvidos exatamente para esses cenários. O arquivo .proto, que abordamos rapidamente antes, permite ao usuário gerar código para muitas linguagens suportadas.
Para compilar o arquivo .proto para a classe de linguagem de nossa escolha, usamos protoc, o compilador proto.
Se você não possui o compilador protoc instalado, existem excelentes guias sobre como fazer isso:
- MacOS/Linux (em inglês)
- Windows (em inglês)
Depois de instalar o protoc em nosso sistema, podemos usar um exemplo estendido de nossa estrutura de lista de tarefas anterior e gerar a classe de integração Python a partir dele.
syntax = "proto3";
// Não necessário para o Python, mas ainda deve ser declarado para evitar colisões de nome
// no namespace dos Buffers de Protocolo e em linguagens que não sejam o Python
package protoblog;
// O guia de estilo prefere a prefixação de valores de enum em vez de cercá-los
// com uma mensagem de fechamento
enum TaskState {
TASK_OPEN = 0;
TASK_IN_PROGRESS = 1;
TASK_POST_PONED = 2;
TASK_CLOSED = 3;
TASK_DONE = 4;
}
message TodoList {
int32 owner_id = 1;
string owner_name = 2;
message ListItems {
TaskState state = 1;
string task = 2;
string due_date = 3;
}
repeated ListItems todos = 3;
}
Vamos dar uma olhada mais detalhada na estrutura do arquivo .proto para entendê-lo. Na primeira linha do arquivo proto, definimos se estamos usando Proto2 ou 3. Nesse caso, estamos usando Proto3.
Os elementos mais incomuns dos arquivos proto são os números atribuídos a cada entidade de uma mensagem. Esses números dedicados tornam cada atributo único e são usados para identificar os campos atribuídos na saída codificada em binário.
Um conceito importante de se entender é que apenas os valores de 1 a 15 são codificados com um byte a menos (Hex), o que é útil de entender para que possamos atribuir números mais altos às entidades usadas com menos frequência. Os números não definem a ordem de codificação nem a posição do atributo fornecido na mensagem codificada.
A definição do pacote ajuda a evitar conflitos de nomes. Em Python, os pacotes são definidos por seu diretório. Portanto, fornecer um atributo de pacote não tem nenhum efeito no código em Python gerado.
Observe que os pacotes ainda devem ser declarados para evitar colisões de nomes relacionadas ao buffer de protocolo e para outras linguagens como Java.
Enumerações são listagens simples de valores possíveis para uma determinada variável. Nesse caso, definimos um Enum para os possíveis estados de cada tarefa na lista de tarefas. Veremos como usá-los daqui a pouco, quando observarmos o uso em Python.
Como podemos ver no exemplo, também podemos aninhar mensagens dentro de mensagens. Se quisermos, por exemplo, ter uma lista de todos os dados associados a uma determinada lista de tarefas, podemos usar a palavra-chave repeated, que é comparável a arrays de tamanho dinâmico .
Para gerar código de integração utilizável, usamos o compilador proto, que compila um determinado arquivo .proto em classes de integração específicas da linguagem. No nosso caso, usamos o argumento --python-out para gerar código específico em Python.
protoc -I=. --python_out=. ./todolist.proto
No terminal, invocamos o compilador do protocolo com três parâmetros:
- -I: define o diretório onde procuramos quaisquer dependências (usamos
., que é o diretório atual) - --python_out: define o local onde queremos gerar uma classe de integração do Python (novamente usamos
., que é o diretório atual) - O último parâmetro sem nome define o arquivo .proto que será compilado (usamos o arquivo todolist.proto, no diretório atual)
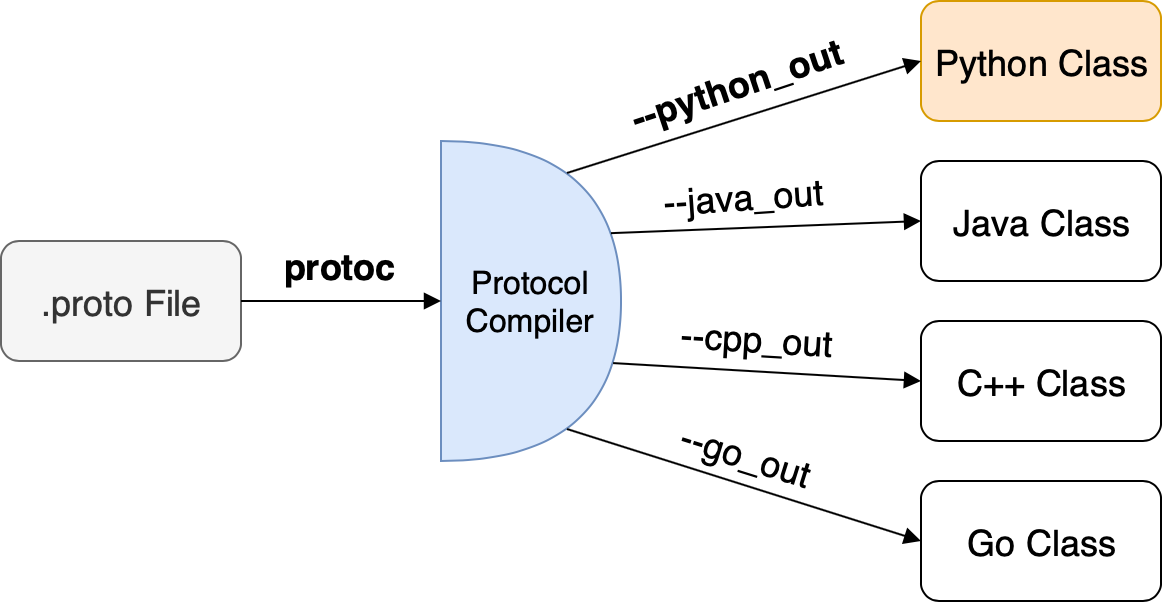
Isso cria um novo arquivo em Python chamado <nome_do_arquivo_proto>_pb2.py. No nosso caso, é todolist_pb2.py. Ao examinar esse arquivo mais de perto, não seremos capazes de entender muito sobre sua estrutura imediatamente.
Isso ocorre porque o gerador não produz elementos de acesso direto aos dados, mas abstrai ainda mais a complexidade usando metaclasses e descritores para cada atributo. Eles descrevem como uma classe se comporta em vez de cada instância dessa classe.
A parte mais interessante é como usar esse código gerado para criar, construir e serializar dados. Uma integração direta feita com nossa classe gerada recentemente é vista a seguir:
import todolist_pb2 as TodoList
my_list = TodoList.TodoList()
my_list.owner_id = 1234
my_list.owner_name = "Tim"
first_item = my_list.todos.add()
first_item.state = TodoList.TaskState.Value("TASK_DONE")
first_item.task = "Teste de ProtoBuf para o Python"
first_item.due_date = "31.10.2019"
print(my_list)Ele apenas cria uma lista de tarefas e adiciona um item a ela. Em seguida, imprimimos o próprio elemento da lista de tarefas e podemos ver a versão não binária e não serializada dos dados que acabamos de definir em nosso script.
owner_id: 1234
owner_name: "Tim"
todos {
state: TASK_DONE
task: "Teste de ProtoBuf para o Python"
due_date: "31.10.2019"
}Cada classe Protocol Buffer possui métodos para ler e escrever mensagens usando uma codificação específica do buffer de protocolo (texto em inglês), que codifica mensagens em formato binário. Esses dois métodos são SerializeToString() e ParseFromString().
import todolist_pb2 as TodoList
my_list = TodoList.TodoList()
my_list.owner_id = 1234
# ...
with open("./serializedFile", "wb") as fd:
fd.write(my_list.SerializeToString())
my_list = TodoList.TodoList()
with open("./serializedFile", "rb") as fd:
my_list.ParseFromString(fd.read())
print(my_list)No exemplo de código acima, escrevemos a string serializada de bytes em um arquivo usando os sinalizadores wb.
Como já escrevemos o arquivo, podemos ler o conteúdo e analisá-lo usando ParseFromString. ParseFromString chama uma nova instância de nossa classe serializada usando os sinalizadores rb e a analisa.
Se serializarmos essa mensagem e se a imprimimos no console, obteremos a representação de bytes semelhante a esta.
b'\x08\xd2\t\x12\x03Tim\x1a(\x08\x04\x12\x18Teste de ProtoBuf para o Python\x1a\n31.10.2019'
Observe o b na frente das aspas. Isso indica que a string a seguir é composta de octetos de bytes em Python.
Se compararmos isso diretamente com, por exemplo, XML, podemos ver o impacto que a serialização do ProtoBuf tem no tamanho.
<todolist>
<owner_id>1234</owner_id>
<owner_name>Tim</owner_name>
<todos>
<todo>
<state>TASK_DONE</state>
<task>Teste de ProtoBuf para o Python</task>
<due_date>31.10.2019</due_date>
</todo>
</todos>
</todolist>A representação JSON, ajustada, ficaria assim.
{
"todoList": {
"ownerId": "1234",
"ownerName": "Tim",
"todos": [
{
"state": "TASK_DONE",
"task": "Teste de ProtoBuf para o Python",
"dueDate": "31.10.2019"
}
]
}
}Julgando os diferentes formatos apenas pelo número total de bytes utilizados, ignorando a memória necessária para o overhead de formatação, podemos obviamente ver a diferença.
Além da memória utilizada para os dados, no entanto, também temos 12 bytes extras no ProtoBuf para formatação de dados serializados. Comparando isso com XML, temos 171 bytes extras em XML para formatar dados serializados.
Sem um esquema, precisamos de 136 bytes extras em JSON para formatar dados serializados.
Se estamos falando de milhares de mensagens enviadas pela rede ou armazenadas em disco, o ProtoBuf pode fazer a diferença.
Há uma questão importante, no entanto. A plataforma Auth0.com criou uma extensa comparação entre ProtoBuf e JSON. Ela mostra que, quando comprimido, a diferença de tamanho entre os dois pode ser mínima (apenas cerca de 9%).
Se você estiver interessado nos números exatos, consulte o artigo completo (em inglês), que fornece uma análise detalhada de vários fatores como tamanho e velocidade.
Uma observação interessante é que cada tipo de dados possui um valor padrão. Se os atributos não forem atribuídos ou alterados, eles manterão os valores padrão. No nosso caso, se não alterarmos o TaskState de um ListItem, ele terá o estado "TASK_OPEN" por padrão. A vantagem significativa disso é que os valores não definidos não são serializados, economizando espaço adicional.
Se, por exemplo, alterarmos o estado da nossa tarefa de TASK_DONE para TASK_OPEN, ela não será serializada.
owner_id: 1234
owner_name: "Tim"
todos {
task: "Teste de ProtoBuf para o Python"
due_date: "31.10.2019"
}b'\x08\xd2\t\x12\x03Tim\x1a&\x12\x18Teste de ProtoBuf para o Python\x1a\n31.10.2019'
Considerações finais
Como vimos, os buffers de protocolo são bastante úteis quando se trata de velocidade e eficiência ao trabalhar com dados. Devido à sua natureza poderosa, pode levar algum tempo para se acostumar com o sistema ProtoBuf, embora a sintaxe para definir novas mensagens seja simples.
Como última observação, quero salientar que houve/há discussões em andamento sobre a "utilidade" dos buffers de protocolo para aplicações regulares. Eles foram desenvolvidos explicitamente para problemas que o Google tinha em mente.
Se você tiver alguma dúvida ou feedback, sinta-se à vontade para entrar em contato com o autor em qualquer mídia social, como o Twitter ou por e-mail.