


Artigo original: The Linux Command Handbook – Learn Linux Commands for Beginners
Este manual de comandos do Linux apresentará os 60 comandos principais que você precisará como desenvolvedor. Cada comando inclui código de exemplo e dicas sobre quando usá-lo.
Este Manual de Comando do Linux segue a regra 80/20: você aprenderá 80% de um tópico em cerca de 20% do tempo gasto estudando-o.
Acho que essa abordagem oferece uma visão geral completa.
Este manual não tenta cobrir tudo relacionado ao Linux e seus comandos. Ele se concentra nos pequenos comandos principais que você usará 80% ou 90% do tempo e tenta simplificar o uso dos mais complexos.
Todos esses comandos funcionam em Linux, macOS, WSL e em qualquer lugar onde você tenha um ambiente UNIX.
Espero que o conteúdo deste manual o ajude a alcançar o que deseja: familiarizar-se com o Linux.
Você pode marcar esta página em seu navegador para poder consultar este manual no futuro.
Você pode fazer o download deste manual em PDF/ePUB/Mobi gratuitamente.
Aproveite!
Índice
- Introdução ao Linux e shells
- O comando
manno Linux - O comando
lsno Linux - O comando
cdno Linux - O comando
pwdno Linux - O comando
mkdirno Linux - O comando
rmdirno Linux - O comando
mvno Linux - O comando
cpno Linux - O comando
openno Linux - O comando
touchno Linux - O comando
findno Linux - O comando
lnno Linux - O comando
gzipno Linux - O comando
gunzipno Linux - O comando
tarno Linux - O comando
aliasno Linux - O comando
catno Linux - O comando
lessno Linux - O comando
tailno Linux - O comando
wcno Linux - O comando
grepno Linux - O comando
sortno Linux - O comando
uniqno Linux - O comando
diffno Linux - O comando
echono Linux - O comando
chownno Linux - O comando
chmodno Linux - O comando
umaskno Linux - O comando
duno Linux - O comando
dfno Linux - O comando
basenameno Linux - O comando
dirnameno Linux - O comando
psno Linux - O comando
topno Linux - O comando
killno Linux - O comando
killallno Linux - O comando
jobsno Linux - O comando
bgno Linux - O comando
fgno Linux - O comando
typeno Linux - O comando
whichno Linux - O comando
nohupno Linux - O comando
xargsno Linux - O comando do editor
vimno Linux - O comando do editor
emacsno Linux - O comando do editor
nanono Linux - O comando
whoamino Linux - O comando
whono Linux - O comando
suno Linux - O comando
sudono Linux - O comando
passwdno Linux - O comando
pingno Linux - O comando
tracerouteno Linux - O comando
clearno Linux - O comando
historyno Linux - O comando
exportno Linux - O comando
crontabno Linux - O comando
unameno Linux - O comando
envno Linux - O comando
printenvno Linux - Conclusão
Introdução ao Linux e shells
O que é Linux?
Linux é um sistema operacional, como o macOS ou Windows.
É também o sistema operacional de código aberto mais popular, oferecendo muita liberdade.
Ele alimenta a grande maioria dos servidores que compõem a Internet. É a base sobre a qual tudo é construído, mas não apenas isso. O Android é baseado em (uma versão modificada do) Linux.
O "núcleo" do Linux (chamado de kernel) nasceu em 1991 na Finlândia e percorreu um longo caminho desde seu início humilde. Passou a ser o kernel do Sistema Operacional GNU, criando a dupla GNU/Linux.
Há uma coisa no Linux que empresas como Microsoft, Apple e Google nunca poderão oferecer: a liberdade de fazer o que quiser com seu computador.
Na verdade, elas estão indo na direção oposta, construindo jardins murados, especialmente no lado dos dispositivos móveis.
Linux é a liberdade definitiva.
É desenvolvido por voluntários, alguns pagos por empresas que dependem dele, outros de maneira independente. Não existe, porém, uma única empresa comercial que possa ditar o que acontece no Linux ou as prioridades do projeto.
Você também pode usar o Linux como seu computador diário. Eu uso o macOS porque gosto muito das aplicações e do design (e também fui desenvolvedor de aplicações para iOS e Mac). Antes de usar o macOS, no entanto, eu usei o Linux como sistema operacional principal do meu computador.
Ninguém pode ditar quais aplicações você pode executar ou "ligar para casa" com aplicações que rastreiam você, sua posição e muito mais.
O Linux também é especial porque não existe apenas "um Linux", como é o caso do Windows ou do macOS. Em vez disso, temos distribuições.
Uma "distro" é feita por uma empresa ou organização e empacota o núcleo do Linux com programas e ferramentas adicionais.
Por exemplo, você tem o Debian, o Red Hat e o Ubuntu, provavelmente as distribuições mais populares.
Existem, porém, muitas, muitas mais. Você também pode criar sua própria distribuição, mas, provavelmente, usará uma popular que tenha muitos usuários e uma comunidade de pessoas ao seu redor. Isso permite que você faça o que precisa sem perder muito tempo reinventando a roda e descobrindo respostas para problemas comuns.
Alguns computadores desktop e laptops vêm com Linux pré-instalado. Você também pode instalá-lo em seu computador Windows ou Mac.
Você, no entanto, não precisa interromper seu computador existente apenas para ter uma ideia de como o Linux funciona.
Eu não tenho um computador Linux.
Se você usa um Mac, você só precisa saber que o macOS é um sistema operacional UNIX. Ele compartilha muitas das mesmas ideias e software que um sistema GNU/Linux usa, porque GNU/Linux é uma alternativa gratuita ao UNIX.
UNIX é um termo genérico que agrupa muitos sistemas operacionais usados em grandes corporações e instituições, a partir da década de 1970
O terminal do macOS dá acesso exatamente aos mesmos comandos que descreverei no restante deste manual.
A Microsoft tem um subsistema oficial do Windows para Linux que você pode (e deve!) instalar no Windows. Isso dará a você a capacidade de executar o Linux de uma maneira muito fácil em seu PC.
Na grande maioria das vezes, porém, você executará um computador Linux na nuvem por meio de um VPS (Virtual Private Server) como o DigitalOcean.
O que é um shell Linux?
Um shell é um interpretador de comandos que expõe uma interface para o usuário trabalhar com o sistema operacional subjacente.
Ele permite executar operações usando texto e comandos e fornece aos usuários recursos avançados, como a capacidade de criar scripts.
Isso é importante: os shells permitem que você execute as coisas de uma maneira mais otimizada do que uma GUI (Interface Gráfica do Usuário) poderia permitir. As ferramentas de linha de comando podem oferecer muitas opções de configuração diferentes sem serem muito complexas de usar.
Existem muitos tipos diferentes de shells. Este artigo se concentra em shells Unix, aqueles que você encontrará comumente em computadores Linux e macOS.
Muitos tipos diferentes de shells foram criados para esses sistemas ao longo do tempo. Alguns deles dominam o espaço: Bash, Csh, Zsh, Fish e muitos mais!
Todas os shells são originários de Bourne Shell, chamada sh. "Bourne" porque seu criador foi Steve Bourne.
Bash significa Bourne-again shell. O sh era proprietário e não de código aberto, e o Bash foi criado em 1989 para criar uma alternativa livre para o projeto GNU e a Free Software Foundation. Como os projetos tinham que pagar para usar o shell Bourne, o Bash se tornou muito popular.
Se você usa um Mac, tente abrir o terminal Mac. Por padrão, ele executa ZSH (ou, pré-Catalina, o Bash).
Você pode configurar seu sistema para executar qualquer tipo de shell – por exemplo, eu uso o shell Fish.
Cada shell tem seus próprios recursos exclusivos e uso avançado, mas todos compartilham uma funcionalidade comum: permitem executar programas e podem ser programados.
No restante deste manual, veremos em detalhes os comandos mais comuns que você utilizará.
O comando man no Linux
O primeiro comando que apresentarei ajudará você a entender todos os outros comandos.
Toda vez que não sei como usar um comando, digito man <comando> para obter o manual:
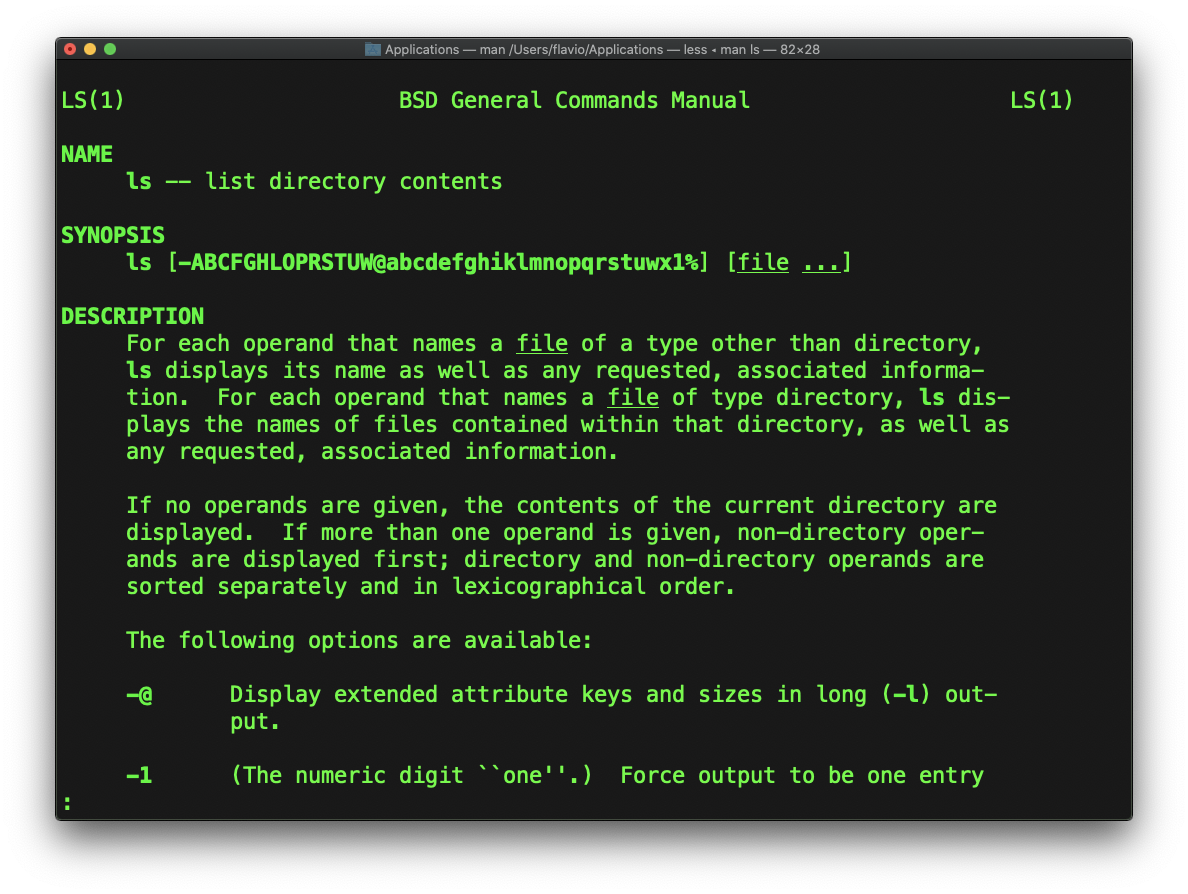
Esta é uma página man (de manual). As páginas de manual são uma ferramenta essencial para aprender como desenvolvedor. Elas contêm tanta informação que, às vezes, é quase demais. A captura de tela acima é apenas uma das 14 telas de explicação do comando ls .
Na maioria das vezes, quando preciso aprender um comando rapidamente, uso este site chamado páginas tldr: https://tldr.sh. É um comando que você pode instalar e executar assim: tldr <comando>. Ele fornece uma visão geral muito rápida de um comando, com alguns exemplos úteis de cenários de uso comuns:
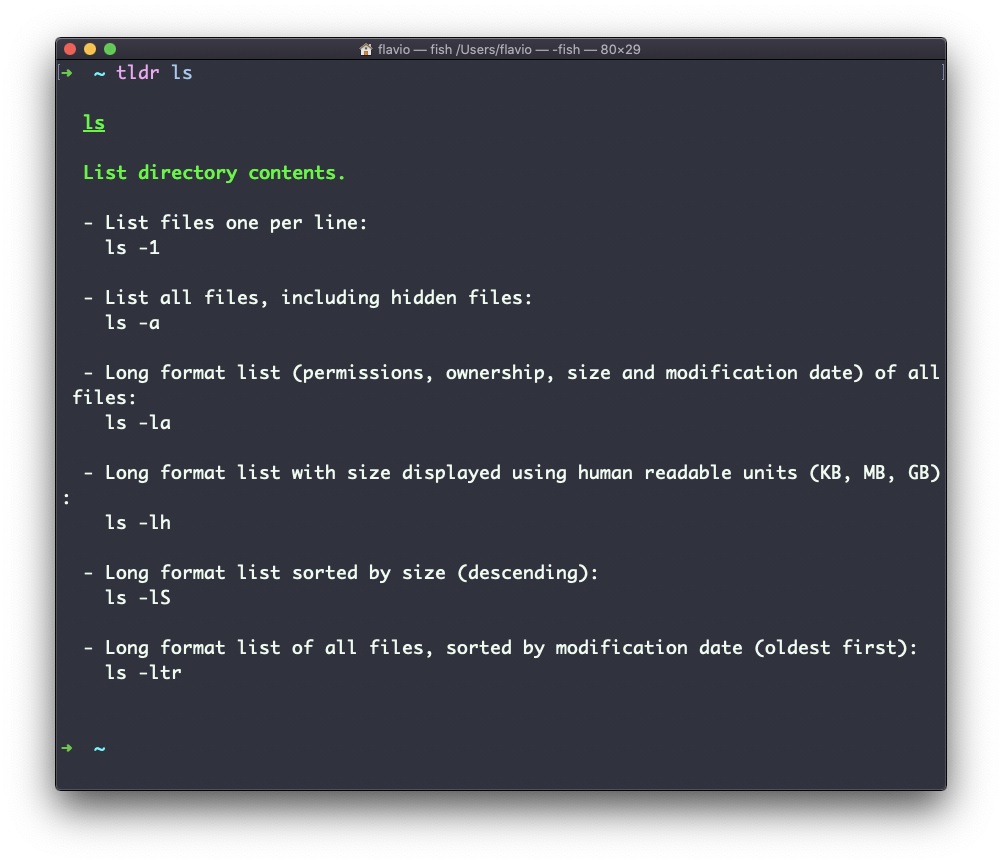
Ele não é um substituto para o man, mas uma ferramenta útil para evitar de se perder na enorme quantidade de informações presentes em uma página man. Em seguida, você pode usar a página man para explorar todas as diferentes opções e parâmetros que você pode usar em um comando.
O comando ls no Linux
Dentro de uma pasta você pode listar todos os arquivos que a pasta contém usando o comando ls :
lsSe você adicionar um nome ou caminho de pasta, o conteúdo dessa pasta será impresso:
ls /bin
O ls aceita muitas opções. Uma das minhas combinações favoritas é a -al. Tente:
ls -al /bin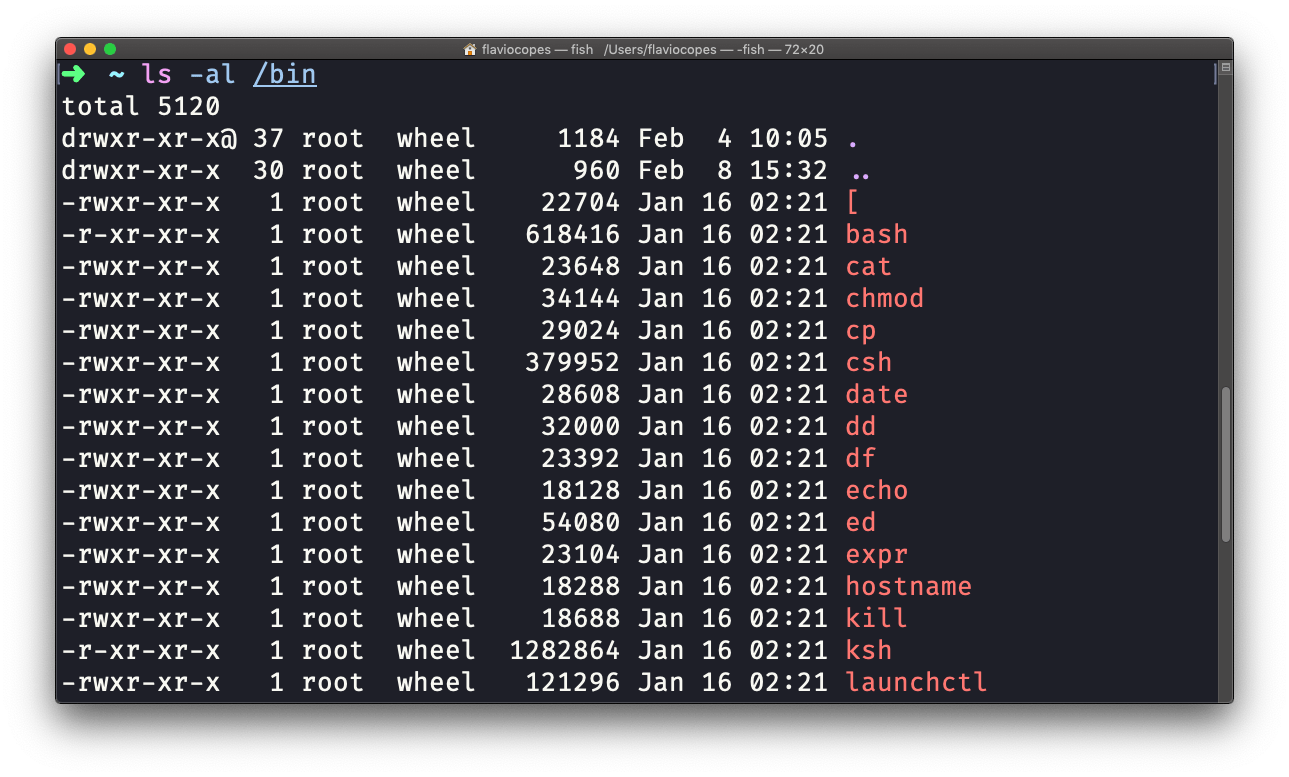
Comparado ao comando ls simples, ele retorna muito mais informações.
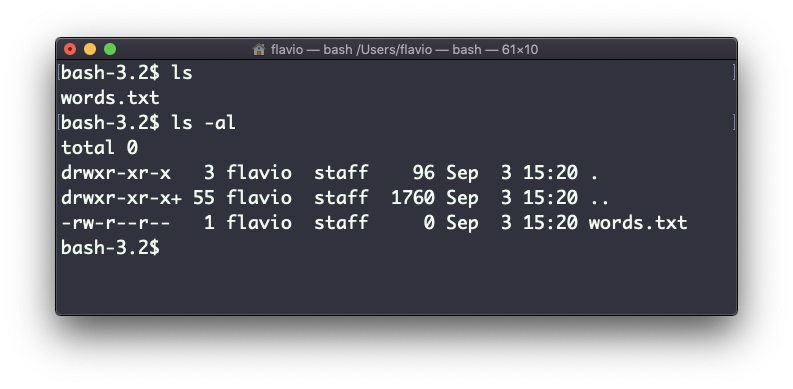
Você tem, da esquerda para a direita:
- as permissões de arquivo (e se o seu sistema suportar ACLs, você também receberá um sinalizador de ACL)
- o número de links para esse arquivo
- o dono do arquivo
- o grupo do arquivo
- o tamanho do arquivo em bytes
- a data e hora da última modificação do arquivo
- o nome do arquivo
Esse conjunto de dados é gerado pela opção l. A opção a também mostra os arquivos ocultos.
Arquivos ocultos são arquivos que começam com um ponto (.).
O comando cd no Linux
Depois de ter uma pasta, você pode movê-la usando o comando cd. cd significa alterar diretório (do inglês, change directory). Você o invoca especificando uma pasta para a qual mover. Você pode especificar um nome de pasta ou um caminho completo.
Exemplo:
mkdir fruits
cd fruits Agora, você está na pasta fruits.
Você pode usar o caminho especial .. para indicar a pasta pai:
cd .. #retorno à pasta paiO caractere # indica o início do comentário, que dura toda a linha após ser encontrado.
Você pode usar o comando cd junto do caminho especial para formar um caminho:
mkdir fruits
mkdir cars
cd fruits
cd ../carsExiste outro indicador de caminho especial, que é o ., que indica a pasta atual.
Você também pode usar caminhos absolutos, que começam na pasta raiz /:
cd /etcO comando pwd no Linux
Sempre que você se sentir perdido no sistema de arquivos, chame o comando pwd para saber onde você está:
pwdEle imprimirá o caminho da pasta atual.
O comando mkdir no Linux
Você pode criar pastas usando o comando mkdir:
mkdir fruitsVocê pode criar várias pastas com um comando:
mkdir dogs carsVocê também pode criar várias pastas aninhadas adicionando a opção -p:
mkdir -p fruits/applesAs opções nos comandos UNIX geralmente assumem esse formato. Você os adiciona logo após o nome do comando e eles mudam o comportamento do comando. Muitas vezes, você também pode combinar várias opções.
Você pode descobrir quais opções um comando suporta digitando man <nome_do_comando>. Tente agora com man mkdir, por exemplo, (pressione a tecla q para sair da página de manual). As páginas de manual são a incrível ajuda integrada para UNIX.
O comando rmdir no Linux
Assim como você pode criar uma pasta usando mkdir, você pode excluir uma pasta usando rmdir:
mkdir fruits
rmdir fruitsVocê também pode excluir várias pastas de uma vez:
mkdir fruits cars
rmdir fruits cars A pasta que você exclui deve estar vazia.
Para excluir pastas com arquivos, usaremos o comando rm mais genérico, que exclui arquivos e pastas, usando a opção -rf:
rm -rf fruits carsTenha cuidado, pois esse comando não pede confirmação e removerá imediatamente tudo o que você solicitar.
Não há bin ao remover arquivos da linha de comando e recuperar arquivos perdidos pode ser difícil.
O comando mv no Linux
Depois de ter um arquivo, você pode movê-lo usando o comando mv. Você especifica o caminho atual do arquivo e seu novo caminho:
touch test
mv pear new_pearO arquivo pear é movido para new_pear. É assim que você renomeia arquivos e pastas.
Se o último parâmetro for uma pasta, o arquivo localizado no caminho do primeiro parâmetro será movido para essa pasta. Nesse caso, você pode especificar uma lista de arquivos e todos eles serão movidos no caminho da pasta identificado pelo último parâmetro:
touch pear
touch apple
mkdir fruits
mv pear apple fruits #pear e apple são movidos para a pasta fruitsO comando cp no Linux
Você pode copiar um arquivo usando o comando cp:
touch test
cp apple another_applePara copiar pastas você precisa adicionar a opção -r para copiar recursivamente todo o conteúdo da pasta:
mkdir fruits
cp -r fruits carsO comando open no Linux
O comando open permite abrir um arquivo usando esta sintaxe:
open <nome_do_arquivo>Você também pode abrir um diretório, que no macOS abre o aplicativo Finder com o diretório atual aberto:
open <nome_do_diretório> Eu uso isso o tempo todo para abrir o diretório atual:
open .O símbolo especial.aponta para o diretório atual, enquanto..aponta para o diretório pai
O mesmo comando também pode ser usado para executar uma aplicação:
open <nome_da_aplicação>O comando touch no Linux
Você pode criar um arquivo vazio usando o comando touch:
touch appleSe o arquivo já existir, ele será aberto no modo de gravação e o carimbo de data/hora do arquivo será atualizado.
O comando find no Linux
O comando find pode ser usado para localizar arquivos ou pastas que correspondam a um padrão de pesquisa específico. Ele pesquisa recursivamente.
Vamos aprender como usá-lo por meio de um exemplo.
Encontre todos os arquivos na árvore atual que possuem a extensão .js e imprima o caminho relativo de cada arquivo correspondente:
find . -name '*.js'É importante usar aspas em torno de caracteres especiais como * para evitar que o shell os interprete.
Encontre diretórios na árvore atual que correspondam ao nome "src":
find . -type d -name srcUse -type f para pesquisar apenas arquivos ou -type l para pesquisar apenas links simbólicos.
-name diferencia maiúsculas de minúsculas. Use -iname para realizar uma pesquisa sem distinção entre maiúsculas e minúsculas.
Você pode pesquisar em várias árvores raiz:
find folder1 folder2 -name filename.txtEncontre diretórios na árvore atual que correspondam ao nome "node_modules" ou 'public':
find . -type d -name node_modules -or -name publicVocê também pode excluir um caminho da pesquisa usando -not -path:
find . -type d -name '*.md' -not -path 'node_modules/*'Você pode pesquisar arquivos que contenham mais de 100 caracteres (bytes):
find . -type f -size +100cPesquise arquivos maiores que 100 KB, mas menores que 1 MB:
find . -type f -size +100k -size -1MPesquise arquivos editados há mais de 3 dias:
find . -type f -mtime +3Pesquise arquivos editados nas últimas 24 horas:
find . -type f -mtime -1Você pode excluir todos os arquivos que correspondem a uma pesquisa adicionando a opção -delete. Isso exclui todos os arquivos editados nas últimas 24 horas:
find . -type f -mtime -1 -deleteVocê pode executar um comando em cada resultado da pesquisa. No exemplo, executamos cat para imprimir o conteúdo do arquivo:
find . -type f -exec cat {} \;Observe a terminação \;. {} é preenchido com o nome do arquivo em tempo de execução.
O comando ln no Linux
O comando ln faz parte dos comandos do sistema de arquivos Linux.
É usado para criar links. O que é um link? É como um ponteiro para outro arquivo ou um arquivo que aponta para outro arquivo. Você deve estar familiarizado com os atalhos do Windows. Eles são semelhantes.
Temos 2 tipos de links: hard links e soft links.
Hard links
Hard links raramente são usados. Eles têm algumas limitações: você não pode vincular a diretórios e não pode vincular a sistemas de arquivos externos (discos).
Um hard link é criado usando a seguinte sintaxe:
ln <original> <link>Por exemplo, digamos que você tenha um arquivo chamado recipes.txt (um arquivo de texto com receitas). Você pode criar um hard link para ele usando:
ln recipes.txt newrecipes.txtO novo hard link que você criou é indistinguível de um arquivo normal:
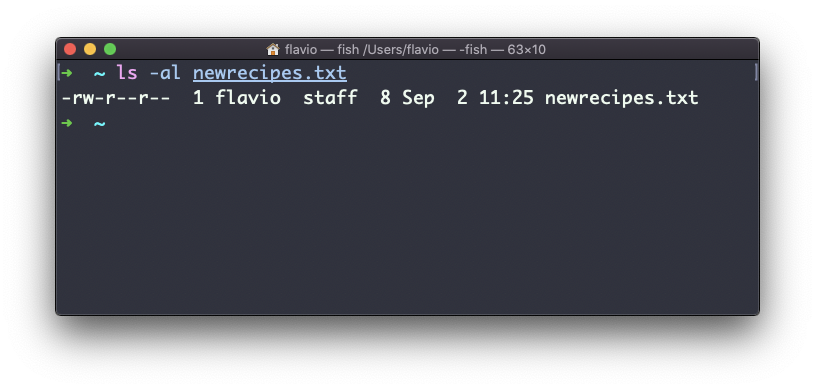
Agora, sempre que você editar qualquer um desses arquivos, o conteúdo será atualizado para ambos.
Se você excluir o arquivo original, o link ainda conterá o conteúdo do arquivo original, pois ele não será removido até que haja um hard link apontando para ele.
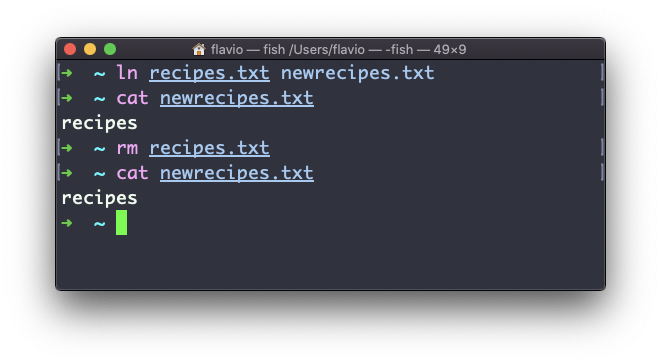
Soft links
Soft links são diferentes. Eles são mais poderosos porque você pode vincular a outros sistemas de arquivos e diretórios. Lembre-se, porém, de que, quando o original for removido, o link será quebrado.
Você cria links virtuais usando a opção -s de ln:
ln -s <original> <link>Por exemplo, digamos que você tenha um arquivo chamado recipes.txt. Você pode criar um soft link para ele usando:
ln -s recipes.txt newrecipes.txtNesse caso, você pode ver que há um sinalizador l especial ao listar o arquivo usando ls -al. O nome do arquivo tem um @ no final e também tem uma cor diferente se você tiver as cores ativadas:
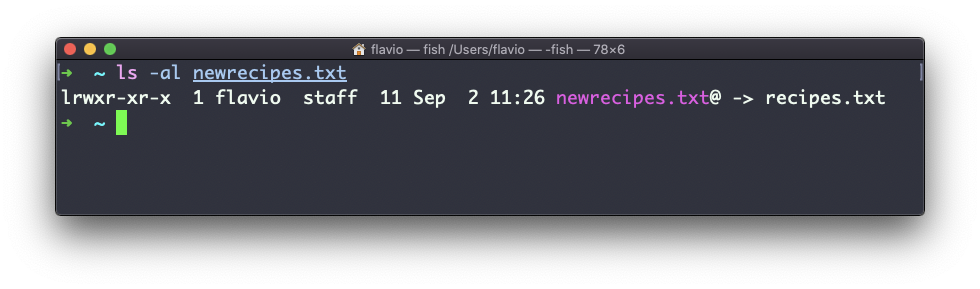
Agora, se você excluir o arquivo original, os links serão quebrados e o shell informará "Esse arquivo ou diretório não existe" se você tentar acessá-lo:
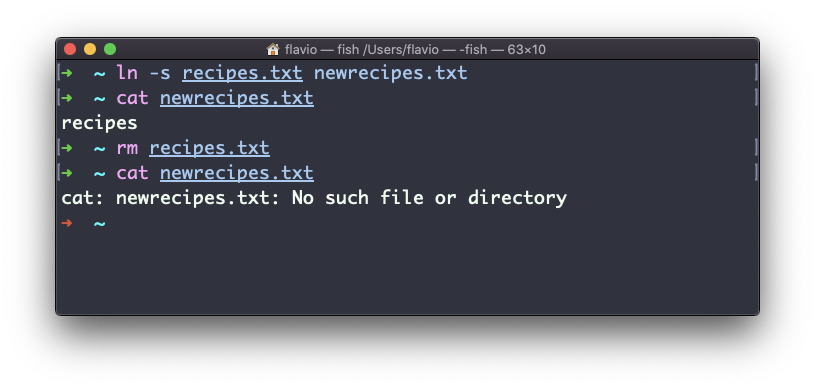
O comando gzip no Linux
Você pode compactar um arquivo usando o protocolo de compactação gzip denominado LZ77 usando o comando gzip .
Aqui está o uso mais simples:
gzip filenameIsso compactará o arquivo e acrescentará uma extensão .gz a ele. O arquivo original é excluído.
Para evitar isso, você pode usar a opção -c e usar o redirecionamento de saída para gravar a saída no arquivo filename.gz :
gzip -c filename > filename.gzA opção -c especifica que a saída estará no fluxo de saída padrão, deixando o arquivo original intacto.Você também pode usar a opção -k:
gzip -k filenameExistem vários níveis de compressão. Quanto maior a compactação, mais tempo levará para compactar (e descompactar). Os níveis variam de 1 (compactação mais rápida e pior) a 9 (compactação mais lenta e melhor) e o padrão é 6.
Você pode escolher um nível específico com a opção: -<NUMBER>:
gzip -1 filenameVocê pode compactar vários arquivos listando-os:
gzip filename1 filename2Você pode compactar todos os arquivos em um diretório, recursivamente, usando a opção -r :
gzip -r a_folderA opção -v imprime as informações de porcentagem de compactação. Aqui está um exemplo de uso junto com a opção -k (keep):
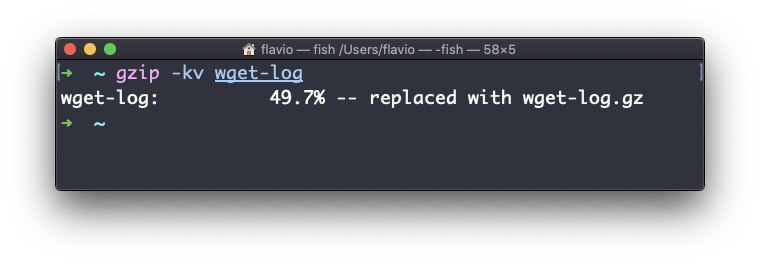
gzip também pode ser usado para descompactar um arquivo, usando a opção -d :
gzip -d filename.gzO comando gunzip no Linux
O comando gunzip basicamente equivalente ao comando gzip, exceto que a opção -d está sempre habilitada por padrão.
O comando pode ser invocado desta maneira:
gunzip filename.gzIsso compactará e removerá a extensão .gz colocando o resultado no arquivo com filename . Se esse arquivo existir, ele será sobrescrito.
Você pode extrair para um nome de arquivo diferente usando o redirecionamento de saída usando a opção -c :
gunzip -c filename.gz > anotherfilenameO comando tar no Linux
O comando tar é usado para criar um arquivo, agrupando vários arquivos em um único arquivo.
Seu nome vem do passado e significa arquivo em fita (na época em que os arquivos eram armazenados em fitas – em inglês, Tape ARchive).
Este comando cria um arquivo chamado archive.tar com o conteúdo de file1 e file2:
tar -cf archive.tar file1 file2 A opçãocsignifica criar. A opçãofé usada para gravar no arquivo.
Para extrair arquivos de um arquivo na pasta atual, use:
tar -xf archive.tarA opção x significa extrair.Para extraí-los para um diretório específico, use:
tar -xf archive.tar -C nome_do_diretórioVocê também pode simplesmente listar os arquivos contidos em um arquivo:
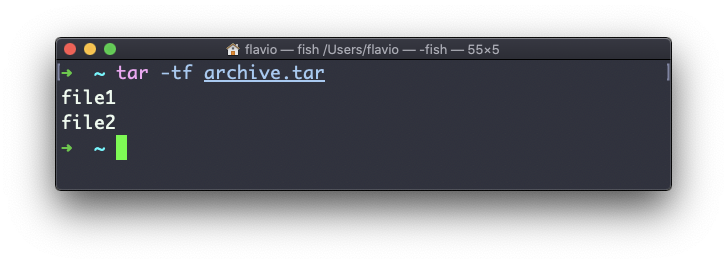
tar é frequentemente usado para criar um arquivo compactado, compactando o arquivo.
Isso é feito usando a opção z :
tar -czf archive.tar.gz file1 file2É como criar um arquivo tar e executar gzip nele.
Para desarquivar um arquivo compactado com gzip, você pode usar gunzip, ou gzip -d, e depois desarquivá-lo. tar -xf, no entanto, reconhecerá que é um arquivo compactado e fará isso por você:
tar -xf archive.tar.gzO comando alias no Linux
É comum sempre executar um programa com um conjunto de opções que você gosta de usar.
Por exemplo, pegue o comando ls. Por padrão, imprime muito pouca informação:
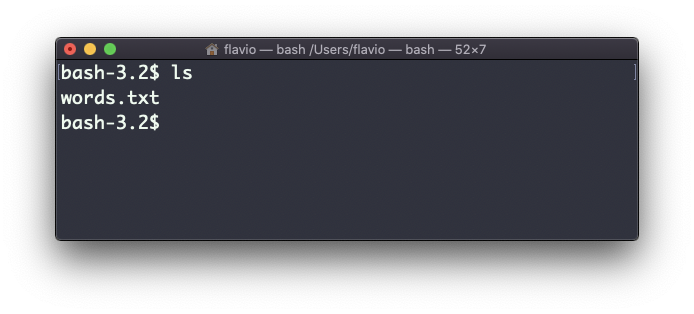
Se, no entanto, você usar a opção -al, imprimirá algo mais útil, incluindo a data de modificação do arquivo, o tamanho, o proprietário e as permissões. Ele também listará os arquivos ocultos (arquivos que começam com .):
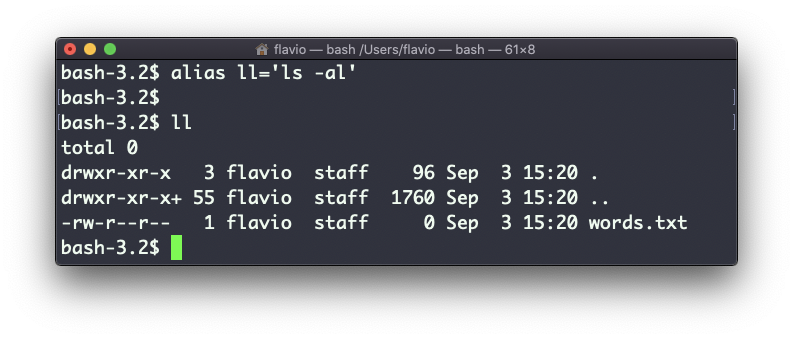
Você pode criar um outro comando – por exemplo, gosto de chamá-lo de ll, que é um alias para ls -al.
Você faz assim:
alias ll='ls -al'Depois de fazer isso, você pode chamar ll como se fosse um comando normal do UNIX:
Chamar alias sem qualquer opção listará os aliases definidos:
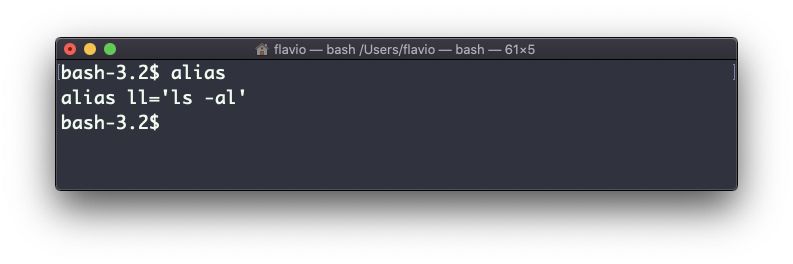
O alias funcionará até que a sessão do terminal seja fechada.
Para torná-lo permanente, você precisa adicioná-lo à configuração do shell. Pode ser ~/.bashrc ou ~/.profile ou ~/.bash_profile se você usar o shell Bash, dependendo do caso de uso.
Tenha cuidado com aspas se você tiver variáveis no comando: se você usar aspas duplas, a variável será resolvida no momento da definição. Se você usar aspas simples, ela será resolvida no momento da invocação. Os dois comandos abaixo são diferentes:
alias lsthis="ls $PWD"
alias lscurrent='ls $PWD'$PWD refere-se à pasta atual em que o shell está. Se você navegar para uma nova pasta, lscurrent listará os arquivos na nova pasta, enquanto lsthis ainda listará os arquivos na pasta onde você estava quando definiu o alias.
O comando cat no Linux
Semelhante a tail em alguns aspectos, temos o cat. A diferença está no fato de que cat também pode adicionar conteúdo a um arquivo. Isso o torna superpoderoso.
Em seu uso mais simples, cat imprime o conteúdo de um arquivo na saída padrão:
cat fileVocê pode imprimir o conteúdo de vários arquivos:
cat file1 file2Usando o operador de redirecionamento de saída >, você pode concatenar o conteúdo de vários arquivos em um novo arquivo:
cat file1 file2 > file3Usando >>, você pode anexar o conteúdo de vários arquivos em um novo arquivo, criando-o se ele não existir:
cat file1 file2 >> file3Ao visualizar arquivos de código-fonte, é útil ver os números das linhas. Você pode fazer com que o cat os imprima usando a opção -n :
cat -n file1Você só pode adicionar um número a linhas que não estejam em branco usando -b, ou também pode remover todas as múltiplas linhas vazias usando -s.
cat é frequentemente usado em combinação com o operador | para alimentar o conteúdo de um arquivo como entrada para outro comando: cat file1 | outro_comando.
O comando less no Linux
O comando less é um que eu uso muito. Ele mostra o conteúdo armazenado dentro de um arquivo, em uma interface de usuário agradável e interativa.
Use: less <nome_do_arquivo>.
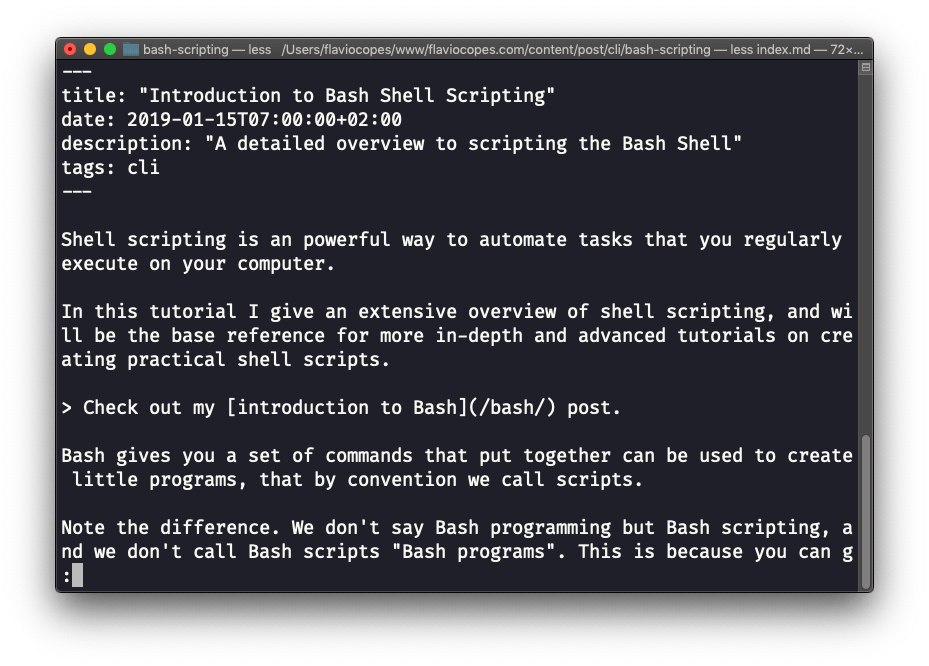
Quando estiver dentro de uma sessão less, você pode sair dela pressionando q.
Você pode navegar pelo conteúdo do arquivo usando as teclas das setas para cima e para baixo, ou usando a barra de espaço e b para navegar página por página. Você também pode pular para o final do arquivo pressionando G e voltar ao início pressionando g.
Você pode pesquisar o conteúdo do arquivo pressionando / digitando uma palavra para pesquisar. Isso busca adiante. Você pode pesquisar para trás usando o símbolo ? e digitando uma palavra.
Esse comando apenas visualiza o conteúdo do arquivo. Você pode abrir um editor diretamente pressionando v. Ele usará o editor do sistema, que, na maioria dos casos, é o vim.
Pressionar a tecla F entra no modo de acompanhamento ou modo de observação. Quando o arquivo é alterado por outra pessoa, como outro programa, você pode ver as alterações ao vivo.
Isso não acontece por padrão e você só vê a versão do arquivo no momento em que o abre. Você precisa pressionar ctrl-C para sair deste modo. Nesse caso, o comportamento é semelhante à execução do comando tail -f <nome_do_arquivo> .
Você pode abrir vários arquivos e navegar por eles usando :n (para ir para o próximo arquivo) e :p (para ir para o anterior).
O comando tail no Linux
O melhor caso de uso de tail, na minha opinião, é quando chamado com a opção -f. Ele abre o arquivo no final e observa as alterações no arquivo.
Sempre que houver novo conteúdo no arquivo, ele será impresso na janela. Isso é ótimo para observar arquivos de log, por exemplo:
tail -f /var/log/system.logPara sair, pressione a tecla ctrl-C.
Você pode imprimir as últimas 10 linhas de um arquivo:
tail -n 10 <nome_do_arquivo>Você pode imprimir todo o conteúdo do arquivo começando em uma linha específica usando + antes do número da linha:
tail -n +10 <nome_do_arquivo>tail pode fazer muito mais e, como sempre, meu conselho é verificar o man tail.
O comando wc no Linux
O comando wc nos fornece informações úteis sobre um arquivo ou entrada que ele recebe por meio de pipes.
echo test >> test.txt
wc test.txt
1 1 5 test.txtComo exemplo por meio de pipes, podemos contar a saída da execução do comando ls -al :
ls -al | wc
6 47 284A primeira coluna retornada é o número de linhas. O segundo é o número de palavras. O terceiro é o número de bytes.
Podemos dizer para apenas contar as linhas:
wc -l test.txtou apenas as palavras:
wc -w test.txtapenas os bytes:
wc -c test.txtBytes em conjuntos de caracteres ASCII equivalem a caracteres. Com conjuntos de caracteres que não sejam ASCII, o número de caracteres pode ser diferente porque alguns caracteres podem ocupar vários bytes (por exemplo, isso acontece em Unicode).
Nesse caso, o sinalizador -m ajudará você a obter o valor correto:
wc -m test.txtO comando grep no Linux
O comando grep é uma ferramenta muito útil. Quando você dominá-lo, ele o ajudará tremendamente na programação do dia a dia.
Se você está se perguntando, grep significa impressão de expressão regular global.Você pode usar grep para pesquisar arquivos ou combiná-lo com pipes para filtrar a saída de outro comando.
Por exemplo, aqui está como podemos encontrar as ocorrências da linha document.getElementById no arquivo index.md:
grep -n document.getElementById index.md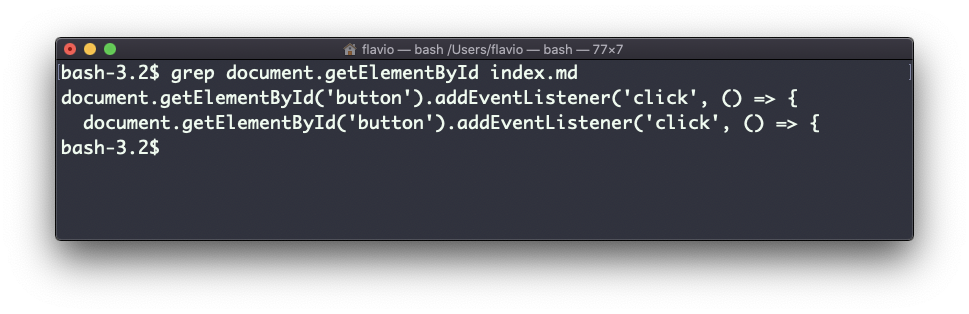
Usar a opção -n mostrará os números das linhas:
grep -n document.getElementById index.md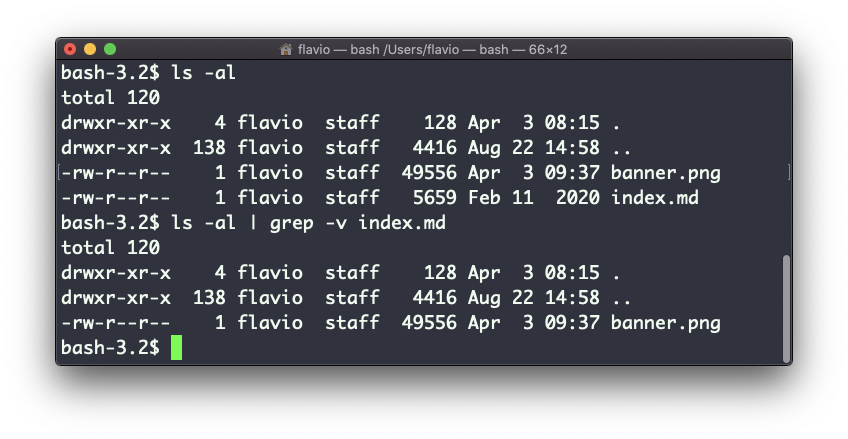
Uma coisa muito útil é dizer ao grep para imprimir 2 linhas antes e 2 linhas depois da linha correspondente para dar a ele mais contexto. Isso é feito usando a opção -C, que aceita várias linhas:
grep -nC 2 document.getElementById index.md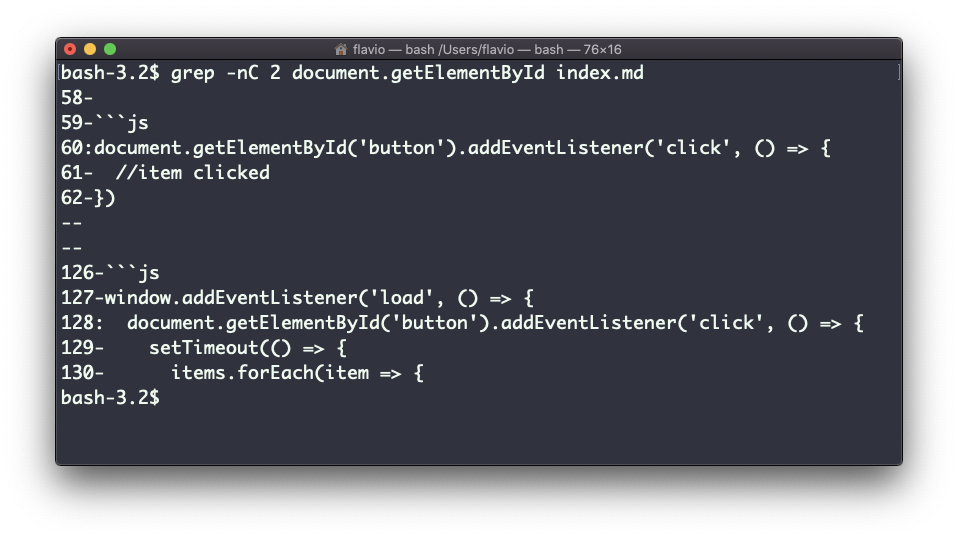
A pesquisa diferencia maiúsculas de minúsculas por padrão. Use o sinalizador -i para não diferenciar.
Conforme mencionado, você pode usar grep para filtrar a saída de outro comando. Podemos replicar a mesma funcionalidade acima usando:
less index.md | grep -n document.getElementByIdA string de pesquisa pode ser uma expressão regular e isso torna o grep muito poderoso.
Outra coisa que você pode achar muito útil é inverter o resultado, excluindo as linhas que correspondem a uma string específica, usando a opção -v :
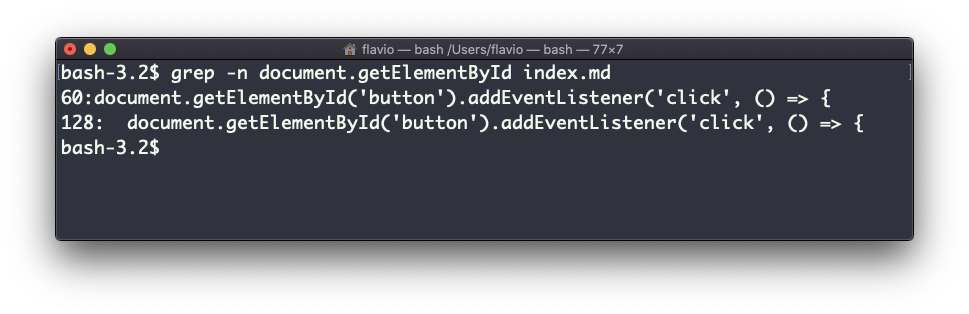
O comando sort no Linux
Suponha que você tenha um arquivo de texto que contém nomes de cachorros:
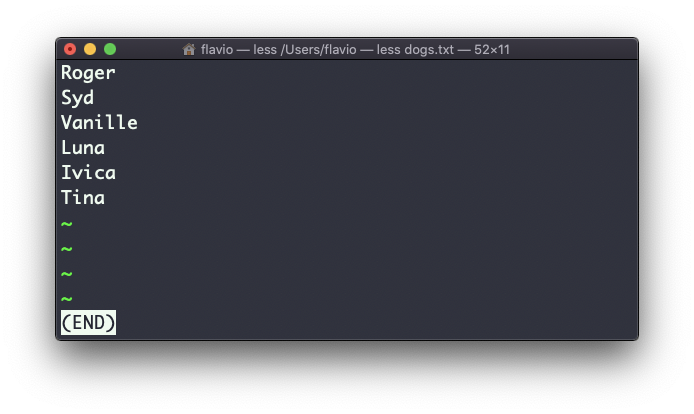
Essa lista não está ordenada.
O comando sort ajuda você a classificá-los por nome:
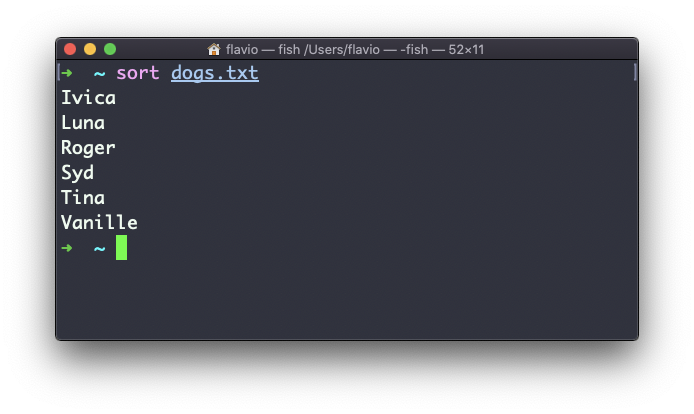
Use a opção r para reverter a ordem:
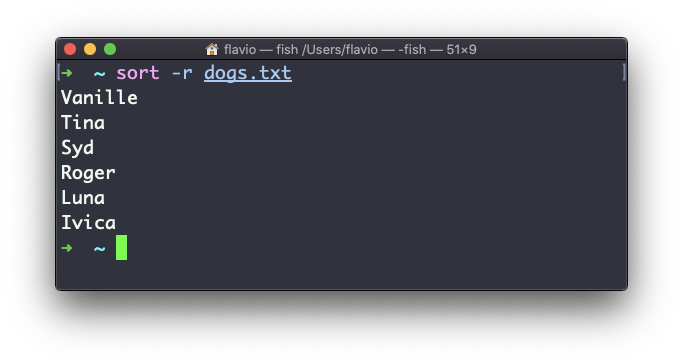
A classificação por padrão diferencia maiúsculas de minúsculas e é alfabética. Use a opção --ignore-case para classificar sem distinção entre maiúsculas e minúsculas e a opção -n para classificar usando uma ordem numérica.
Se o arquivo tiver linhas duplicadas:
Você pode usar a opção -u para removê-los:
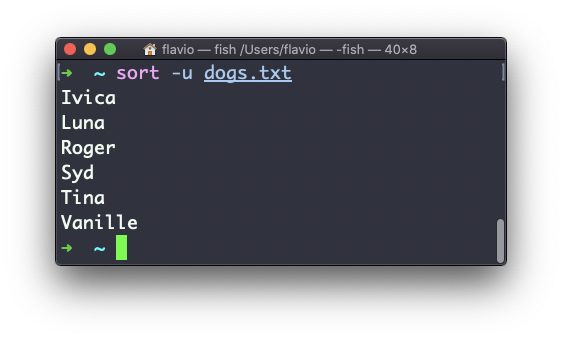
sort não funciona apenas em arquivos, como muitos comandos UNIX fazem – ele também funciona com pipes. Portanto, você pode usá-lo na saída de outro comando. Por exemplo, você pode ordenar os arquivos retornados por ls com:
ls | sortsort é muito poderoso e tem muito mais opções, que você pode explorar chamando man sort.
O comando uniq no Linux
uniq é um comando que ajuda a classificar linhas de texto.
Você pode obter essas linhas de um arquivo ou usar pipes da saída de outro comando:
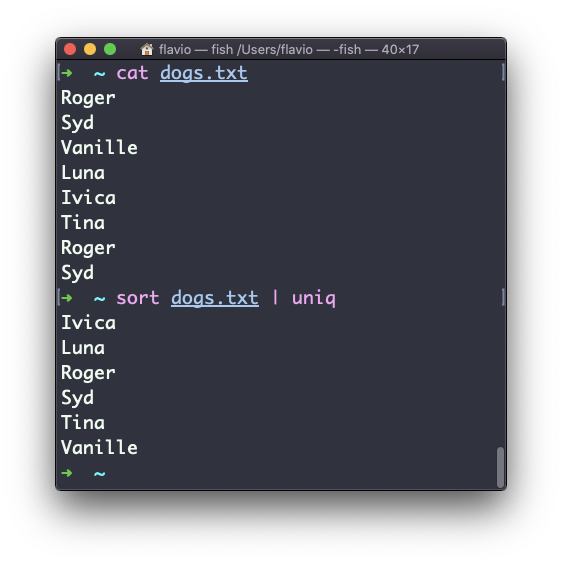
uniq dogs.txt
ls | uniqVocê precisa considerar este ponto importante: o uniq detectará apenas linhas duplicadas adjacentes.
Isso implica que você provavelmente o usará junto com sort:
sort dogs.txt | uniqO comando sort tem sua própria maneira de remover duplicatas com a opção -u (unique). Mas uniq tem mais poder.
Por padrão, ele remove linhas duplicadas:
Você pode instruí-lo para exibir apenas linhas duplicadas, por exemplo, com a opção -d :
sort dogs.txt | uniq -d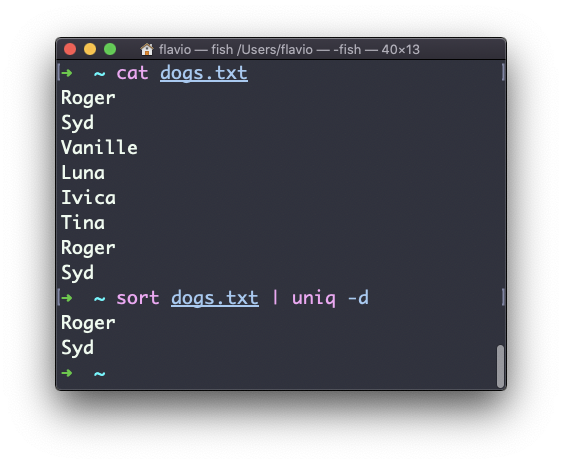
Você pode usar o comando -u para exibir apenas linhas não duplicadas:
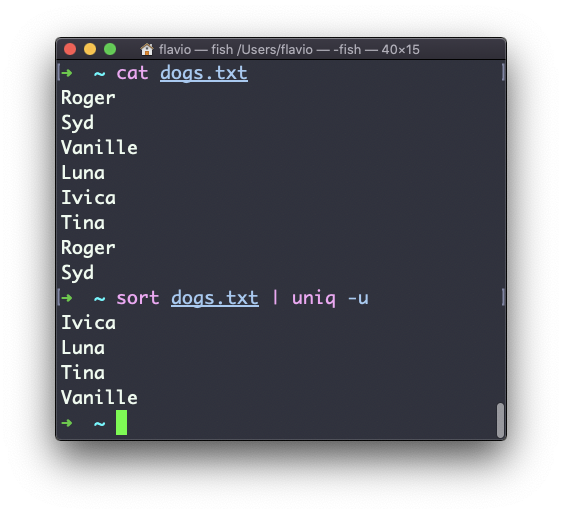
Você pode contar as ocorrências de cada linha com a opção -c :
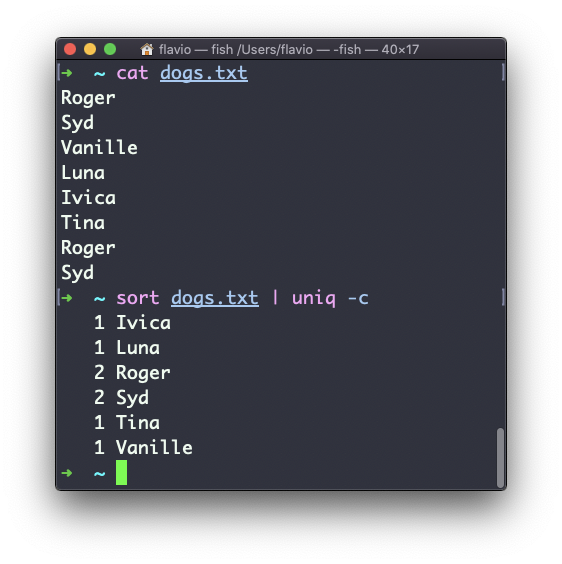
Use a combinação especial:
sort dogs.txt | uniq -c | sort -nrAssim, você classificará essas linhas pelas mais frequentes:
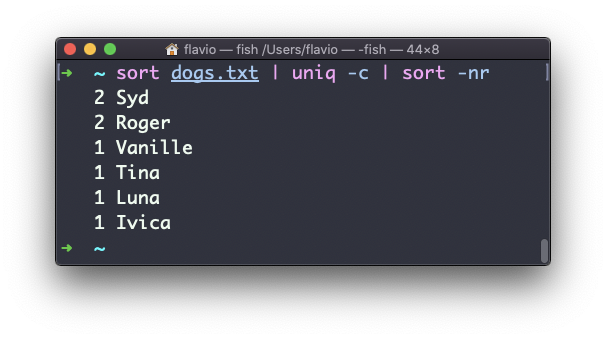
O comando diff no Linux
diff é um comando útil. Suponha que você tenha 2 arquivos que contêm quase as mesmas informações, mas não consegue encontrar a diferença entre os dois.
diff processará os arquivos e dirá qual é a diferença.
Suponha que você tem dois arquivos: dogs.txt e moredogs.txt. A diferença é que moredogs.txt contêm mais um nome de cachorro:
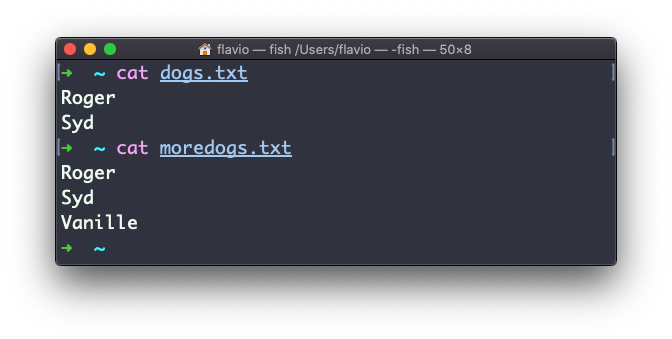
diff dogs.txt moredogs.txt dirá que o segundo arquivo tem mais uma linha, a linha 3 com o nome Vanille:
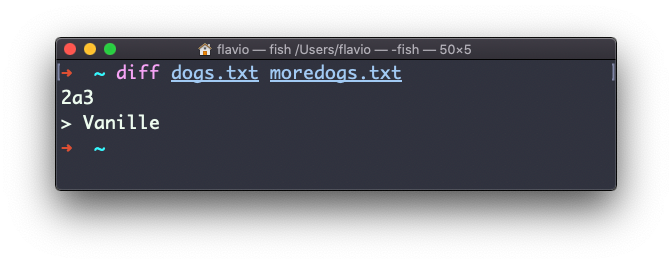
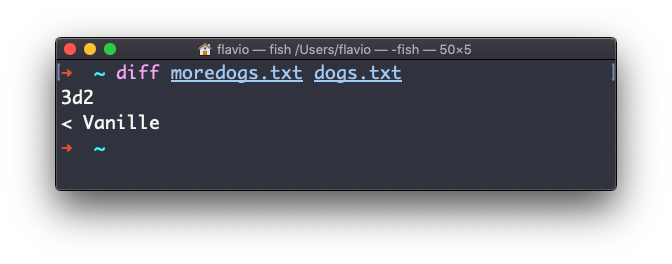
Se você inverter a ordem dos arquivos, será informado que falta a linha 3 no segundo arquivo, cujo conteúdo é Vanille:
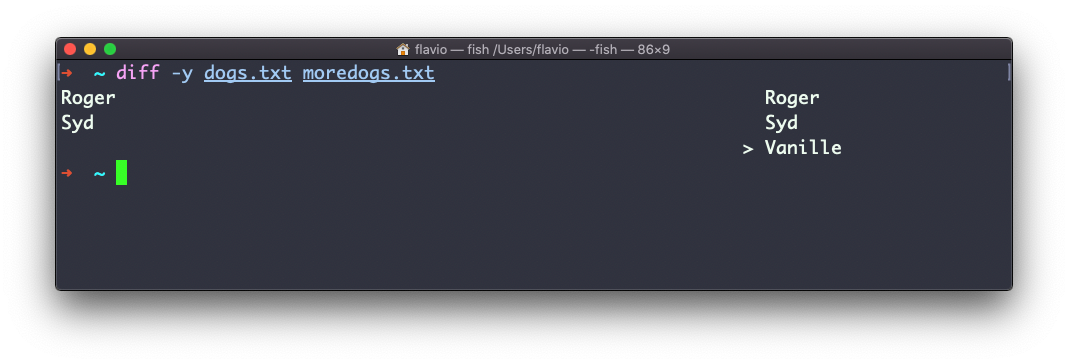
Usar a opção -y vai comparar os 2 arquivos linha por linha:
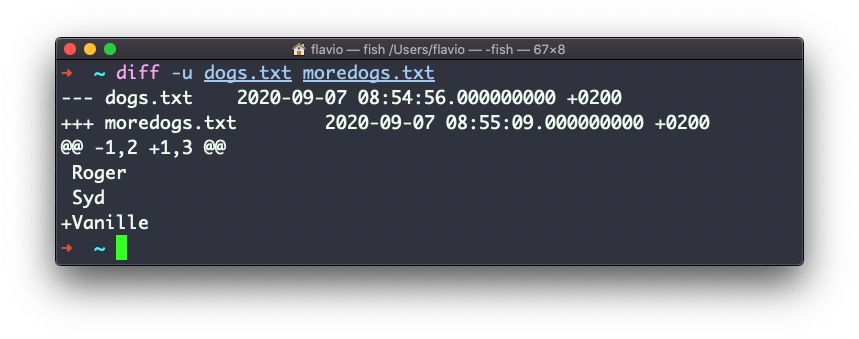
A opção -u entretanto, será mais familiar para você, porque é a mesma usada pelo sistema de controle de versão Git para exibir diferenças entre versões:
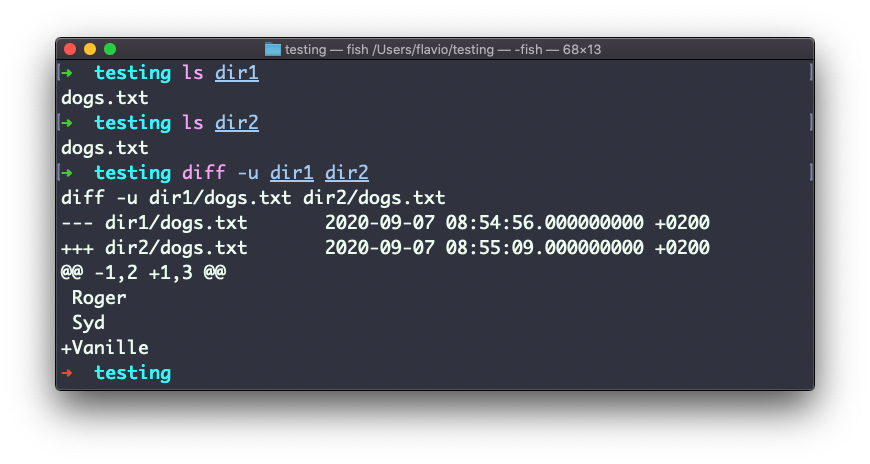
A comparação de diretórios funciona da mesma maneira. Você deve usar a opção -r para comparar recursivamente (entrando em subdiretórios):
Caso você esteja interessado em quais arquivos diferem, e não no conteúdo, use as opções r e q :
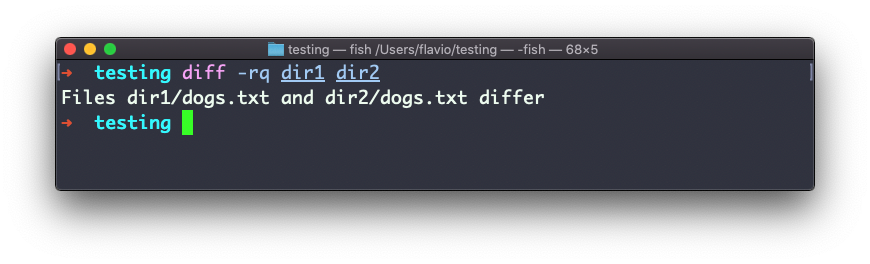
Existem muitas outras opções que você pode explorar na página de manual executando man diff:
O comando echo no Linux
O comando echo faz um trabalho simples: imprime na saída o argumento passado para ele.
Esse exemplo:
echo "hello"Isso imprimirá hello no terminal.
Podemos anexar a saída a um arquivo:
echo "hello" >> output.txtPodemos interpolar variáveis de ambiente:
echo "The path variable is $PATH"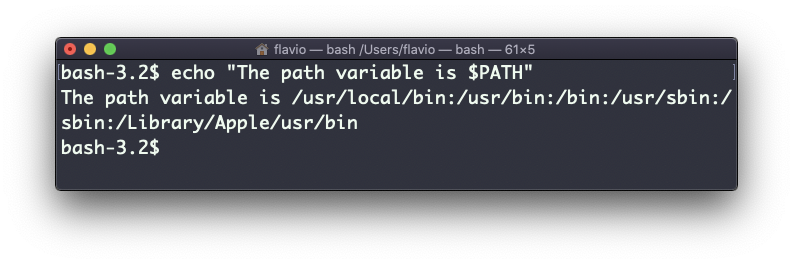
Cuidado, pois os caracteres especiais precisam ser escapados com uma barra invertida \. $ por exemplo:
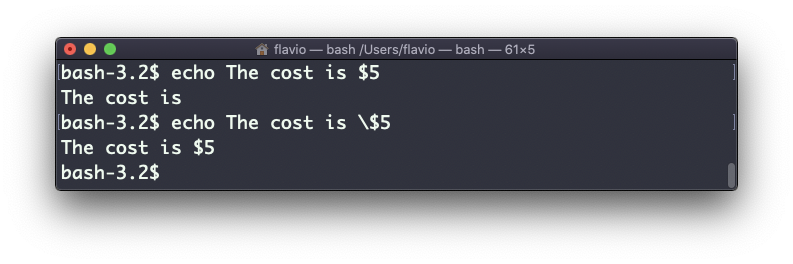
Este é apenas o começo. Podemos fazer algumas coisas legais quando se trata de interagir com os recursos do shell.
Podemos repetir os arquivos na pasta atual:
echo *Podemos repetir os arquivos da pasta atual que começam com a letra o:
echo o*Qualquer comando e recurso válido do Bash (ou qualquer shell que você esteja usando) pode ser usado aqui.
Você pode imprimir o caminho da sua pasta pessoal:
echo ~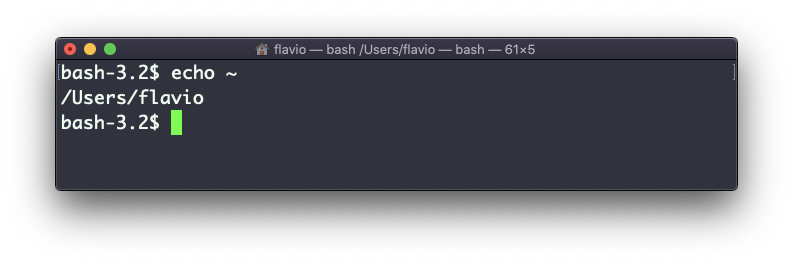
Você também pode executar comandos e imprimir o resultado na saída padrão (ou em arquivo, como você viu):
echo $(ls -al)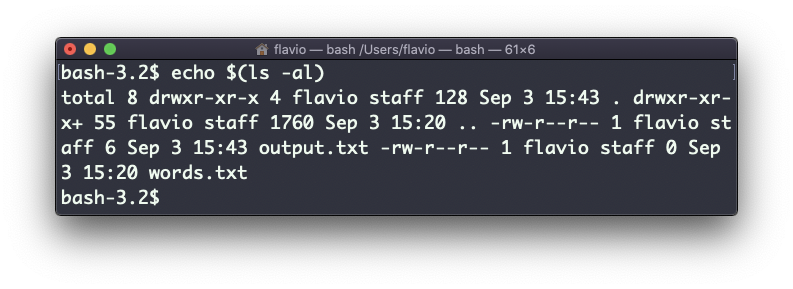
Observe que os espaços em branco não são preservados por padrão. Você precisa colocar o comando entre aspas duplas para fazer isso:
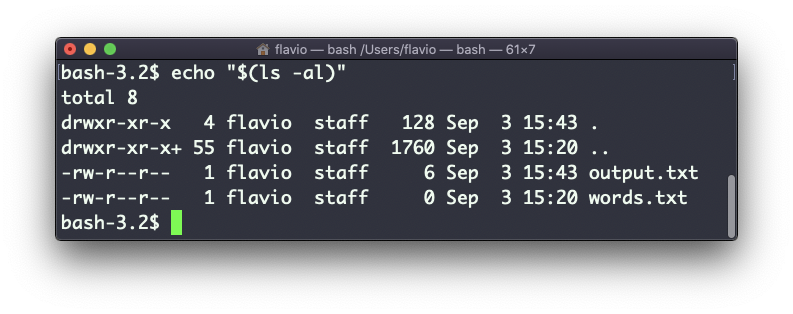
Você pode gerar uma lista de strings, por exemplo, intervalos:
echo {1..5}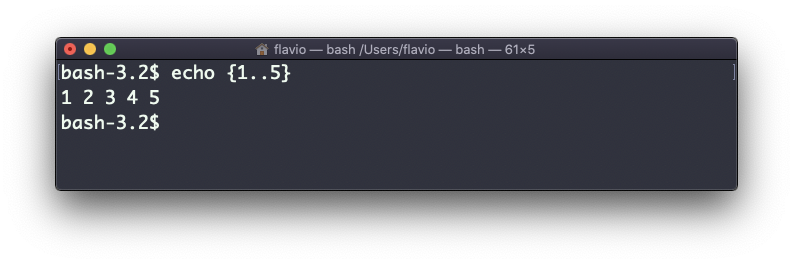
O comando chown no Linux
Cada arquivo/diretório em um sistema operacional como Linux ou macOS (e todo sistema UNIX em geral) tem um proprietário.
O proprietário de um arquivo pode fazer tudo com ele. Pode decidir o destino desse arquivo.
O proprietário (e o usuário root ) também pode alterar o proprietário para outro usuário, usando o comando chown:
chown <owner> <file>Assim:
chown flavio test.txtPor exemplo, se você tiver um arquivo que pertence ao root, você não poderá escrever nele como outro usuário:
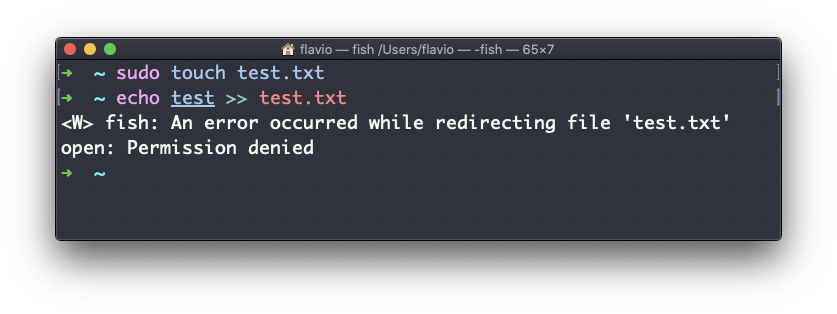
Você pode usar chown para transferir a propriedade para você:
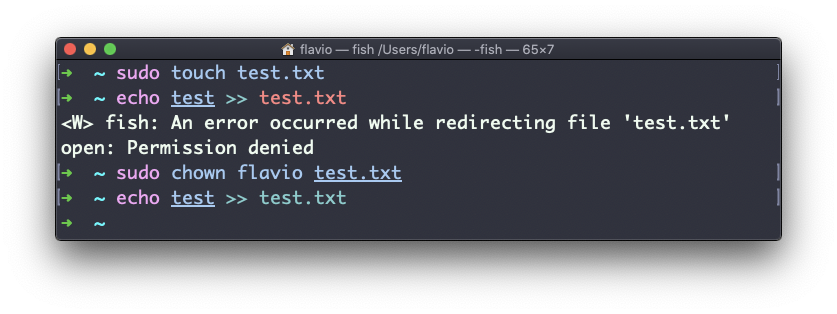
É bastante comum precisar alterar a propriedade de um diretório e recursivamente de todos os arquivos contidos, além de todos os subdiretórios e arquivos contidos neles também.
Você pode fazer isso usando o sinalizador -R :
chown -R <proprietário> <arquivo>Arquivos/diretórios não têm apenas um proprietário. Eles também têm um grupo. Através deste comando, você pode alterar isso simultaneamente enquanto altera o proprietário:
chown <proprietário>:<grupo> <nome_do_arquivo>Exemplo:
chown flavio:users test.txtVocê também pode alterar o grupo de um arquivo usando o comando chgrp:
chgrp <grupo> <nome_do_arquivo>O comando chmod no Linux
Cada arquivo nos sistemas operacionais Linux/macOS (e sistemas UNIX em geral) possui 3 permissões: leitura, gravação e execução.
Vá para uma pasta e execute o comando ls -al.
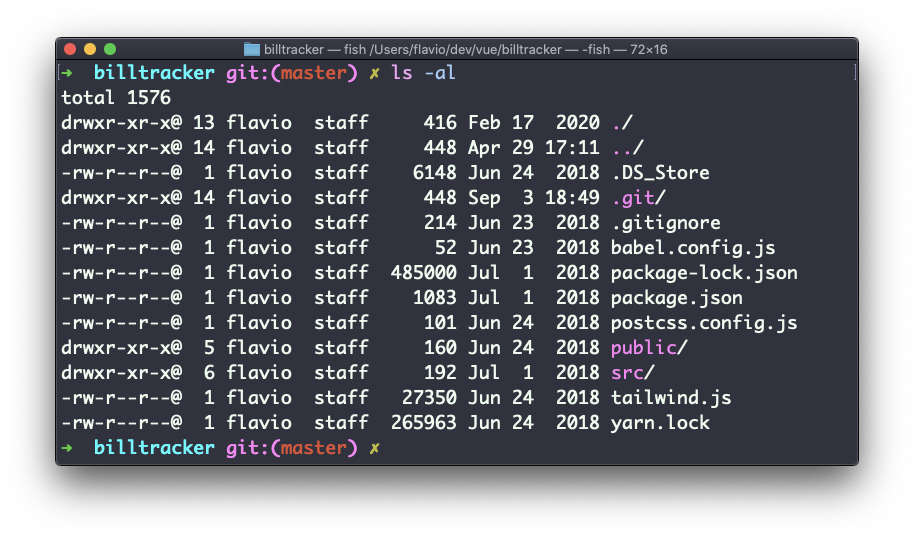
As strings estranhas que você vê em cada linha de arquivo, como drwxr-xr-x, definem as permissões do arquivo ou pasta.
Vamos dissecá-lo.
A primeira letra indica o tipo de arquivo:
-significa que é um arquivo normaldsignifica que é um diretóriolsignifica que é um link
Então você tem 3 conjuntos de valores:
- O primeiro conjunto representa as permissões do proprietário do arquivo
- O segundo conjunto representa as permissões dos membros do grupo ao qual o arquivo está associado
- O terceiro conjunto representa as permissões de todos os outros
Esses conjuntos são compostos por 3 valores. rwx significa que uma pessoa específica tem acesso de leitura (r, de read em inglês), gravação (w, de write em inglês) e execução (de eXecute em inglês). Qualquer coisa removida é trocada por -, que permite formar várias combinações de valores e permissões relativas: rw-, r--, r-x, e assim por diante.
Você pode alterar as permissões concedidas a um arquivo usando o comando chmod.
chmod pode ser usado de 2 maneiras. O primeiro usa argumentos simbólicos, o segundo usa argumentos numéricos. Vamos começar primeiro com os símbolos, o que é mais intuitivo.
Você digita chmod seguido por um espaço e uma letra:
asignifica tudousignifica usuáriogsignifica grupoosignifica outros
Em seguida, você digita + ou - para adicionar uma permissão ou removê-la. Em seguida, você insere um ou mais símbolos de permissão (r, w, x).
Tudo seguido do nome do arquivo ou pasta.
Aqui estão alguns exemplos:
chmod a+r nome_do_arquivo #todos podem ler
chmod a+rw nome_do_arquivo #todos podem ler e gravar
chmod o-rwx nome_do_arquivo #outros (que não sejam o proprietário, que não estejam no mesmo grupo do arquivo) não têm permissão de ler, gravar ou executar o arquivo Você pode aplicar as mesmas permissões a várias personas adicionando várias letras antes do +/-:
chmod og-r nome_do_arquivo #outros e grupo não podem mais lerCaso esteja editando uma pasta, você pode aplicar as permissões a todos os arquivos contidos nessa pasta usando o sinalizador -r (recursivo).
Argumentos numéricos são mais rápidos, mas acho difícil lembrá-los quando você não os usa no dia a dia. Você usa um algarismo que representa as permissões da persona. Este valor numérico pode ser no máximo 7 e é calculado da seguinte forma:
1se tiver permissão de execução2se tiver permissão de gravação4se tiver permissão de leitura
Isso nos dá 4 combinações:
0Nenhuma permissão1pode executar2pode escrever3pode escrever, executar4pode ler5pode ler, executar6pode ler e escrever7pode ler, escrever e executar
Nós os usamos em grupos de 3, para definir as permissões de todos os 3 grupos ao todo:
chmod 777 nome_do_arquivo
chmod 755 nome_do_arquivo
chmod 644 nome_do_arquivoO comando umask no Linux
Ao criar um arquivo, você não precisa decidir as permissões antecipadamente. As permissões têm padrões.
Esses padrões podem ser controlados e modificados usando o comando umask .
Digitar umask sem argumentos mostrará o umask, atual, neste caso 0022:
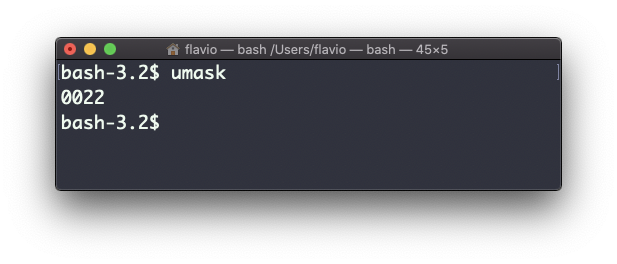
O que 0022 significa? Esse é um valor octal que representa as permissões.
Outro valor comum é 0002.
Use umask -S para ver uma notação legível por humanos:
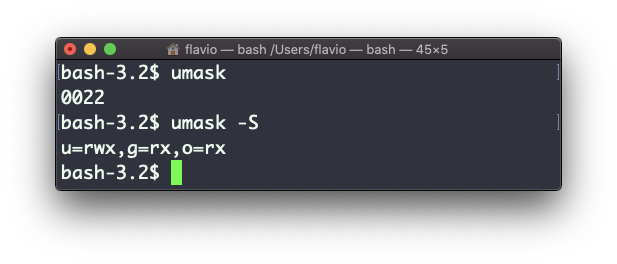
Neste caso, o usuário (u), proprietário do arquivo, possui permissões de leitura, escrita e execução nos arquivos.
Os demais usuários pertencentes ao mesmo grupo (g) possuem permissão de leitura e execução, igual a todos os demais usuários (o).
Na notação numérica, normalmente alteramos os últimos 3 dígitos.
Aqui está uma lista que dá um significado ao número:
0ler, escrever, executar1ler e escrever2ler e executar3somente leitura4escrever e executar5escrever apenas6executar apenas7nenhuma permissão
Observe que esta notação numérica difere daquela que usamos em chmod.
Podemos definir um novo valor para a máscara definindo o valor em formato numérico:
umask 002ou você pode alterar a permissão de uma função específica:
umask g+rO comando du no Linux
O comando du calculará o tamanho de um diretório como um todo:
du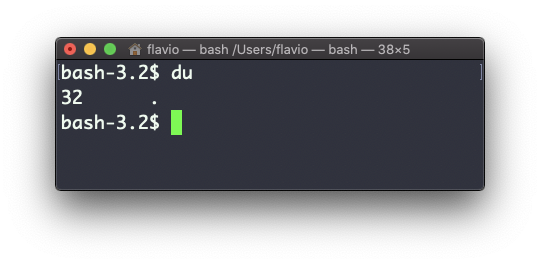
O número 32 aqui é um valor expresso em bytes.
Rodar du * calculará o tamanho de cada arquivo individualmente:
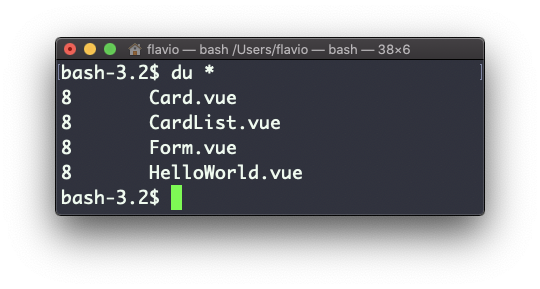
Você pode definir du para exibir valores em MegaBytes, usando du -m, e GigaBytes, usando du -g.
A opção -h mostrará uma notação legível para tamanhos, adaptando-se ao tamanho:
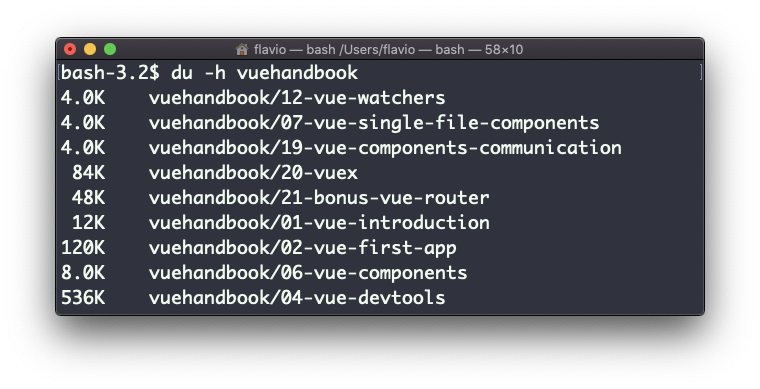
Adicionar a opção -a também imprimirá o tamanho de cada arquivo nos diretórios:
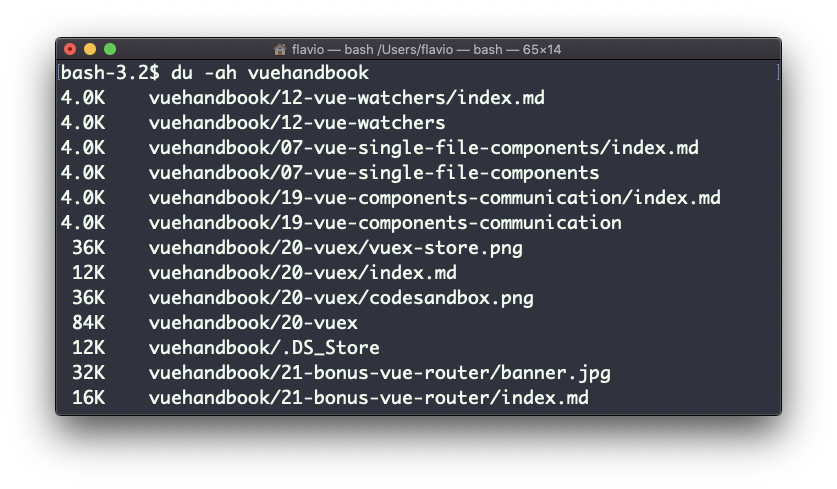
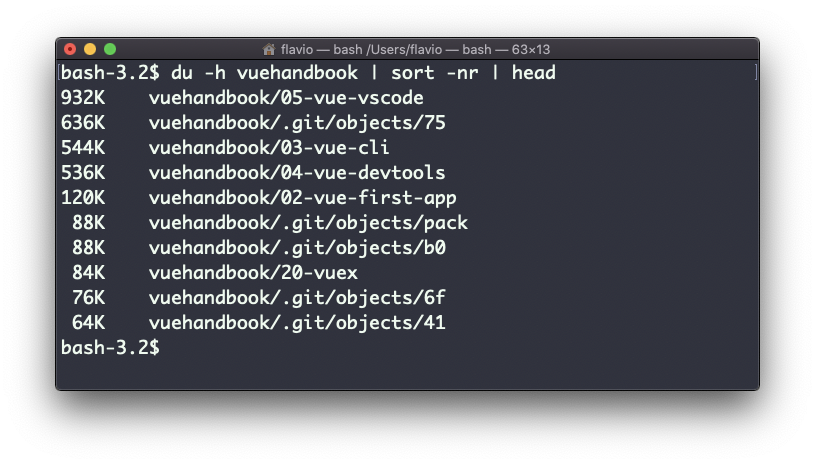
Uma coisa útil é classificar os diretórios por tamanho:
du -h <diretório> | sort -nrEm seguida, use head para obter apenas os 10 primeiros resultados:
O comando df no Linux
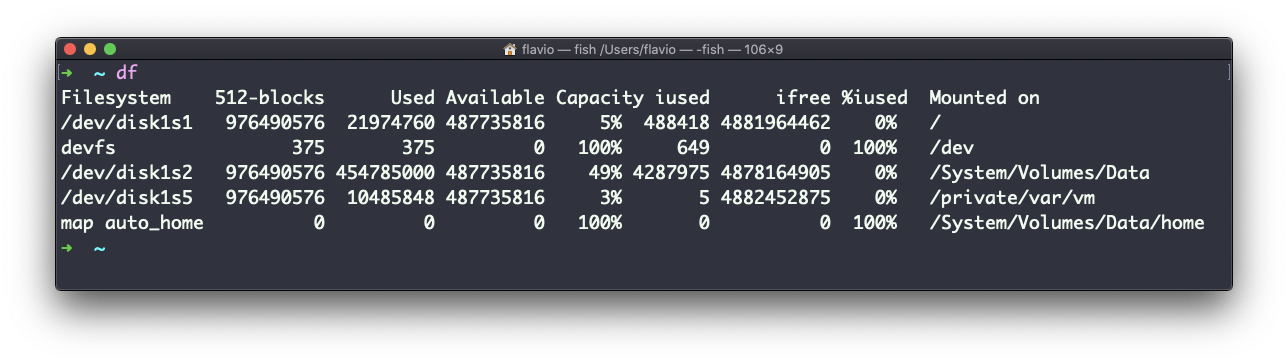
O comando df é usado para obter informações de uso do disco.
Em sua forma básica, ele imprimirá informações sobre os volumes montados:
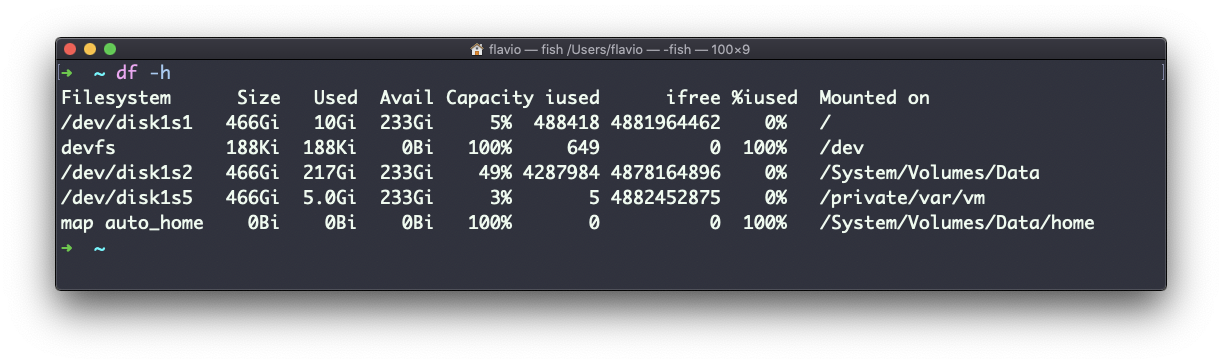
Usar a opção -h (df -h) mostrará esses valores em um formato legível:
Você também pode especificar um nome de arquivo ou diretório para obter informações sobre o volume específico em que ele reside:
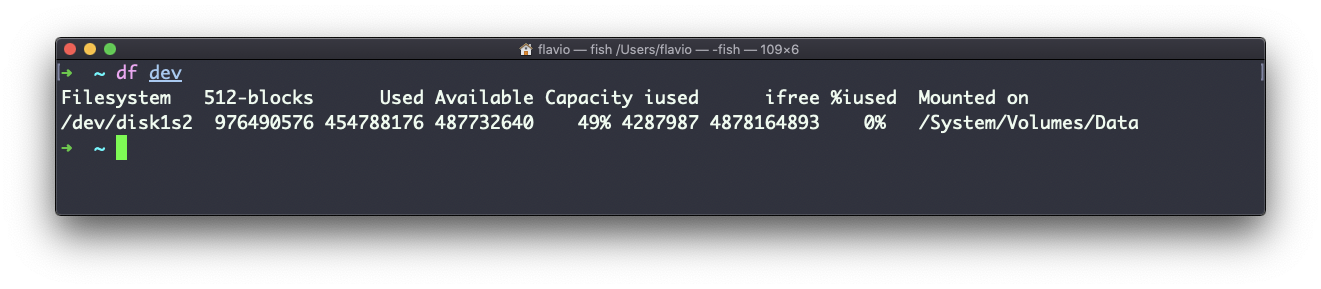
O comando basename no Linux
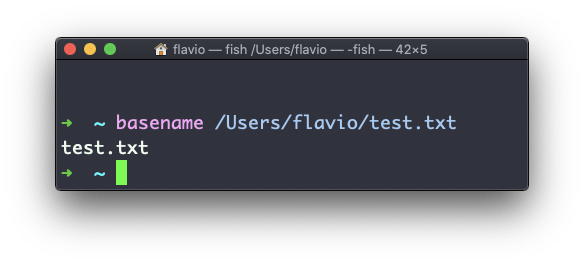
Suponha que você tenha um caminho para um arquivo, por exemplo /Users/flavio/test.txt.
Rodar
basename /Users/flavio/test.txtretornará a string test.txt:
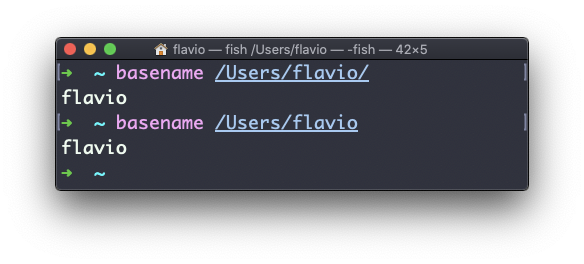
Se você executar basename em uma string de caminho que aponta para um diretório, obterá o último segmento do caminho. Neste exemplo, /Users/flavio é um diretório:
O comando dirname no Linux
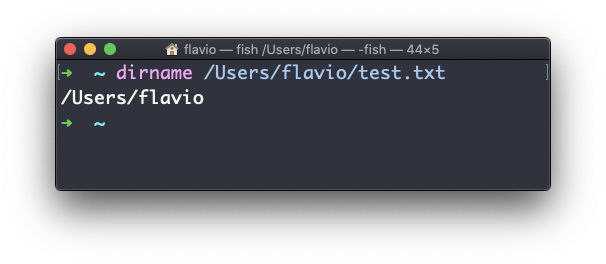
Suponha que você tenha um caminho para um arquivo, por exemplo /Users/flavio/test.txt.
Rodar
dirname /Users/flavio/test.txtretornará a string /Users/flavio:
O comando ps no Linux
Seu computador está executando vários processos diferentes o tempo todo.
Você pode inspecionar todos eles usando o comando ps:
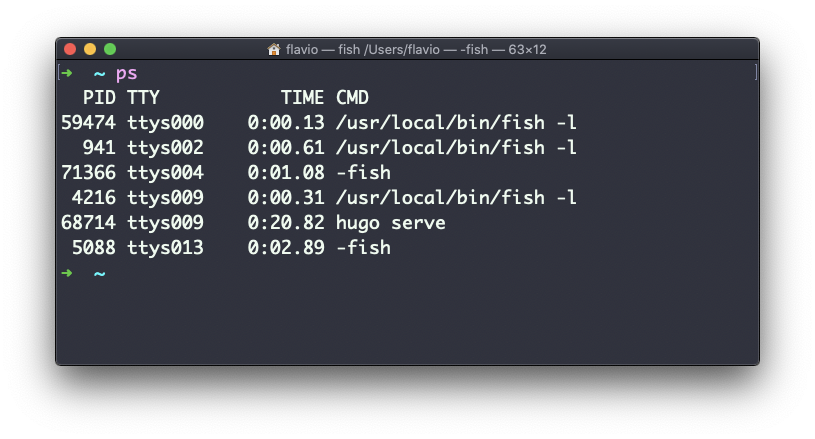
Essa é a lista de processos iniciados pelo usuário em execução na sessão atual.
Aqui eu tenho algumas instâncias de fish shell, a maioria abertas pelo VS Code dentro do editor, e uma instância de Hugo executando a visualização de desenvolvimento de um site.
Esses são apenas os comandos atribuídos ao usuário atual. Para listar todos os processos precisamos passar algumas opções para os ps.
O mais comum que eu uso é o ps ax:
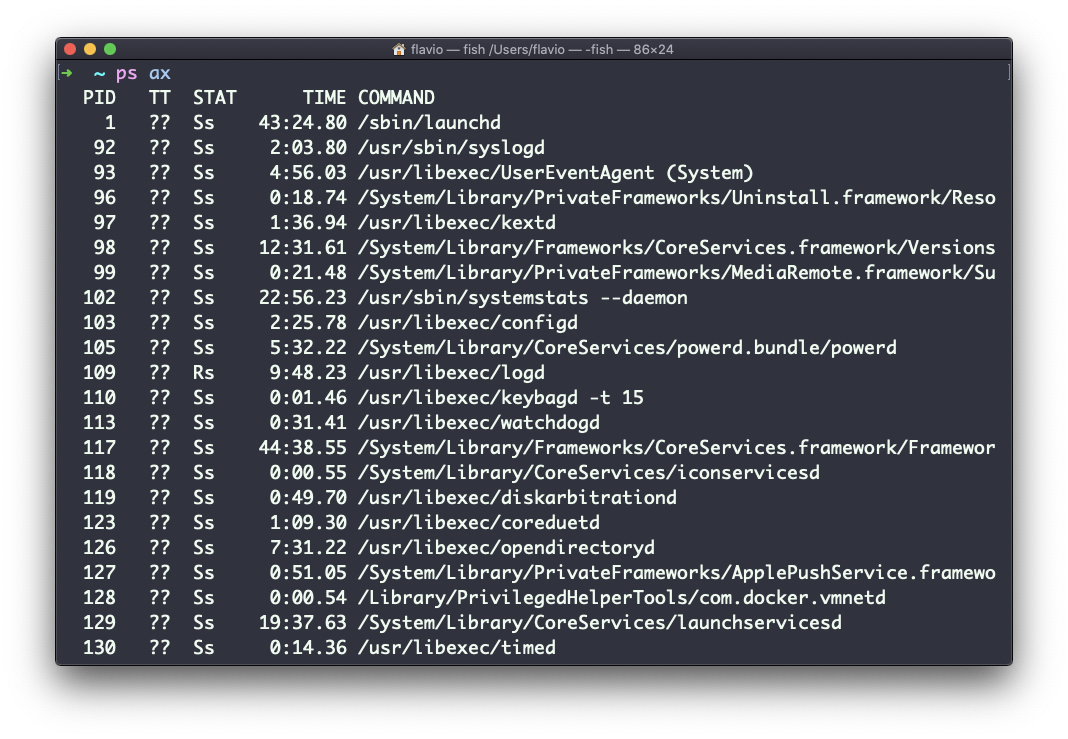
O opçãoatambém é usada para listar os processos de outros usuários, não apenas os seus.xmostra processos não vinculados a nenhum terminal (não iniciados pelos usuários através de um terminal).
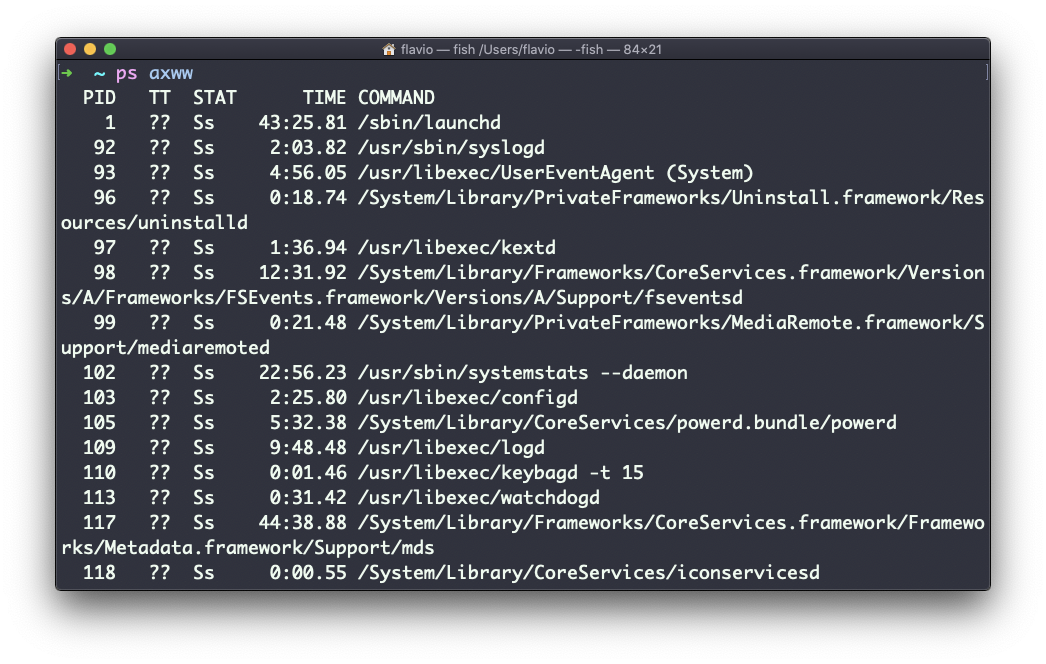
Como você pode ver, os comandos mais longos são cortados. Use o comando ps axww para continuar a listagem de comandos em uma nova linha em vez de cortá-la:
Precisamos especificar w 2 vezes para aplicar esta configuração (não é um erro de digitação).Você pode procurar um processo específico combinando grep com um pipe, assim:
ps axww | grep "Visual Studio Code"
As colunas retornadas por ps representam algumas informações importantes.
A primeira informação é o PID, o ID do processo. Isso é fundamental quando você deseja fazer referência a esse processo em outro comando, por exemplo, para eliminá-lo.
Então temos TT que nos informa o ID do terminal usado.
Então STAT nos informa o estado do processo:
I um processo que está ocioso (suspenso por mais de 20 segundos)R um processo executávelS um processo que está dormindo por menos de 20 segundosT um processo paradoU um processo em espera ininterruptoZ um processo morto (um zumbi)
Se você tiver mais de uma carta, a segunda representa mais informações, que podem ser muito técnicas.
É comum ter + que indica que o processo está em primeiro plano no seu terminal. s significa que o processo é um líder de sessão.
TIME nos diz há quanto tempo o processo está em execução.
O comando top no Linux
O comando top é usado para exibir informações dinâmicas em tempo real sobre os processos em execução no sistema.
É muito útil entender o que está acontecendo.
Seu uso é simples – basta digitar top e o terminal ficará totalmente imerso nesta nova visualização:
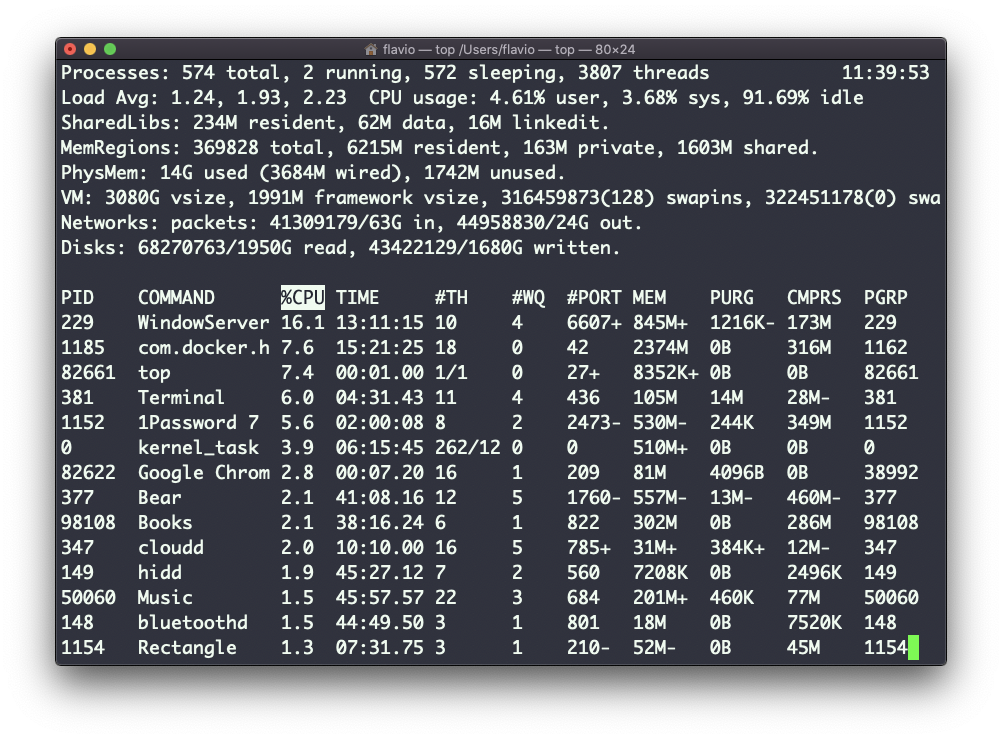
O processo é demorado. Para sair, você pode digitar a letra q ou ctrl-C.
Muitas informações nos são fornecidas: o número de processos, quantos estão em execução ou em suspensão, a carga do sistema, o uso da CPU e muito mais.
Abaixo, a lista de processos que ocupam mais memória e CPU é constantemente atualizada.
Por padrão, como você pode ver na coluna %CPU destacada, eles são classificados pela CPU usada
Você pode adicionar um sinalizador para classificar os processos pela memória utilizada:
top -o memO comando kill no Linux
Os processos do Linux podem receber sinais e reagir a eles.
Essa é uma maneira de interagirmos com programas em execução.
O programa kill pode enviar uma variedade de sinais para um programa.
Não é usado apenas para encerrar um programa, como o nome sugere, mas essa é sua função principal.
Nós o usamos desta maneira:
kill <PID>Por padrão, isso envia o sinal TERM para o ID do processo especificado.
Podemos usar sinalizadores para enviar outros sinais, incluindo:
kill -HUP <PID>
kill -INT <PID>
kill -KILL <PID>
kill -TERM <PID>
kill -CONT <PID>
kill -STOP <PID>HUP significa desligar. É enviado automaticamente quando uma janela de terminal que iniciou um processo é fechada antes de encerrar o processo.
INT significa interrupção e envia o mesmo sinal usado quando pressionamos ctrl-C no terminal, o que geralmente encerra o processo.
KILL não é enviado para o processo, mas para o kernel do sistema operacional, que imediatamente interrompe e finaliza o processo.
TERM significa terminar. O processo vai receber esse sinal e terminar sozinho. É o sinal padrão enviado por kill.
CONT significa continuar. Pode ser usado para retomar um processo interrompido.
STOP não é enviado para o processo, mas para o kernel do sistema operacional, que interrompe imediatamente (mas não encerra) o processo.
Você pode ver números usados, como kill -1 <PID>. Nesse caso,
1 corresponde ao HUP.2 corresponde ao INT.9 corresponde ao KILL.15 corresponde ao TERM.18 corresponde ao CONT.15 corresponde ao STOP.
O comando killall no Linux
Semelhante ao comando kill, killall enviará o sinal para vários processos ao mesmo tempo, em vez de enviar um sinal para um ID de processo específico.
Essa é a sintaxe:
killall <nome>Aqui, nome é o nome de um programa. Por exemplo, você pode ter várias instâncias do programa top em execução. killall top encerrará todas elas.
Você pode especificar o sinal, como acontece com kill (e verifique o tutorial kill para ler mais sobre os tipos específicos de sinais que podemos enviar), por exemplo:
killall -HUP topO comando jobs no Linux
Quando executamos um comando no Linux/macOS, podemos configurá-lo para execução em segundo plano usando o símbolo & após o comando.
Por exemplo, podemos executar top em segundo plano:
top &Isso é muito útil para programas de longa duração.
Podemos voltar a esse programa usando o comando fg. Isso funciona bem se tivermos apenas um trabalho em segundo plano, caso contrário, precisaremos usar o número do trabalho: fg 1, fg 2 e assim por diante.
Para obter o número do trabalho, usamos o comando jobs.
Digamos que executemos top & e então top -o mem &. Temos 2 instâncias principais em execução. jobs nos mostrará isso:
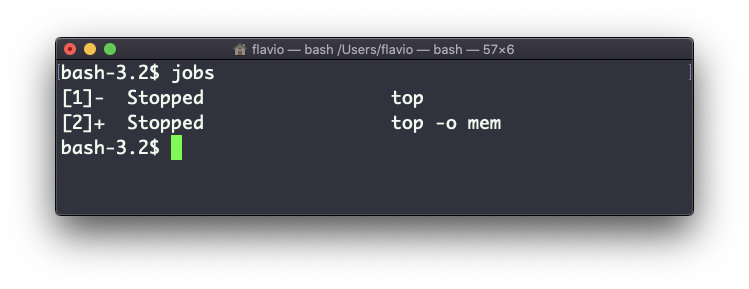
Agora, podemos voltar para um daqueles que usam fg <jobid>. Para parar o programa novamente podemos clicar em cmd-Z.
Executar jobs -l também imprimirá o ID do processo de cada trabalho.
O comando bg no Linux
Quando um comando está em execução, você pode suspendê-lo usando ctrl-Z.
O comando interromperá imediatamente e você retornará ao terminal shell.
Você pode retomar a execução do comando em segundo plano, para que ele continue em execução, mas não o impeça de realizar outros trabalhos no terminal.
Neste exemplo, tenho 2 comandos parados:
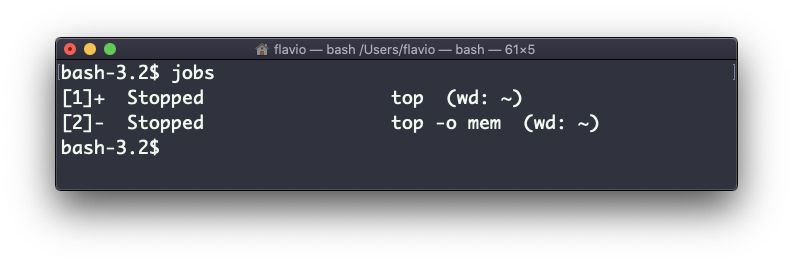
Posso executar o bg 1 para retomar em segundo plano a execução do job nº 1.
Eu também poderia ter dito bg sem nenhuma opção, pois o padrão é escolher job nº 1 da lista.
O comando fg no Linux
Quando um comando está sendo executado em segundo plano, porque você o iniciou com & no final (exemplo: top &) ou porque você o colocou em segundo plano (com o comando bg), você pode colocá-lo em primeiro plano usando fg.
Executar
fgretomará em primeiro plano o último trabalho que foi suspenso.
Você também pode especificar qual trabalho deseja retomar para primeiro plano passando o número do trabalho, que pode ser obtido usando o comando jobs.
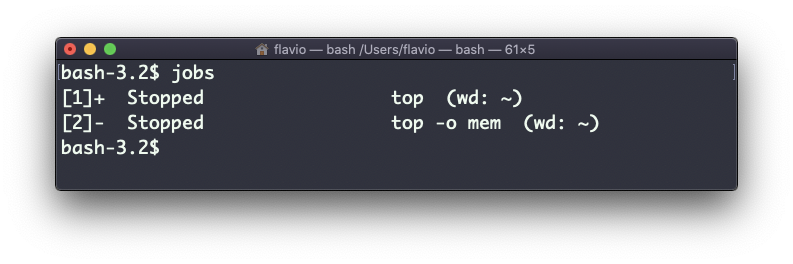
Executar fg 2 retomará o job nº 2:
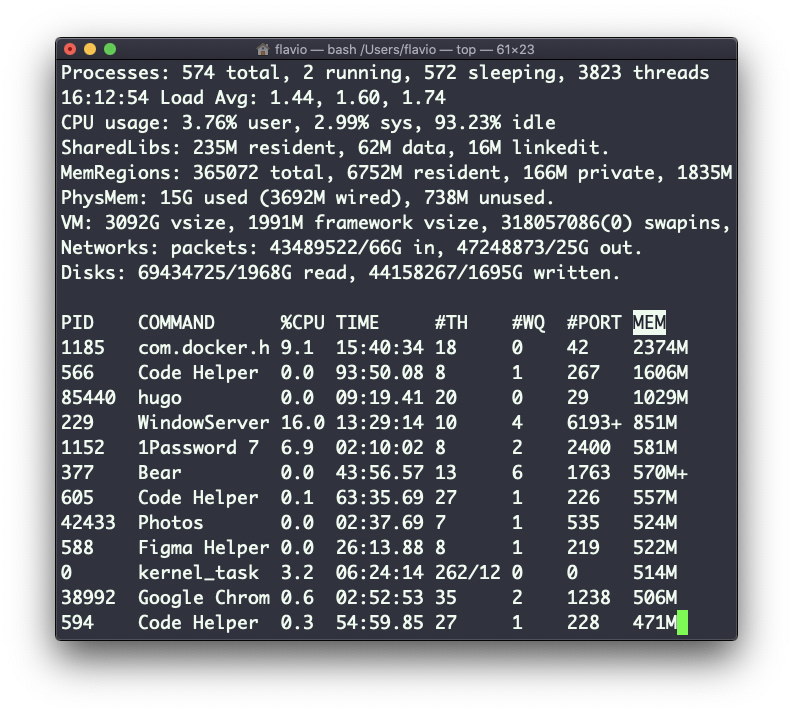
O comando type no Linux
Um comando pode ser um destes 4 tipos:
- um executável
- um programa embutido no shell
- uma função shell
- um apelido
O comando type pode ajudar a descobrir isso, caso queiramos saber ou estejamos apenas curiosos. Ele dirá como o comando será interpretado.
A saída dependerá do shell usado. Este é o Bash:
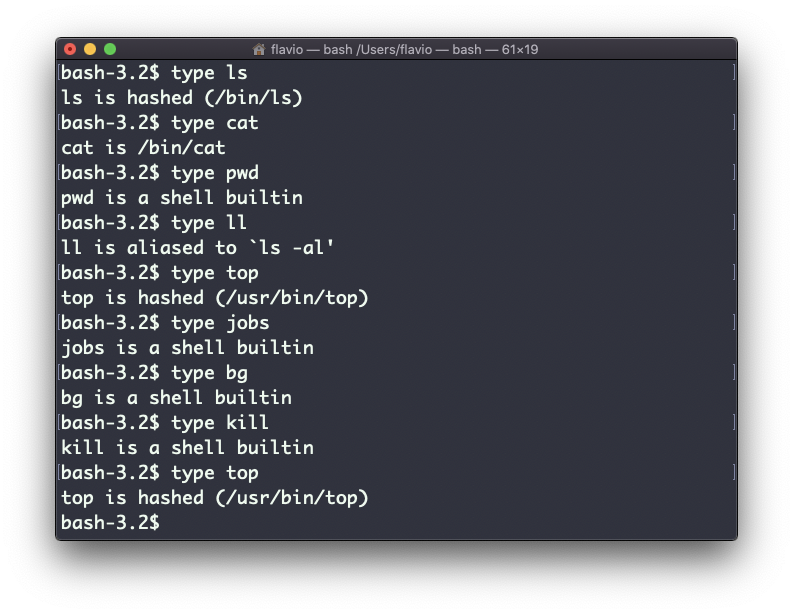
Este é o Zsh:
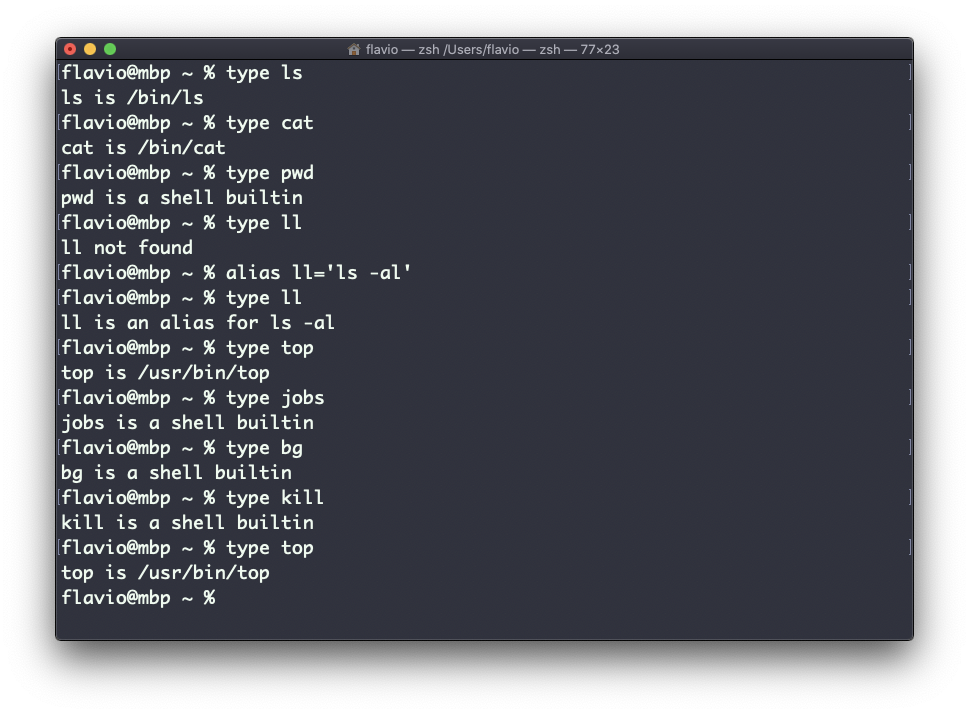
Este é o Fish:
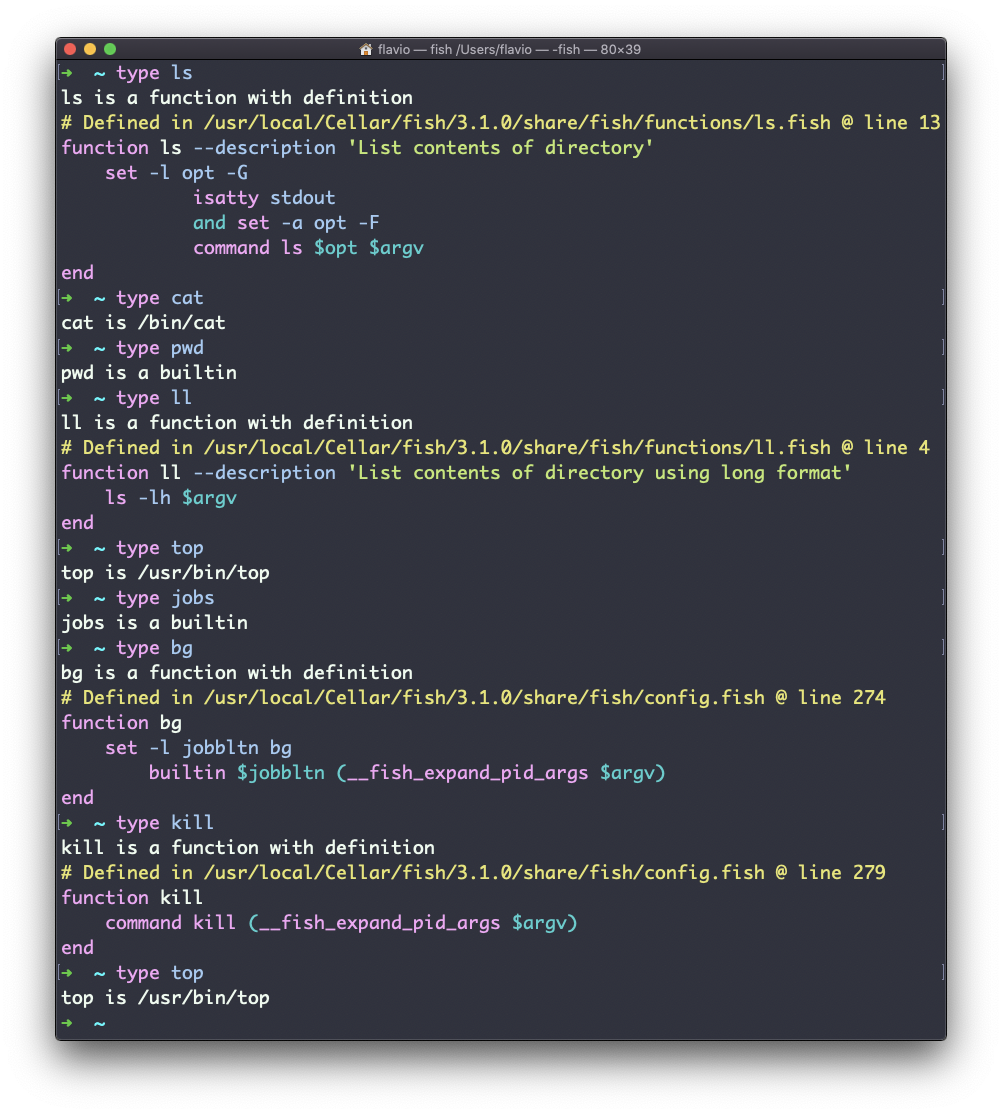
Uma das coisas mais interessantes aqui é que, para aliases, ele dirá para que serve o alias. Você pode ver o ll alias, no caso de Bash e Zsh, mas o Fish o fornece por padrão, então ele dirá que é uma função interna do shell.
O comando which no Linux
Suponha que você tenha um comando que pode executar porque está no caminho do shell, mas deseja saber onde ele está localizado.
Você pode fazer isso usando which. O comando retornará o caminho para o comando especificado:
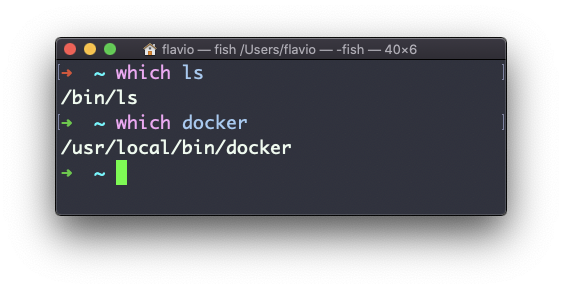
which funcionará apenas para executáveis armazenados em disco, não para aliases ou funções de shell integradas.
O comando nohup no Linux
Às vezes, você precisa executar um processo de longa duração em uma máquina remota e depois desconectar.
Ou você, simplesmente, deseja evitar que o comando seja interrompido se houver algum problema de rede entre você e o servidor.
A maneira de executar um comando mesmo depois de efetuar logout ou fechar a sessão em um servidor é usar o comando nohup.
Use nohup <comando> para permitir que o processo continue funcionando mesmo depois de você sair.
O comando xargs no Linux
O comando xargs é usado em um shell UNIX para converter a entrada padrão em argumentos para um comando.
Em outras palavras, através do uso de xargs, a saída de um comando é usada como entrada de outro comando.
Aqui está a sintaxe que você usará:
comando1 | xargs comando2Usamos um pipe (|) para passar a saída para xargs. Isso cuidará da execução do comando comando2, usando a saída de comando1 como seu(s) argumento(s).
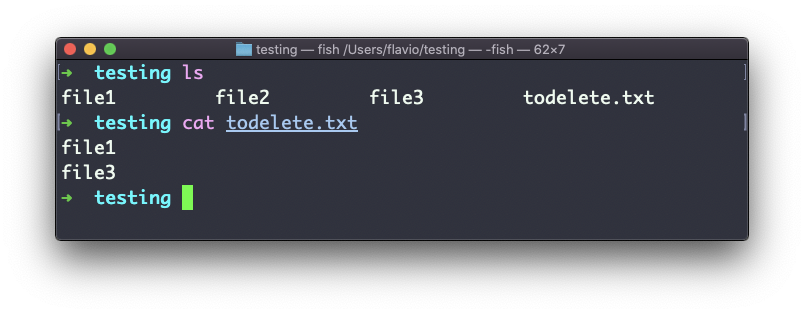
Vamos fazer um exemplo simples. Você deseja remover alguns arquivos específicos de um diretório. Esses arquivos estão listados dentro de um arquivo de texto.
Temos 3 arquivos: file1, file2, file3.
No todelete.txt temos uma lista de arquivos que queremos excluir, neste exemplo file1 e file3:
Vamos canalizar a saída de cat todelete.txt para o comando rm, através de xargs, assim:
cat todelete.txt | xargs rmEsse é o resultado, os arquivos que listamos agora foram excluídos:
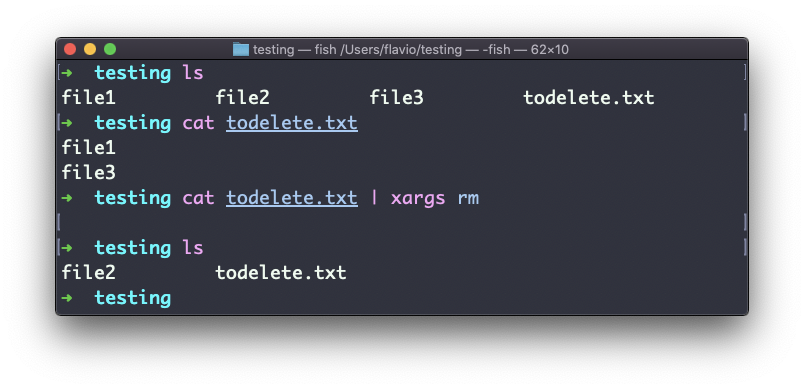
A forma como funciona é que xargs executará rm 2 vezes, uma para cada linha retornada por cat.
Este é o uso mais simples de xargs. Existem várias opções que podemos usar.
Um dos mais úteis, na minha opinião (especialmente quando se começa a aprender xargs), é -p. Usar esta opção fará com que o xargs imprima um prompt de confirmação com a ação que será executada:
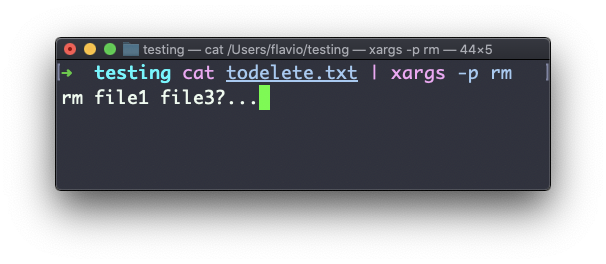
A opção -n permite que você diga ao xargs para realizar uma iteração por vez, para que você possa confirmá-las individualmente com -p. Aqui dizemos ao xargs para realizar uma iteração por vez com -n1:
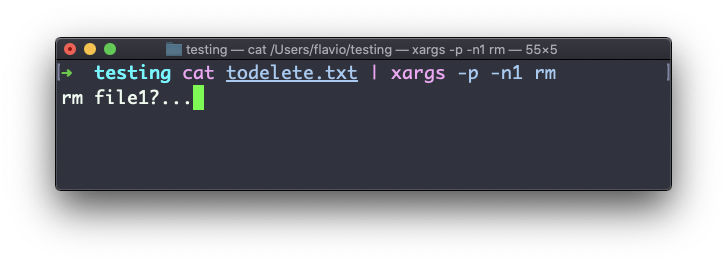
A opção -I é outra amplamente utilizada. Ela permite que você coloque a saída em um espaço reservado e, então, você pode fazer várias coisas.
Uma delas é executar vários comandos:
comando1 | xargs -I % /bin/bash -c 'comando2 %; comando3 %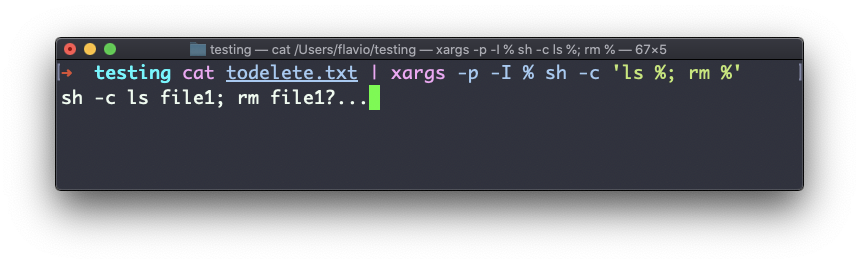
Você pode trocar o símbolo % que usei acima por qualquer outra coisa – é uma variável.O comando do editor vim no Linux
vim é um editor de arquivos muito popular, especialmente entre programadores. Ele é desenvolvido ativamente e atualizado com frequência, e há uma grande comunidade em torno dele. Há até uma conferência sobre o Vim!
vi em sistemas modernos é apenas um apelido para vim, que significa que vim melhorou.
Você inicia executando o vi na linha de comando.
Você pode especificar um nome de arquivo no momento da chamada para editar esse arquivo específico:
vi test.txt
Você deve saber que o Vim possui 2 modos principais:
- modo de comando (ou normal)
- modo de inserção
Ao iniciar o editor, você está no modo de comando. Você não pode inserir texto como espera de um editor baseado em GUI. Você tem que entrar no modo de inserção.
Você pode fazer isso pressionando a tecla i. Depois de fazer isso, a palavra -- INSERT -- aparece na parte inferior do editor:
Agora, você pode começar a digitar e preencher a tela com o conteúdo do arquivo:
Você pode mover-se pelo arquivo com as teclas de seta ou usando as teclas h - j - k - l. h-l para esquerda e direita, j-k para baixo e para cima.
Quando terminar de editar, você pode pressionar a tecla esc para sair do modo de inserção e voltar ao modo de comando.
Neste ponto, você pode navegar no arquivo, mas não pode adicionar conteúdo a ele (e tome cuidado com as teclas que você pressiona, pois podem ser comandos).
Uma coisa que você pode querer fazer agora é salvar o arquivo. Você pode fazer isso pressionando: (dois pontos) e w.
Você pode salvar e sair pressionando :, w e q: :wq
Você pode sair sem salvar pressionando :, q e !: :q!
Você pode desfazer e editar acessando o modo de comando e pressionando u. Você pode refazer (cancelar um desfazer) pressionando ctrl-r.
Esses são os princípios básicos para trabalhar com o Vim. A partir daqui começa uma infinitude de informações na qual não podemos entrar nesta pequena introdução.
Mencionarei apenas os comandos que ajudarão você a começar a editar com o Vim:
- pressionar a tecla
xexclui o caractere atualmente destacado - pressionar
Avai para o final da linha atualmente selecionada - pressionar
0para ir para o início da linha - ir para o primeiro caractere de uma palavra e pressionar
dseguido dewpara excluir essa palavra. Se você seguir comeem vez dew, o espaço em branco antes da próxima palavra será preservado - usar um número entre
dewpara excluir mais de 1 palavra – por exemplo, usard3wpara excluir 3 palavras adiante - pressionar
dseguido dedpara excluir uma linha inteira. Pressionardseguido de$para deletar toda a linha de onde está o cursor, até o final
Para saber mais sobre o Vim, recomendo o FAQ do Vim (em inglês). Você também pode executar o comando vimtutor, que já deve estar instalado em seu sistema e o ajudará muito a iniciar a exploração do vim.
O comando do editor emacs no Linux
emacs é um editor incrível e é historicamente considerado o editor de sistemas UNIX. Notoriamente, as guerras violentas entre vi e emacs e discussões acaloradas causaram muitas horas improdutivas para desenvolvedores em todo o mundo.
emacs é muito poderoso. Algumas pessoas usam esse editor o dia todo como uma espécie de sistema operacional (https://news.ycombinator.com/item?id=19127258). Falaremos apenas sobre o básico aqui.
Você pode abrir uma nova sessão do emacs simplesmente invocando emacs:
Usuários do macOS, parem um segundo agora. Se você estiver no Linux, não há problemas, mas o macOS não fornece aplicativos que usam GPLv3 e todos os comandos integrados do UNIX que foram atualizados para GPLv3 não foram atualizados.Embora haja um pequeno problema com os comandos que listei até agora, neste caso, usar uma versão do emacs de 2007 não é exatamente o mesmo que usar uma versão com 12 anos de melhorias e mudanças.Esse não é um problema com o Vim, que está atualizado. Para corrigir isso, executebrew install emacse a execução doemacsusará a nova versão do Homebrew (certifique-se de ter o Homebrew instalado).
Você também pode editar um arquivo existente chamando emacs <nome_do_arquivo>:
Agora, você pode começar a editar. Quando terminar, pressione ctrl-x seguido de ctrl-w. Você confirma a pasta:
O Emacs informa que o arquivo existe, perguntando se ele deve ser sobrescrito:
Responda y e você receberá uma confirmação de sucesso:
Você pode sair do Emacs pressionando ctrl-x seguido de ctrl-c.Como opção, use ctrl-x seguido de c (mantenha ctrl pressionado).
Há muito para saber sobre o Emacs, certamente mais do que sou capaz de escrever nesta pequena introdução. Eu encorajo você a abrir o Emacs e pressionar ctrl-h r para abrir o manual integrado e ctrl-h t para abrir o tutorial oficial.
O comando do editor nano no Linux
nano é um editor amigável para iniciantes.
Execute-o usando nano <nome_do_arquivo>.
Você pode digitar caracteres diretamente no arquivo sem se preocupar com os modos.
Você pode sair sem editar usando ctrl-X. Se você editou o buffer do arquivo, o editor solicitará sua confirmação e você poderá salvar as edições ou descartá-las.
A ajuda na parte inferior mostra os comandos do teclado que permitem trabalhar com o arquivo:
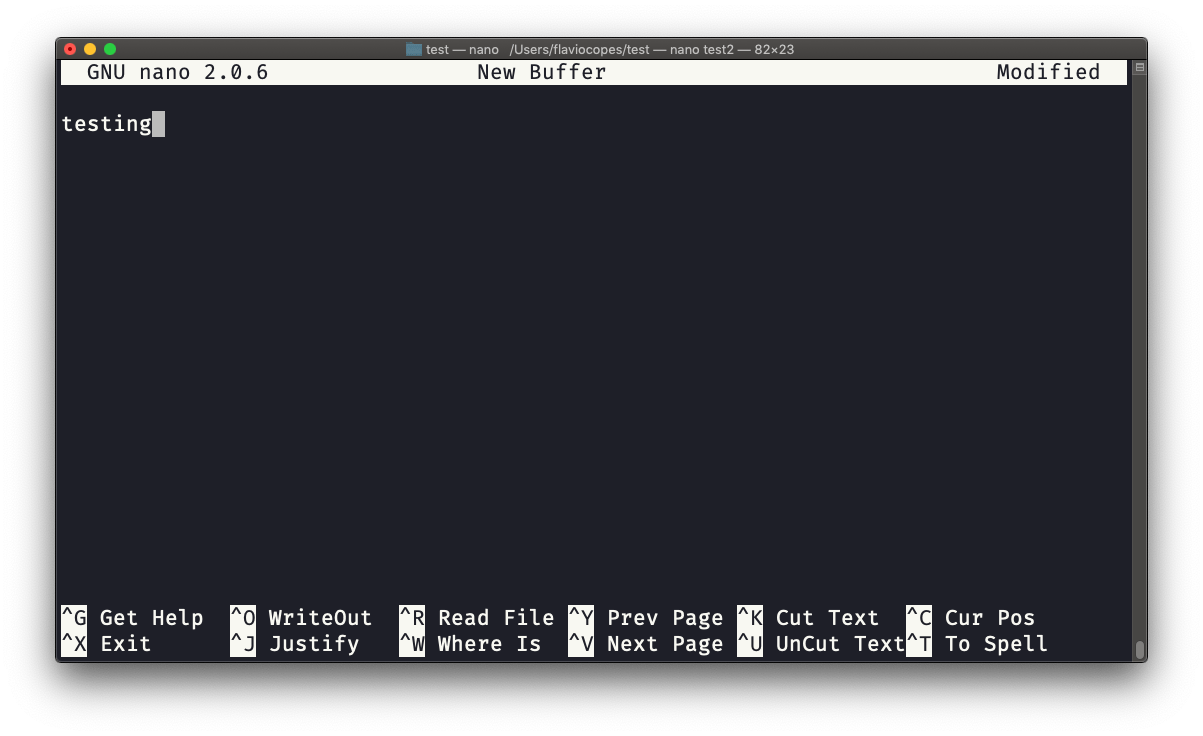
pico é mais ou menos igual, embora nano é a versão GNU do pico que em algum momento da história não era de código aberto. O nano clone foi feito para satisfazer os requisitos de licença do sistema operacional GNU.
O comando whoami no Linux
Digite whoami para imprimir o nome do usuário atualmente conectado à sessão do terminal:
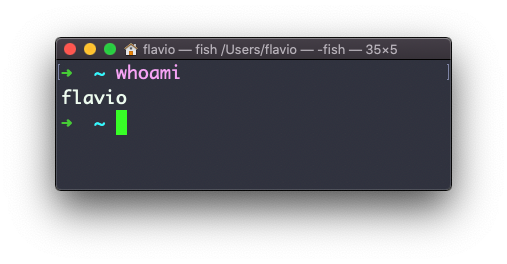
Observação: esse comando é diferente do comando who am i, que imprime mais informaçõesO comando who no Linux
O comando who exibe os usuários logados no sistema.
A menos que você esteja usando um servidor ao qual várias pessoas têm acesso, é provável que você seja o único usuário conectado, várias vezes:
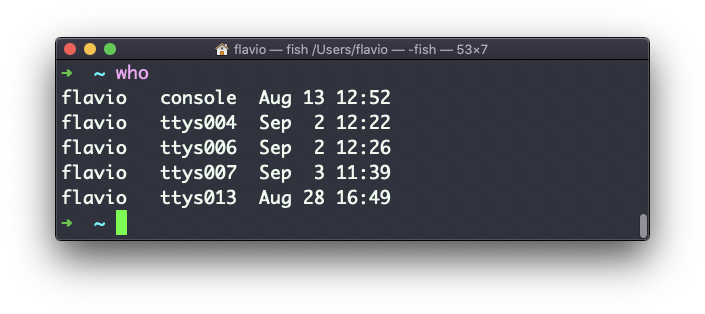
Por que várias vezes? Porque cada shell aberto contará como um acesso.
Você pode ver o nome do terminal utilizado e a hora/dia em que a sessão foi iniciada.
Os sinalizadores -aH dirão who exibirá mais informações, incluindo o tempo ocioso e o ID do processo do terminal:
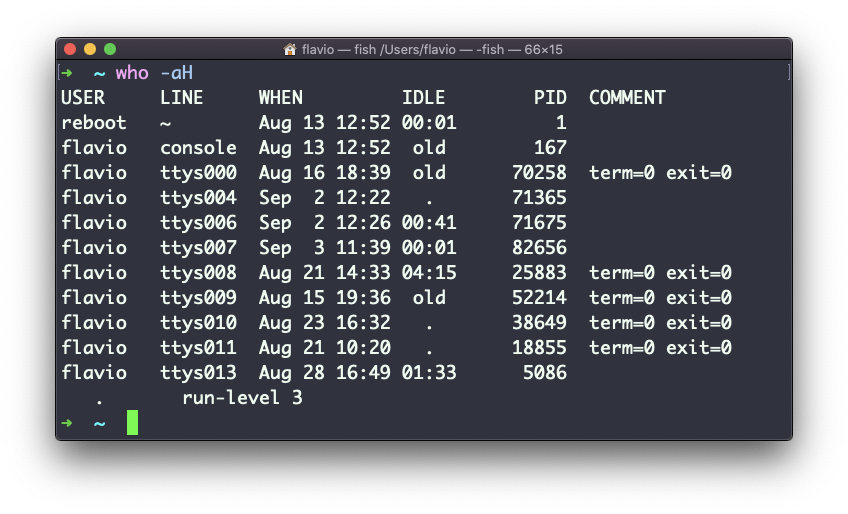
O comando especial who am i listará os detalhes atuais da sessão do terminal:
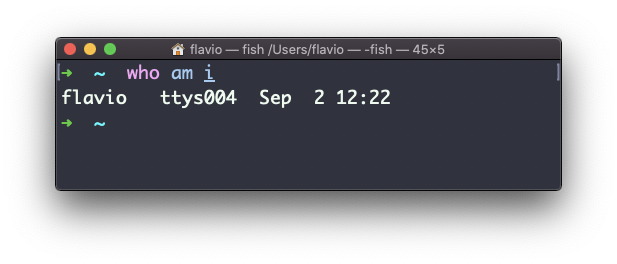
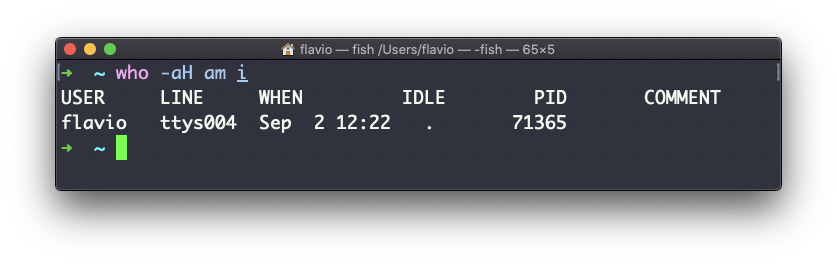
O comando su no Linux
Enquanto você estiver conectado ao shell do terminal com um usuário, pode ser necessário mudar para outro usuário.
Por exemplo, você está logado como root para realizar alguma manutenção, mas deseja mudar para uma conta de usuário.
Você pode fazer isso com o comando su:
su <nome_de_usuário>Por exemplo: su flavio.
Se você estiver logado como usuário, executar su sem mais nada solicitará que você insira a senha do usuário root, pois esse é o comportamento padrão.
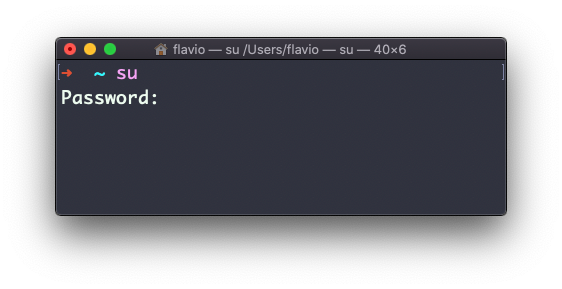
su iniciará um novo shell como outro usuário.
Quando terminar, digitar exit no shell fechará esse shell e retornará ao shell do usuário atual.
O comando sudo no Linux
sudo é comumente usado para executar um comando como root.
Você deve estar habilitado para usar o sudo e, quando estiver, poderá executar comandos como root digitando a senha do seu usuário (não a senha do usuário root).
As permissões são altamente configuráveis, o que é ótimo especialmente em um ambiente de servidor multiusuário. Alguns usuários podem ter acesso para executar comandos específicos por meio de sudo.
Por exemplo, você pode editar um arquivo de configuração do sistema:
sudo nano /etc/hostsDe outra forma, isso não seria salvo, pois você não tem a permissão para isso.
Você pode executar sudo -i para iniciar um shell como root:
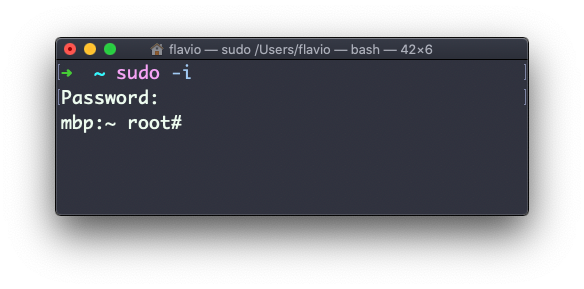
Você pode usar sudo para executar comandos como qualquer usuário. root é o padrão, mas use a opção -u para especificar outro usuário:
sudo -u flavio ls /Users/flavioO comando passwd no Linux
Os usuários do Linux têm uma senha atribuída. Você pode alterar a senha usando o comando passwd.
Existem duas situações aqui.
A primeira é quando você deseja alterar sua senha. Neste caso, você digita:
passwde um prompt interativo solicitará a senha antiga e, em seguida, solicitará a nova:
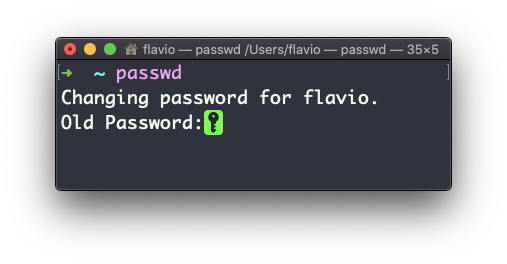
Quando você é root (ou tem privilégios de superusuário), você pode definir o nome de usuário para o qual deseja alterar a senha:
passwd <usuário> <nova_senha>Neste caso, você não precisa inserir a antiga.
O comando ping no Linux
O comando ping faz ping em um host de rede específico, na rede local ou na Internet.
Você o usa com a sintaxe ping <host>, onde <host> pode ser um nome de domínio ou um endereço IP.
Aqui está um exemplo de ping google.com:
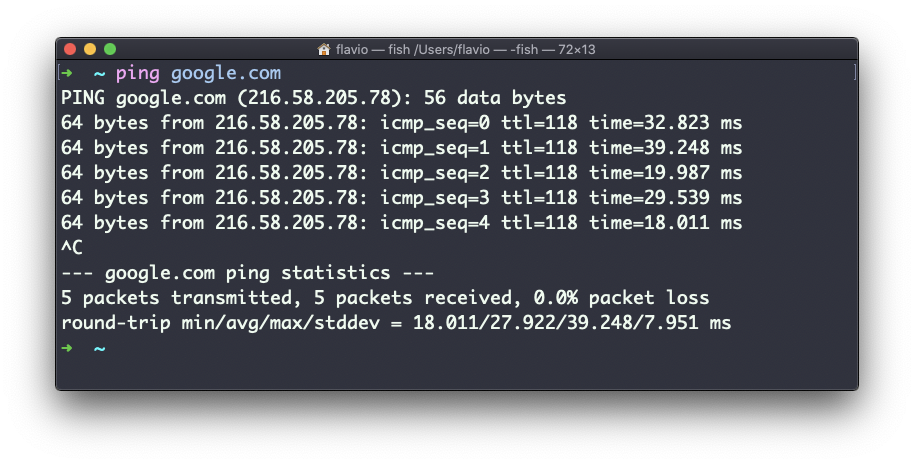
O comando envia uma solicitação ao servidor e o servidor retorna uma resposta.
ping continua enviando a solicitação a cada segundo, por padrão. Ele continuará funcionando até você pará-lo com ctrl-C, a menos que você passe o número de vezes que deseja tentar com a opção -c: ping -c 2 google.com.
Assim que o ping for interrompido, ele imprimirá algumas estatísticas sobre os resultados: a porcentagem de pacotes perdidos e estatísticas sobre o desempenho da rede.
Como você pode ver, a tela imprime o endereço IP do host e o tempo que levou para obter a resposta.
Nem todos os servidores suportam ping, caso a solicitação expire:
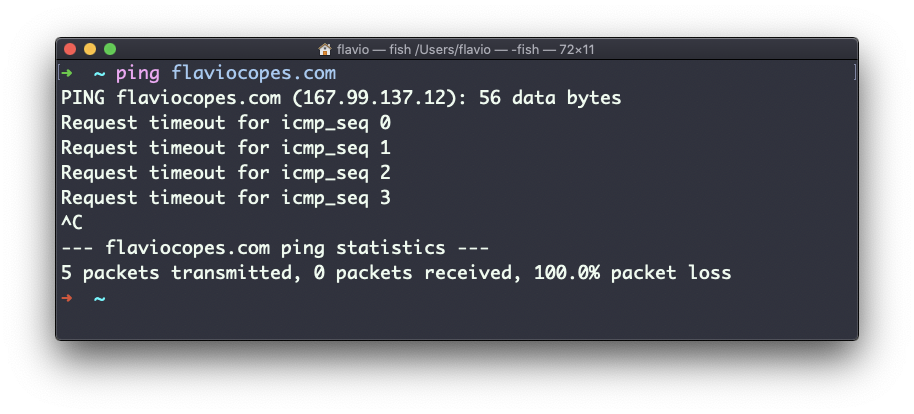
Às vezes isso, é feito propositalmente, para "ocultar" o servidor ou apenas para reduzir a carga. Os pacotes de ping também podem ser filtrados por firewalls.
ping funciona usando o protocolo ICMP (Internet Control Message Protocol), um protocolo de camada de rede como TCP ou UDP.
A solicitação envia um pacote ao servidor com a mensagem ECHO_REQUEST e o servidor retorna uma mensagem ECHO_REPLY. Não vou entrar em detalhes, mas esse é o conceito básico.
Fazer ping em um host é útil para saber se o host está acessível (supondo que ele implemente o ping), assim como a distância que ele está em termos de quanto tempo leva para retornar para você.
Normalmente, quanto mais próximo o servidor estiver geograficamente, menos tempo levará para retornar para você. Leis físicas simples fazem com que uma distância maior introduza mais atraso nos cabos.
O comando traceroute no Linux
Ao tentar acessar um host na Internet, você passa pelo roteador doméstico. Então você chega à rede do seu ISP, que por sua vez passa por seu próprio roteador de rede upstream e assim por diante, até finalmente chegar ao host.
Você já quis saber quais etapas seus pacotes passam para fazer isso?
O comando traceroute é feito para isso.
Você chama
traceroute <host>Ele vai reunir (lentamente) todas as informações enquanto o pacote viaja.
Neste exemplo, tentei acessar meu blog com traceroute flaviocopes.com:
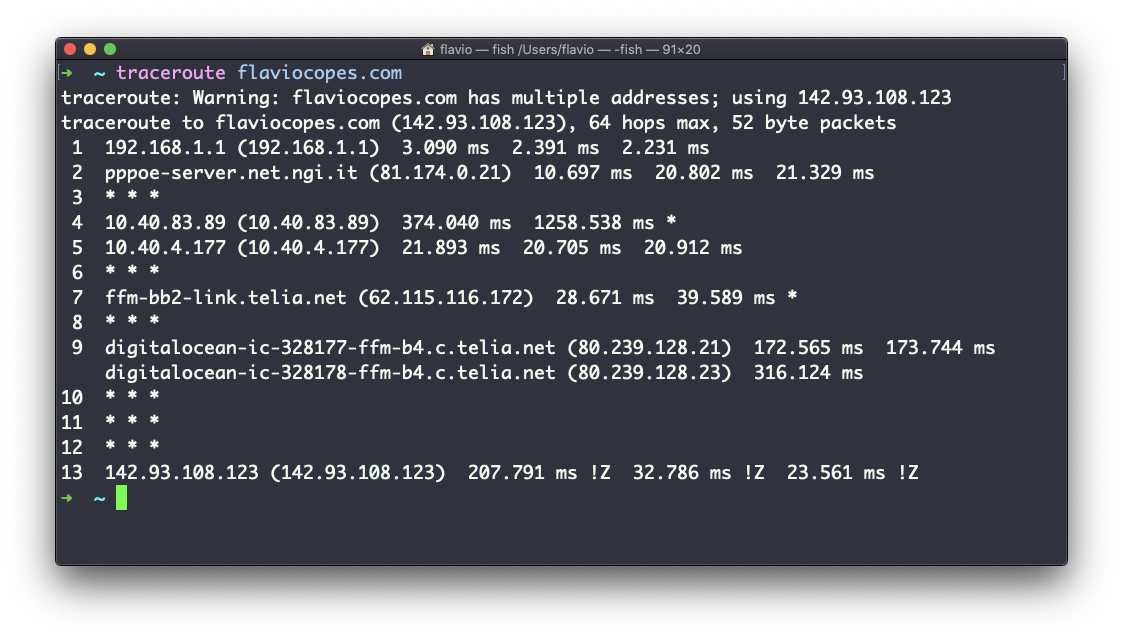
Nem todo roteador percorrido nos retorna informações. Neste caso, traceroute imprime * * *. Caso contrário, podemos ver o nome do host, o endereço IP e alguns indicadores de desempenho.
Para cada roteador, podemos ver 3 amostras, o que significa que o traceroute tenta, por padrão, 3 vezes obter uma boa indicação do tempo necessário para alcançá-lo.
É por isso que leva tanto tempo para executar o traceroute em comparação com simplesmente fazer um ping naquele host.
Você pode personalizar esse número com a opção -q:
traceroute -q 1 flaviocopes.com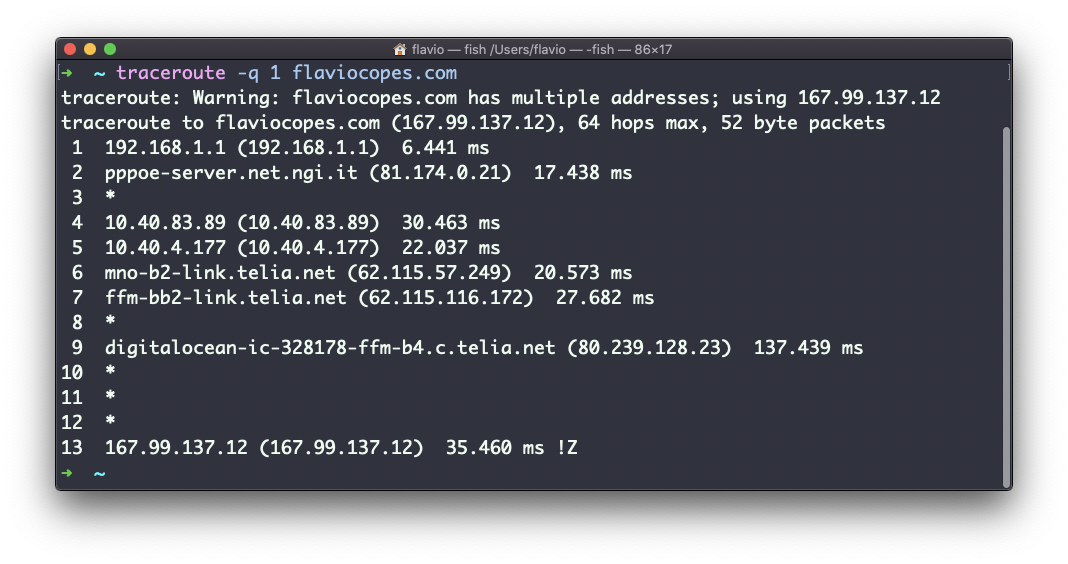
O comando clear no Linux
Digite clear para limpar todos os comandos anteriores que foram executados no terminal atual.
A tela será limpa e você verá apenas o prompt na parte superior:
Observação: este comando possui um atalho útil: ctrl-LDepois de fazer isso, você perderá o acesso à rolagem para ver a saída dos comandos inseridos anteriormente.
Portanto, você pode querer usar clear -x que ainda limpa a tela, mas permite voltar para ver o trabalho anterior rolando para cima.
O comando history no Linux
Cada vez que você executa um comando, ele é memorizado no histórico.
Você pode exibir todo o histórico usando:
historyIsso mostra a história com números:
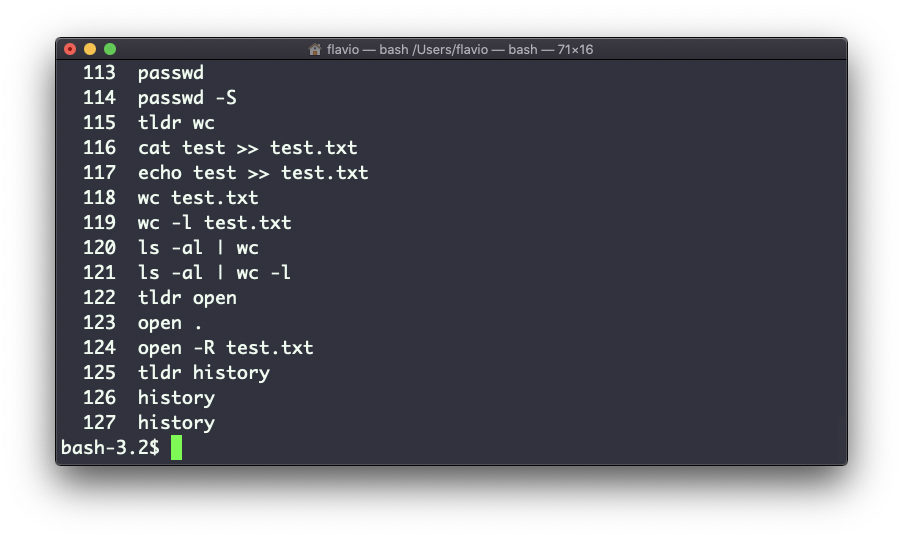
Você pode usar a sintaxe !<comando número> para repetir um comando armazenado no histórico. No exemplo acima, digitar !121 repetirá ls -al | wc -l.
Normalmente, os últimos 500 comandos são armazenados no histórico.
Você pode combinar isso com grep para encontrar um comando que você executou
history | grep docker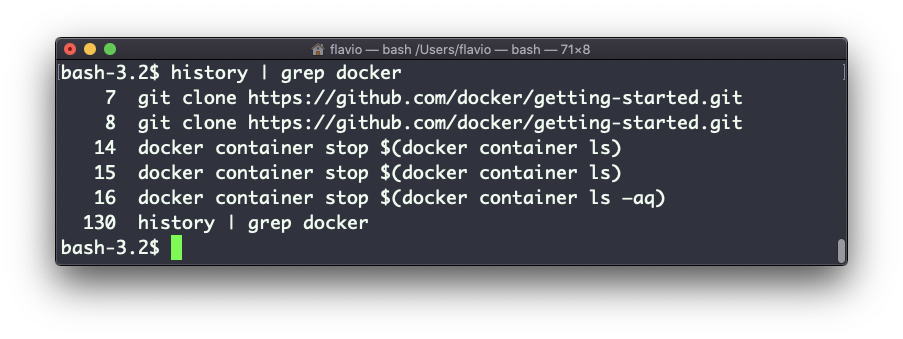
Para limpar o histórico, execute history -c.
O comando export no Linux
O comando export é usado para exportar variáveis para processos filhos.
O que isso significa?
Suponha que você tenha uma variável TEST definida assim:
TEST="test"Você pode imprimir seu valor usando echo $TEST:
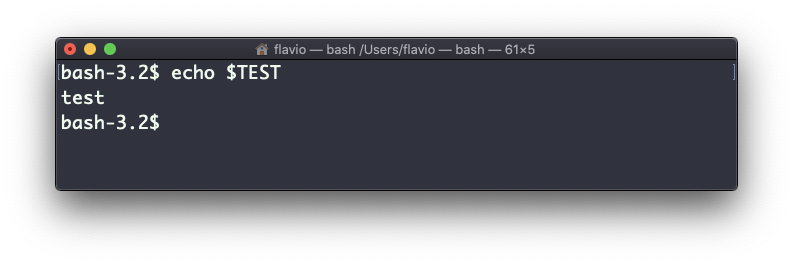
No entanto, você pode tentar definir um script Bash em um arquivo script.sh com o comando acima:
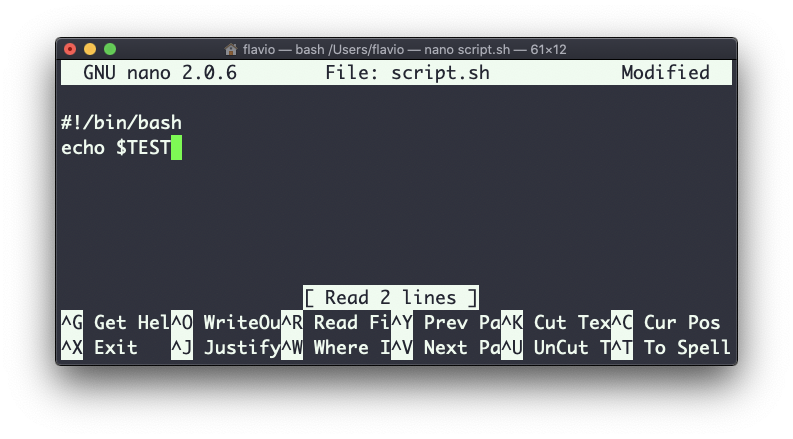
Ao definir chmod u+x script.sh e executar este script com ./script.sh, a linha echo $TEST não imprimirá nada!
Isso ocorre porque, no Bash, a variável TEST foi definida localmente no shell. Ao executar um script de shell ou outro comando, um subshell é iniciado para executá-lo, que não contém as variáveis locais do shell atuais.
Para disponibilizar a variável ali precisamos definir TEST não assim:
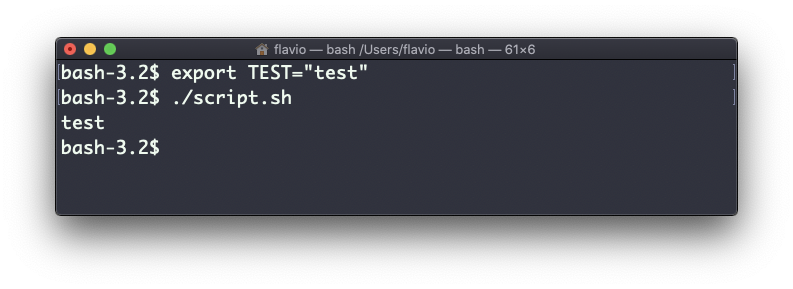
TEST="test"Defina-o assim:
export TEST="test"Tente isso e execute ./script.sh. Agora, ele deve imprimir "test":
Às vezes, você precisa acrescentar algo a uma variável. Geralmente, isso é feito com a variável PATH. Você usa esta sintaxe:
export PATH=$PATH:/new/pathÉ comum usar export quando você cria variáveis dessa maneira. Você, contudo, também pode usá-lo ao criar variáveis nos arquivos de configuração .bash_profile ou .bashrc com Bash, ou em .zshenv com Zsh.
Para remover uma variável, use a opção -n:
export -n TESTChamar export sem qualquer opção listará todas as variáveis exportadas.
O comando crontab no Linux
Cron jobs são jobs agendados para execução em intervalos específicos. Você pode fazer com que um comando execute algo a cada hora, todos os dias, a cada 2 semanas ou nos finais de semana.
Eles são muito poderosos, principalmente quando usados em servidores para realizar manutenções e automações.
O comando crontab é o ponto de entrada para trabalhar com tarefas cron.
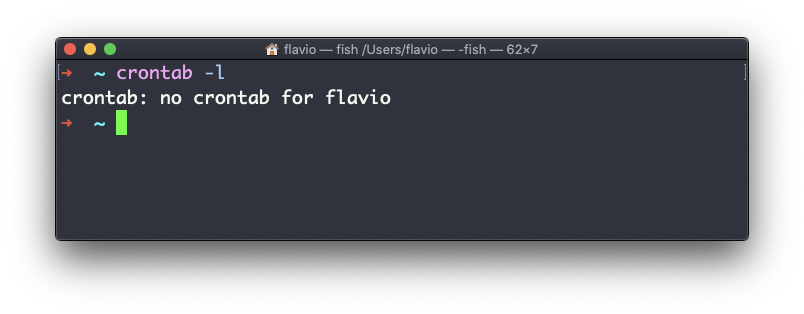
A primeira coisa que você pode fazer é explorar quais cron jobs são definidos por você:
crontab -lVocê pode não ter nenhum, como eu:
Execute
crontab -epara editar os cron jobs e adicionar novos.
Por padrão, isso abre com o editor padrão, que geralmente é o vim. Eu gosto mais do nano. Você pode usar esta linha para usar um editor diferente:
EDITOR=nano crontab -eAgora, você pode adicionar uma linha para cada cron job.
A sintaxe para definir cron jobs é meio assustadora. É por isso que costumo usar um site para me ajudar a gerá-los sem erros: https://crontab-generator.org/
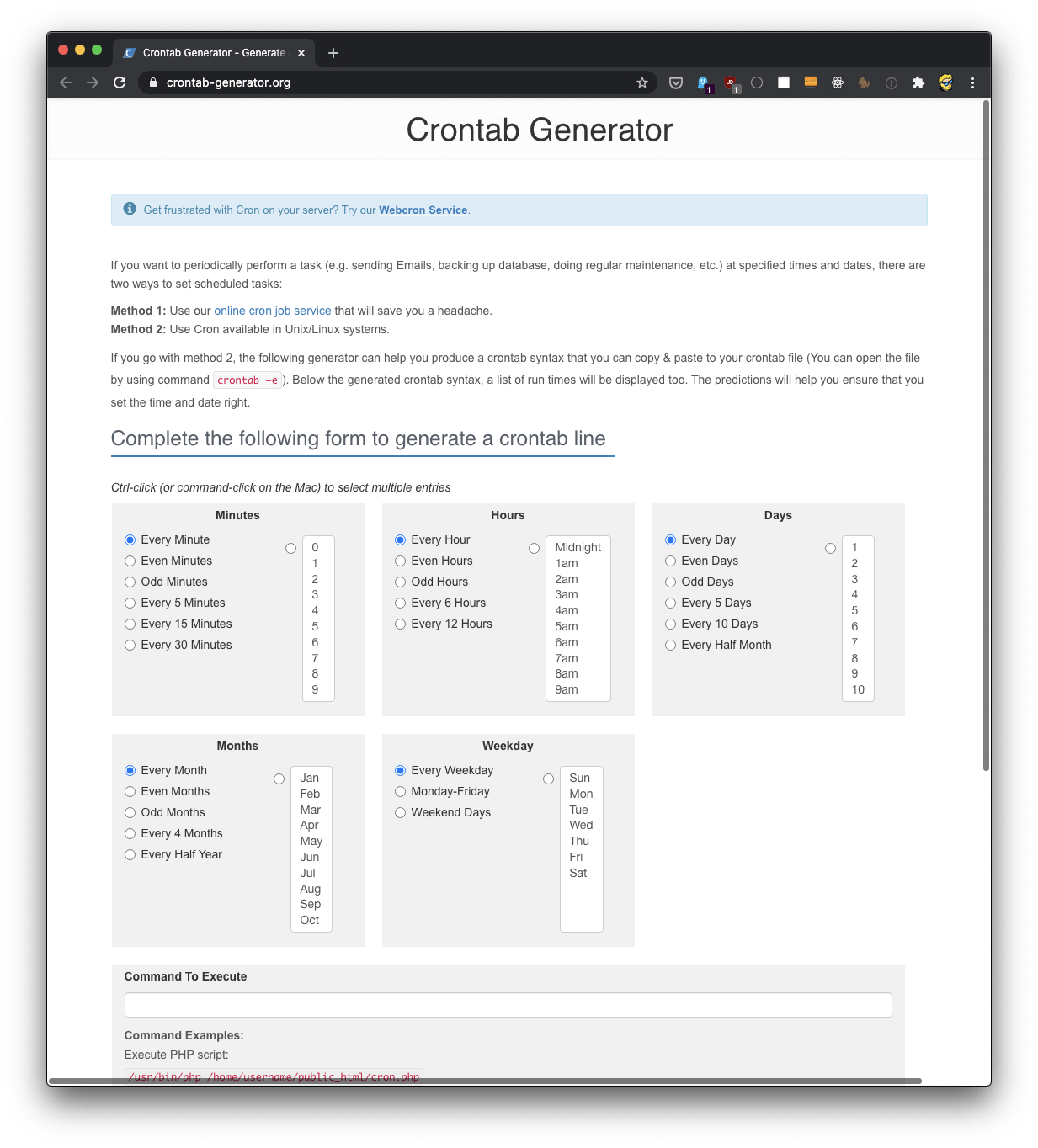
Você escolhe um intervalo de tempo para o cron job e digita o comando a ser executado.
Optei por executar um script localizado em /Users/flavio/test.sh a cada 12 horas. Esta é a linha crontab que preciso executar:
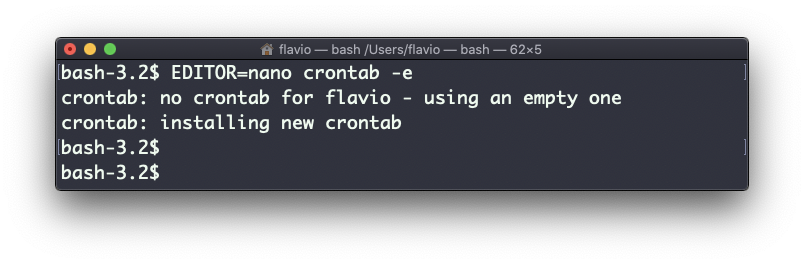
* */12 * * * /Users/flavio/test.sh >/dev/null 2>&1Eu executo crontab -e:
EDITOR=nano crontab -ee adiciono essa linha. Então, pressiono ctrl-X e pressiono y para salvar.
Se tudo correr bem, o cron job está configurado:
Feito isso, você pode ver a lista de cron jobs ativos executando:
crontab -l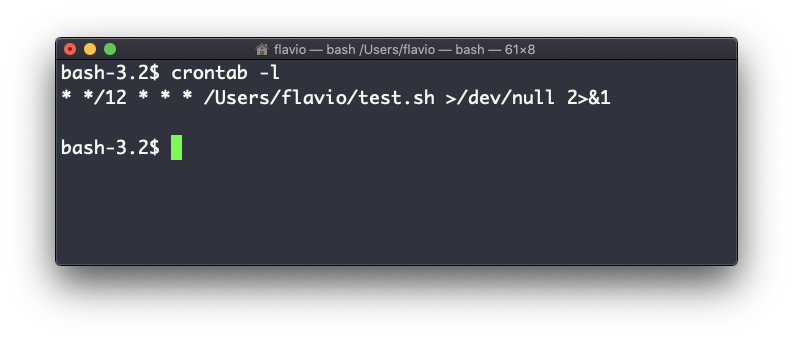
Você pode remover um cron job executando crontab -e novamente, removendo a linha e saindo do editor:
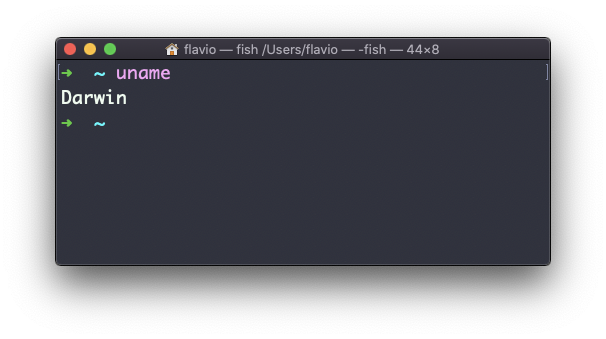
O comando uname no Linux
Chamar uname sem nenhuma opção retornará o codinome do sistema operacional:
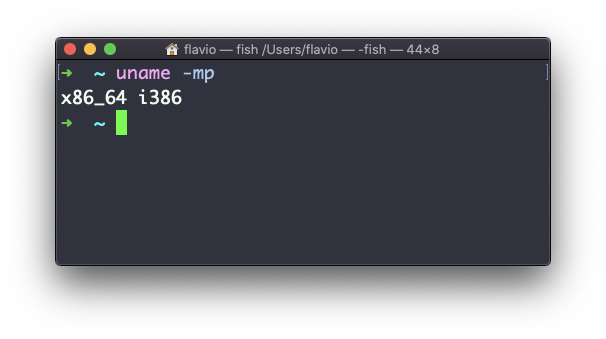
A opção m mostra o nome do hardware (x86_64 neste exemplo) e a opção p imprime o nome da arquitetura do processador (i386 neste exemplo):
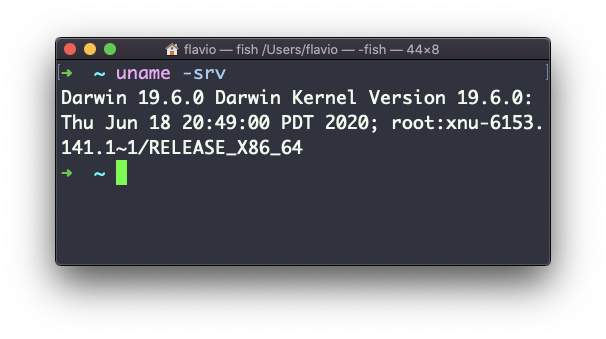
A opção s imprime o nome do sistema operacional. r imprime o lançamento e v imprime a versão:
A opção n imprime o nome da rede do nó:
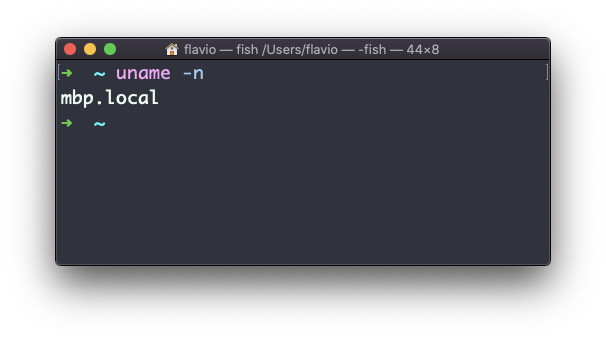
A opção a imprime todas as informações disponíveis:
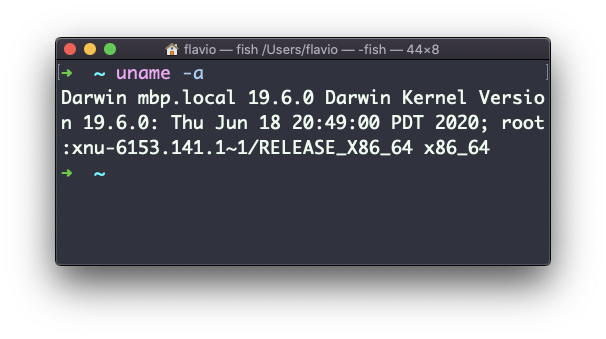
No macOS, você também pode usar o comando sw_vers para imprimir mais informações sobre o sistema operacional macOS. Observe que isso difere da versão Darwin (o Kernel), que acima é 19.6.0.
Darwin é o nome do kernel do macOS. O kernel é o "núcleo" do sistema operacional, enquanto o sistema operacional como um todo é chamado de macOS. No Linux, Linux é o kernel, e GNU/Linux seria o nome do sistema operacional (embora todos nos refiramos a ele como "Linux").
O comando env no Linux
O comando env pode ser usado para passar variáveis de ambiente sem configurá-las no ambiente externo (o shell atual).
Suponha que você queira executar uma aplicação do Node.js e definir a variável USER para ele.
Você pode executar
env USER=flavio node app.jse a variável de ambiente USER estará acessível na aplicação do Node.js por meio da interface Node process.env.
Você também pode executar o comando limpando todas as variáveis de ambiente já definidas, usando a opção -i:
env -i node app.jsNesse caso, você receberá um erro dizendo env: node: No such file or directory porque o comando node não está acessível, pois a variável PATH usada pelo shell para procurar comandos nos caminhos comuns não está definida.
Então, você precisa passar o caminho completo para o programa node:
env -i /usr/local/bin/node app.jsExperimente com um arquivo app.js simples com este conteúdo:
console.log(process.env.NAME)
console.log(process.env.PATH)Você verá a saída como
undefined
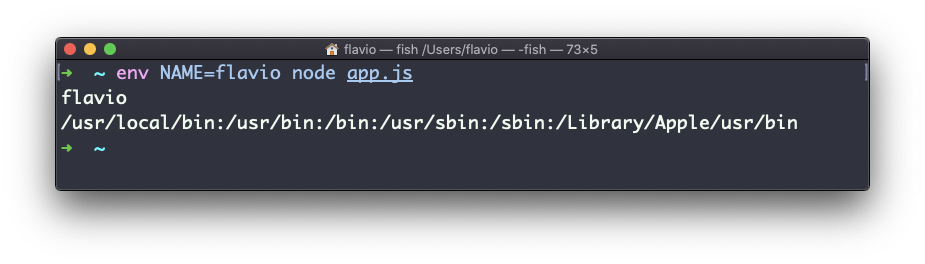
undefinedVocê pode passar uma variável env:
env -i NAME=flavio node app.jse a saída será
flavio
undefinedA remoção da opção-i tornará o PATH disponível novamente dentro do programa:
O comando env também pode ser usado para imprimir todas as variáveis de ambiente. Se executado sem opções:
envEle retornará uma lista das variáveis de ambiente definidas, por exemplo:
HOME=/Users/flavio
LOGNAME=flavio
PATH=/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Library/Apple/usr/bin
PWD=/Users/flavio
SHELL=/usr/local/bin/fishVocê também pode tornar uma variável inacessível dentro do programa que você executa, usando a opção -u. Por exemplo, este código remove a variável HOME do ambiente de comando:
env -u HOME node app.jsO comando printenv no Linux
Aqui está um guia rápido para o comando printenv, usado para imprimir os valores das variáveis de ambiente
Em qualquer shell, há um bom número de variáveis de ambiente, definidas pelo sistema ou por seus próprios scripts e configurações de shell.
Você pode imprimir todos eles no terminal usando o comando printenv. A saída será algo assim:
HOME=/Users/flavio
LOGNAME=flavio
PATH=/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/Library/Apple/usr/bin
PWD=/Users/flavio
SHELL=/usr/local/bin/fishcom mais algumas linhas, geralmente.
Você pode anexar um nome de variável como parâmetro, para mostrar apenas o valor dessa variável:
printenv PATH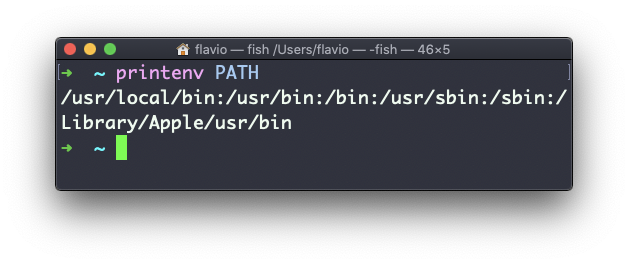
Conclusão
Muito obrigado por ler este manual.
Espero que ele inspire você a aprender mais sobre o Linux e seus recursos. É um conhecimento perene que não ficará desatualizado tão cedo.
Lembre-se de que você pode fazer download deste manual em PDF/ePUB/Mobi se você quiser!
O autor publica tutoriais de programação diariamente em seu site, flaviocopes.com, se você quiser conferir mais conteúdos excelentes como este.
Você pode entrar em contato com o autor através do Twitter.