


Artigo original: A Thorough Introduction to Distributed Systems
Escrito por: Stanislav Kozlovski
O que é um sistema distribuído e por que é tão complicado?
Com a expansão tecnológica cada vez maior do mundo, os sistemas distribuídos estão se tornando cada vez mais difundidos. Eles são um vasto e complexo campo de estudo em ciência da computação.
Este artigo tem como objetivo apresentar a você os sistemas distribuídos de maneira básica, dando uma ideia das diferentes categorias desses sistemas, sem mergulhar profundamente nos detalhes.
O que é um sistema distribuído?
Em sua definição mais simples, um sistema distribuído é um grupo de computadores trabalhando juntos de modo a parecer como um único computador para o usuário final.
Essas máquinas possuem um estado compartilhado, operam de maneira concorrente e podem falhar independentemente sem afetar o tempo de atividade de todo o sistema.
Proponho que trabalhemos gradualmente através de um exemplo de distribuição de um sistema para que você possa ter uma melhor compreensão de tudo isso.
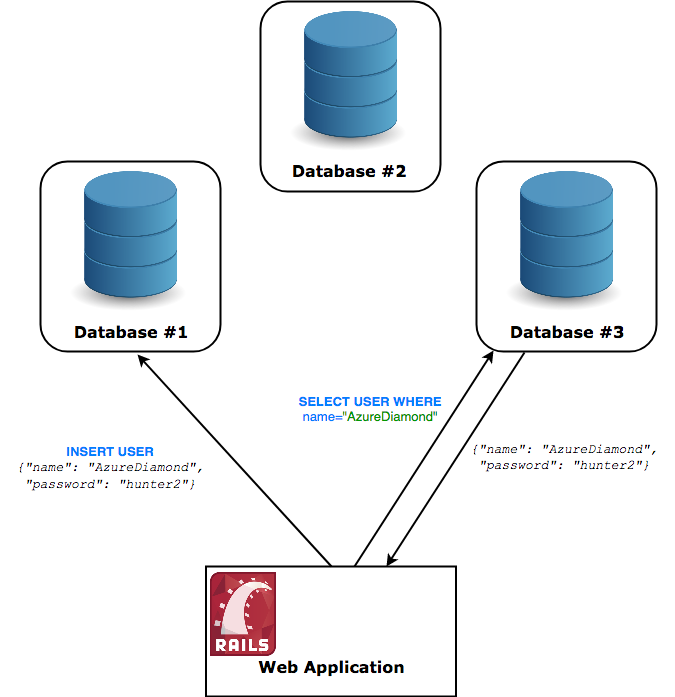
Vamos usar um banco de dados como exemplo! Bancos de dados tradicionais são armazenados no sistema de arquivos de uma única máquina. Sempre que você deseja buscar/inserir informações nele, você se comunica diretamente com aquela máquina.
Para distribuir esse sistema de banco de dados, precisaríamos fazer com que esse banco de dados fosse executado em várias máquinas ao mesmo tempo. O usuário deve ser capaz de se comunicar com qualquer máquina que ele escolha e não deve ser capaz de perceber que não está falando com uma única máquina – se ele insere um registro no nó nº 1, o nó nº 3 deve ser capaz de retornar esse registro.
Por que distribuir um sistema?
Os sistemas são sempre distribuídos por necessidade. A verdade é que gerenciar sistemas distribuídos é um tópico complexo, repleto de armadilhas e desafios. É uma dor de cabeça implantar, manter e depurar sistemas distribuídos. Então, por que seguir por esse caminho afinal?
O que um sistema distribuído possibilita é a escalabilidade horizontal. Voltando ao nosso exemplo anterior do servidor de banco de dados único, a única maneira de lidar com mais tráfego seria atualizar o hardware em que o banco de dados está sendo executado. Isso é chamado de escalonamento vertical.
O escalonamento vertical é válido até certo ponto, mas, após um determinado ponto, você verá que mesmo o melhor hardware não é suficiente para lidar com volume suficiente de tráfego, sem mencionar o fato de que é impraticável para hospedar.
O escalonamento horizontal, por sua vez, significa simplesmente adicionar mais computadores em vez de atualizar o hardware de um único computador.
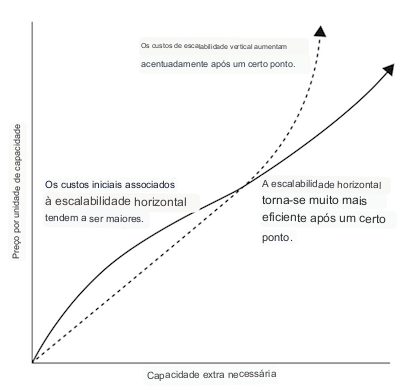
É significativamente mais barato do que o escalonamento vertical após um certo limite, mas esse não é o principal motivo de preferência.
O escalonamento vertical só pode melhorar o desempenho até as capacidades do hardware mais recente. Essas capacidades acabam sendo insuficientes para empresas tecnológicas com cargas de trabalho moderadas a grandes.
A melhor coisa sobre o escalonamento horizontal é que não há limite para o quanto você pode escalar – sempre que o desempenho se degrada, basta adicionar outra máquina, potencialmente até o infinito.
A facilidade de escalonamento não é o único benefício que você obtém com sistemas distribuídos. Tolerância a falhas e baixa latência também são igualmente importantes.
Tolerância a falhas – um cluster de dez máquinas em dois data centers é intrinsecamente mais tolerante a falhas do que uma única máquina. Mesmo que um data center pegue fogo, sua aplicação ainda funcionaria.
Baixa latência – o tempo para um pacote de rede viajar pelo mundo é fisicamente limitado pela velocidade da luz. Por exemplo, o tempo mais curto possível para o tempo de ida e volta de uma solicitação (ou seja, ir e voltar) em um cabo de fibra óptica entre Nova York e Sydney é de 160 ms (texto em inglês). Sistemas distribuídos permitem que você tenha um nó em ambas as cidades, permitindo que o tráfego atinja o nó mais próximo.
No entanto, para que um sistema distribuído funcione, é necessário que o software em execução nessas máquinas seja projetado especificamente para ser executado em vários computadores ao mesmo tempo e que lide com os problemas que surgem com isso. Isso acaba sendo uma tarefa complicada.
Escalonando nosso banco de dados
Imagine que nossa aplicação para a web se tornou extremamente popular. Imagine também que nosso banco de dados começou a receber o dobro de consultas por segundo do que ele pode lidar. Essa aplicação começaria imediatamente a perder desempenho e isso seria percebido por nossos usuários.
Vamos trabalhar juntos e fazer com que nosso banco de dados aumente sua capacidade para atender essas altas demandas.
Em uma aplicação para a web típica, geralmente se lê informações com muito mais frequência do que se insere novas informações ou se modifica as antigas.
Existe uma maneira de aumentar o desempenho de leitura e é chamada de estratégia primary-replica replication (replicação entre mestre-escravo). Você cria dois servidores de banco de dados que sincronizam com o servidor principal. A pegadinha é que você só pode fazer leituras dessas novas instâncias.
Sempre que você inserir ou modificar informações, você se comunica com o banco de dados principal. Ele, por sua vez, informa as réplicas assincronamente sobre a mudança e elas também a salvam.
Parabéns, agora você pode executar três vezes mais consultas de leitura! Não é ótimo?
Armadilha
Peguei vocês! Perdemos imediatamente o "C" nas garantias ACID (texto em inglês) de nosso banco de dados relacional, a Consistência.
Perceba que, agora, existe a possibilidade de inserirmos um novo registro no banco de dados e, imediatamente após, realizarmos uma consulta de leitura para esse registro e não obtermos nenhuma resposta de volta, como se ele não existisse!
A propagação de novas informações do primário para a réplica não acontece instantaneamente. Na verdade, existe uma janela de tempo em que você pode obter informações desatualizadas. Se não fosse assim, o desempenho da gravação seria prejudicado, pois teria que aguardar sincronamente a propagação dos dados.
Sistemas distribuídos envolvem algumas escolhas e renúncias (trade-offs em inglês). Essa questão em particular é algo com que você terá que conviver se quiser escalar adequadamente.
Continuando a Escalonar
Utilizando a abordagem do banco de dados replicado, podemos escalonar horizontalmente nosso tráfego de leitura até certo ponto. Isso é ótimo, mas encontramos um obstáculo em relação ao nosso tráfego de escrita — ele ainda está todo em um único servidor!
Não temos muitas opções aqui. Simplesmente precisamos dividir nosso tráfego de escrita entre vários servidores, já que um não é capaz de lidar com isso.
Uma maneira é adotar uma estratégia de replicação multi-primária (texto em inglês). Nesse caso, em vez de réplicas as quais você só pode ler, você tem vários nós primários que suportam leitura e escrita. Infelizmente, isso se torna complicado rapidamente, pois você agora tem a capacidade de criar conflitos (por exemplo, inserir dois registros com o mesmo ID – texto em inglês).
Vamos adotar outra técnica chamada fragmentação (também chamada de particionamento – texto em inglês).
Com a fragmentação, você divide o seu servidor em vários servidores menores, chamados de fragmentos (shards, em inglês) Esses fragmentos contêm registros diferentes — você cria uma regra para determinar que tipo de registros é armazenado em cada fragmento. É muito importante criar a regra de tal maneira que os dados sejam distribuídos de modo uniforme.
Uma abordagem possível para isso é definir intervalos de acordo com alguma informação sobre um registro (por exemplo, usuários com nomes de A a D).
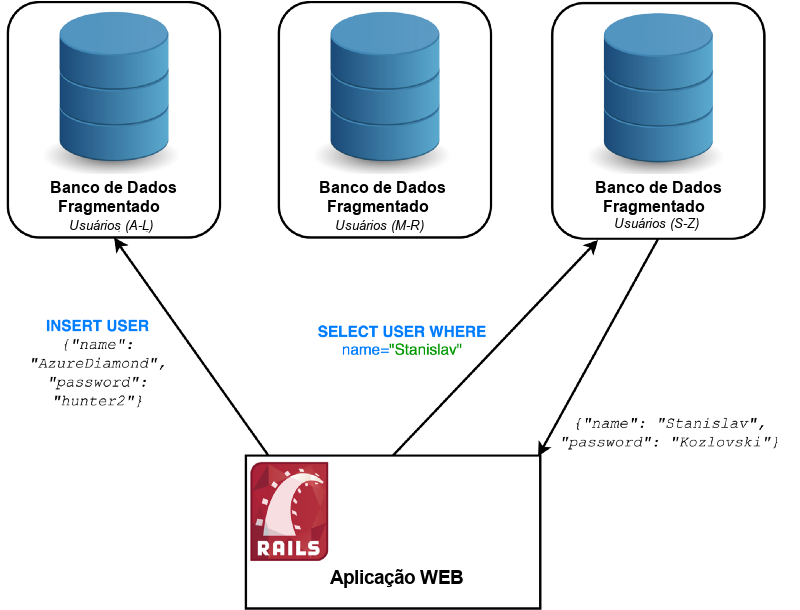
Essa abordagem de fragmentação deve ser escolhida com muito cuidado, pois a carga nem sempre é igual com base em colunas arbitrárias. (por exemplo, mais pessoas têm nomes que começam com C em vez de Z). Um único fragmento que recebe mais solicitações do que outros é chamado de hot spot (ponto de acesso) e deve ser evitado. Depois de divididos, a nova fragmentação dos dados torna-se incrivelmente cara e pode causar um significativo tempo de indisponibilidade, como foi o infame caso das 11 horas de indisponibilidade do Foursquare (texto em inglês).
Para manter nosso exemplo simples, suponha que nosso client (a aplicação em Rails) saiba qual banco de dados usar para cada registro. Também vale ressaltar que existem muitas estratégias para o particionamento e esse é um exemplo simples para ilustrar o conceito.
No momento, já obtivemos bastante sucesso – podemos aumentar nosso tráfego de gravação N vezes, onde N é o número de fragmentos. Isso praticamente nos deixa quase sem limites – imagine o nível de granularidade que podemos ter com essa divisão.
Armadilha
Tudo na Engenharia de Software é mais ou menos escolhas e renúncias (trade-offs em inglês), e isso não é uma exceção. O particionamento não é uma tarefa simples e é melhor evitá-lo até que seja realmente necessário (texto em inglês).
Agora, tornamos as consultas por chaves diferentes das chaves particionadas incrivelmente ineficientes (elas precisam passar por todos os fragmentos). As consultas de SQL JOIN são ainda piores e complexas, tornam-se praticamente inutilizáveis.
Decentralizado x distribuído
Antes de prosseguirmos, gostaria de fazer uma distinção entre esses dois termos.
Embora as palavras soem semelhantes e possam ser concluídas como significando o mesmo logicamente, suas diferenças têm um impacto tecnológico e político significativo.
Descentralizado ainda é distribuído no sentido técnico, mas todo o sistema descentralizado não é de propriedade de um único ator. Nenhuma empresa pode possuir um sistema descentralizado. Caso contrário, ele deixaria de ser descentralizado.
Isso significa que a maioria dos sistemas que discutiremos hoje pode ser considerada como sistemas centralizados distribuídos – e é isso que eles foram projetados para ser.
Se você pensar a respeito, é mais difícil criar um sistema descentralizado porque é preciso lidar com a situação em que alguns dos participantes são mal-intencionados. Isso não ocorre com sistemas distribuídos normais, pois você sabe que é o proprietário de todos os nós.
Observação: essa definição tem sido bastante debatida (texto em inglês) e pode ser confundida com outras (peer-to-peer, federado). Em literatura mais antiga, também foi definida de maneira diferente (texto em inglês). Independentemente disso, o que forneci como definição é o que considero ser o mais amplamente utilizado agora, especialmente após a popularização dos termos blockchain e criptomoedas.
Categorias de sistemas distribuídos
Agora vamos explorar algumas categorias de sistemas distribuídos e listar seus maiores usos conhecidos publicamente. Tenha em mente que a maioria dos números apresentados está desatualizada e, provavelmente, é significativamente maior no momento em que você está lendo isso.
Armazenamento distribuídos de dados
Os armazenamentos distribuídos de dados são mais amplamente utilizados e reconhecidos como bancos de dados distribuídos. A maioria dos bancos de dados distribuídos são NoSQL (texto em inglês), ou seja, bancos de dados não relacionais, limitados à semântica chave-valor. Eles oferecem desempenho e escalabilidade incríveis, mas isso ocorre às custas da consistência ou disponibilidade.
Escala conhecida – a Apple é conhecida por utilizar 75.000 nós do Apache Cassandra, armazenando mais de 10 petabytes de dados (texto em inglês).
Não podemos entrar em discussões sobre armazenamento distribuído de dados sem primeiro introduzir o Teorema CAP.
Teorema CAP
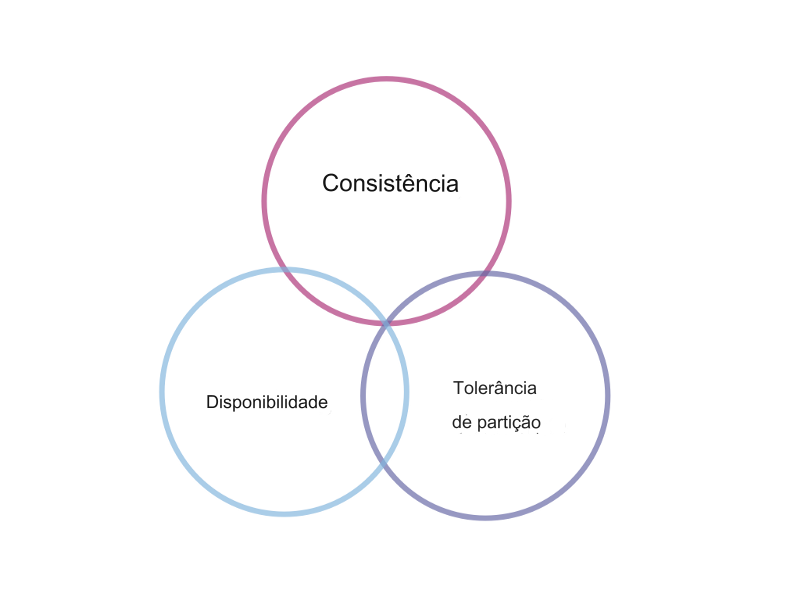
Comprovado pela primeira vez em 2002 (texto em inglês), o Teorema CAP (sigla em inglês para Consistency, Availability e Partition Tolerance) estabelece que um sistema de armazenamento de dados distribuído não pode simultaneamente manter consistência, estar sempre disponível e ser tolerante a partições.
Algumas definições rápidas:
- Consistência — o que você lê e escreve sequencialmente é o que é esperado (lembre-se da situação complicada com a replicação do banco de dados mencionada alguns parágrafos atrás?).
- Disponibilidade — o sistema como um todo não falha — todo nó não defeituoso sempre retorna uma resposta.
- Tolerância a partições — o sistema continua a funcionar e manter suas garantias de consistência/disponibilidade apesar das partições na rede (texto em inglês).
Na realidade, a tolerância a partições deve ser uma premissa para qualquer armazenamento de dados distribuído. Conforme mencionado em vários lugares, como citado neste ótimo artigo (texto em inglês), não é possível ter consistência e disponibilidade sem tolerância a partições.
Reflexão: se você tiver dois nós que aceitam informações e a conexão entre eles for interrompida, como ambos poderão estar disponíveis e fornecer consistência ao mesmo tempo? Eles não têm conhecimento do que o outro nó está fazendo, podendo assim ficar off-line (indisponíveis) ou operar com informações desatualizadas (inconsistentes).
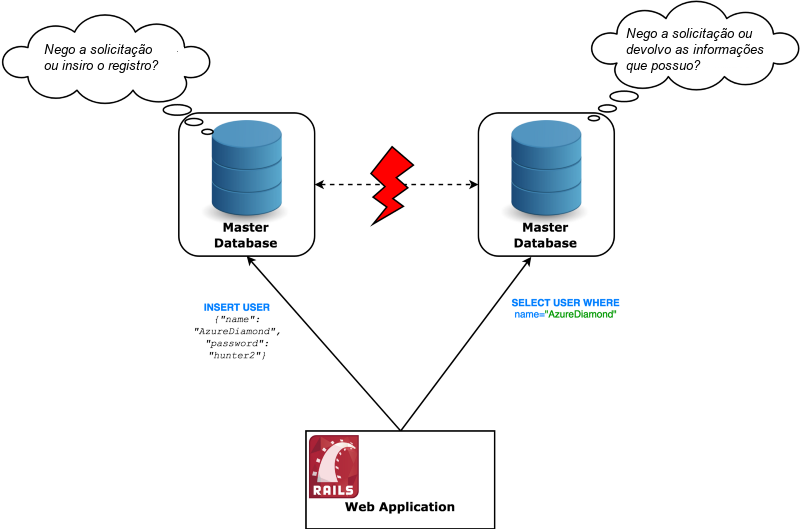
No final, você precisa escolher se deseja que seu sistema seja fortemente consistente ou altamente disponível em caso de uma partição de rede.
A prática mostra que a maioria das aplicações valoriza mais a disponibilidade. Você nem sempre precisa necessariamente de uma consistência forte. Mesmo assim, essa compensação não é necessariamente feita porque você precisa da garantia de 100% de disponibilidade, mas sim porque a latência da rede pode ser um problema quando é necessário sincronizar máquinas para obter uma consistência forte. Esses e outros fatores fazem com que as aplicações normalmente optem por soluções que ofereçam alta disponibilidade.
Esses bancos de dados se contentam com o modelo de consistência mais fraco – consistência eventual (explicação de consistência forte versus consistência eventual – texto em inglês). Esse modelo garante que se nenhuma nova atualização for feita em um determinado item, eventualmente todos os acessos a esse item retornarão o último valor atualizado.
Esses sistemas fornecem propriedades BASE (em oposição ao ACID dos bancos de dados tradicionais):
- Basically Available — basicamente disponível — o sistema sempre retorna uma resposta
- Soft state — estado suave — o sistema pode mudar com o tempo, mesmo durante períodos sem entrada (devido a eventual consistência)
- Eventual consistency — consistência eventual — na ausência de entrada, os dados se espalharão para todos os nós, mais cedo ou mais tarde — tornando-se assim consistentes
Exemplos de tais bancos de dados distribuídos disponíveis — Cassandra, Riak, Voldemort (texto em inglês)
Claro, existem outros armazenamentos de dados que preferem consistência mais forte — HBase, Couchbase, Redis, Zookeeper (texto em inglês)
O teorema CAP é digno de vários artigos por si só – alguns sobre como você pode ajustar as propriedades CAP de um sistema dependendo de como o client se comporta (texto em inglês) e outros sobre como ele não é compreendido corretamente (texto em inglês).
Cassandra
Cassandra, como mencionado acima, é um banco de dados No-SQL distribuído que prefere as propriedades do AP fora do CAP, estabelecendo-se com consistência eventual. Devo admitir que isso pode ser um pouco enganador, já que o Cassandra é altamente configurável — você também pode fazer com que ele forneça uma consistência forte em detrimento da disponibilidade, mas esse não é seu caso de uso comum.
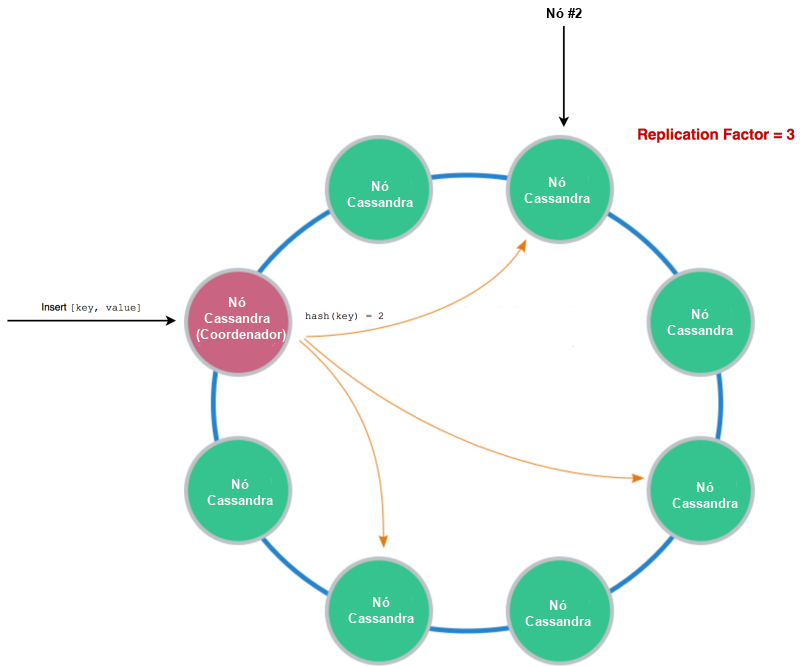
Cassandra utiliza hashing consistente (texto em inglês) para determinar quais nós do seu cluster devem gerenciar os dados que você está passando. Você define um fator de replicação, que basicamente indica para quantos nós você deseja replicar seus dados.
Ao ler, você lerá apenas desses nós.
Cassandra é altamente escalável, proporcionando uma taxa de transferência de escrita absurdamente alta.
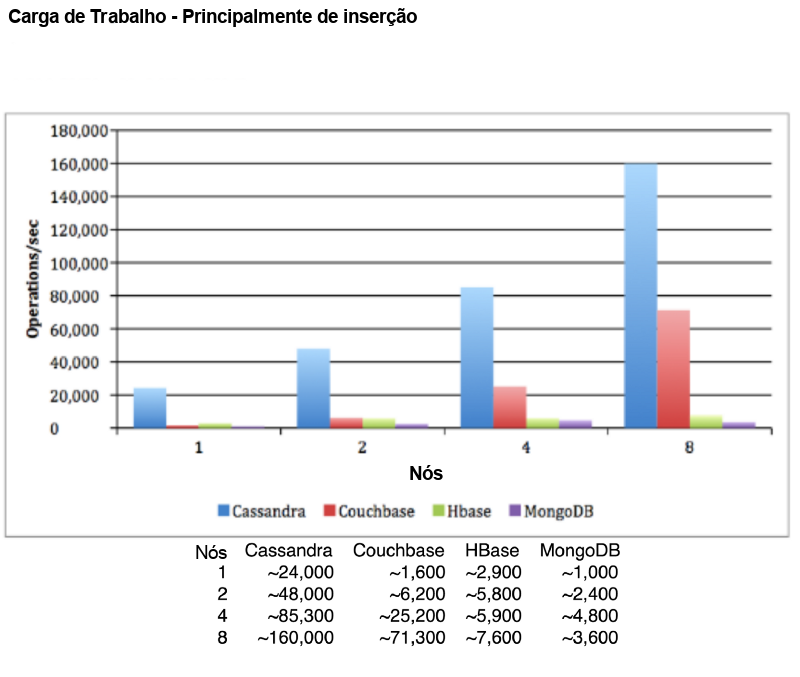
Mesmo que esse diagrama possa ser tendencioso e pareça que compara Cassandra a bancos de dados configurados para fornecer consistência forte (caso contrário, não consigo ver por que o MongoDB diminuiria o desempenho quando atualizado de 4 para 8 nós), isso ainda deve mostrar o que é configurado corretamente até o cluster Cassandra é capaz.
Independentemente disso, no trade-off de sistemas distribuídos que permite escalabilidade horizontal e rendimento incrivelmente alto, o Cassandra não fornece alguns recursos fundamentais dos bancos de dados ACID – ou seja, transações.
Consenso
As transações de banco de dados são difíceis de implementar em sistemas distribuídos, pois exigem que cada nó concorde sobre a ação correta a ser tomada (abortar ou confirmar). Isso é conhecido como consenso e é um problema fundamental em sistemas distribuídos.
Alcançar o tipo de acordo necessário para o problema de "confirmação de transação" é simples se os processos participantes e a rede forem completamente confiáveis. No entanto, os sistemas reais estão sujeitos a uma série de falhas possíveis, como falhas de processos, particionamento de rede e mensagens perdidas, distorcidas ou duplicadas.
Isto levanta um problema: provou-se ser impossível (texto em inglês) garantir que um consenso correto seja alcançado dentro de um prazo limitado em uma rede não confiável.
Na prática, porém, existem algoritmos que chegam rapidamente a um consenso em uma rede não confiável. Na verdade, Cassandra fornece transações leves por meio do uso do algoritmo Paxos para consenso distribuído.
Computação distribuída
A computação distribuída é a chave para o fluxo de processamento de Big Data que temos visto nos últimos anos. É a técnica de dividir uma tarefa enorme (por exemplo, agregar 100 bilhões de registos), que nenhum computador é capaz de executar praticamente por si só, em muitas tarefas mais pequenas, cada uma das quais pode caber numa única máquina comum. Você divide sua enorme tarefa em muitas tarefas menores, executa-as em muitas máquinas em paralelo, agrega os dados adequadamente e resolve seu problema inicial. Essa abordagem novamente permite escalar horizontalmente – quando você tem uma tarefa maior, basta incluir mais nós no cálculo.
Folding@Home 160 mil máquinas ativas em 2012 (texto em inglês)
Um dos primeiros inovadores neste espaço foi o Google, que devido à necessidade de suas grandes quantidades de dados teve que inventar um novo paradigma para computação distribuída – MapReduce. Eles publicaram um artigo sobre isso em 2004 (texto em inglês) e a comunidade de código aberto mais tarde criou o Apache Hadoop (texto em inglês) baseado nele.
MapReduce
MapReduce pode ser definido simplesmente como duas etapas – mapear os dados (Map) e reduzi-los a algo significativo (Reduce).
Vamos ver um exemplo novamente:
Digamos que somos a Medium (Plataforma de publicação de artigos) e armazenamos nossas enormes informações em um banco de dados secundário distribuído para fins de armazenamento. Queremos buscar dados que representem o número de palmas enviadas todos os dias durante o mês de abril de 2017 (um ano antes da edição original deste artigo).
Este exemplo é o mais curto, claro e simples possível, mas imagine que estamos trabalhando com muitos dados (por exemplo, analisando bilhões de aplausos). Obviamente, não armazenaremos todas essas informações em uma máquina e não analisaremos tudo isso em apenas uma máquina. Também não consultaremos o banco de dados de produção, mas algum banco de dados de "armazém" construído especificamente para trabalhos off-line de baixa prioridade.
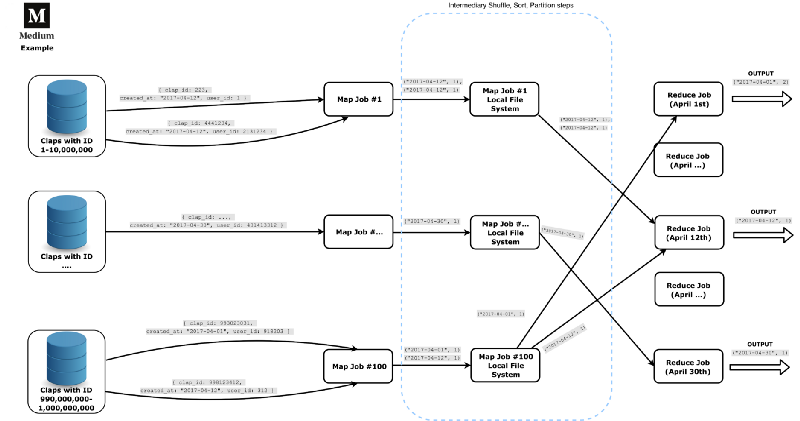
Cada trabalho Map é um nó separado que transforma o máximo de dados possível. Cada trabalho percorre todos os dados em um determinado nó de armazenamento e os mapeia para uma tupla simples da data e do número um. Em seguida, são realizadas três etapas intermediárias (das quais ninguém fala) – Shuffle, Sort e Partition. Elas basicamente organizam ainda mais os dados e os excluem para o trabalho de redução apropriado. Como estamos lidando com Big Data, separamos cada trabalho de Reduce para funcionar apenas em uma única data.
Esse é um bom paradigma e surpreendentemente permite que você faça muitas coisas com ele — você pode encadear vários trabalhos MapReduce, por exemplo.
Melhores técnicas
O MapReduce é um tanto legado nos dias de hoje e traz alguns problemas consigo. Por trabalhar em lotes (jobs), surge um problema onde, se o seu job falhar, você precisa reiniciar tudo do zero. Um job de 2 horas falhando pode realmente retardar todo o seu pipeline de processamento de dados e você definitivamente não quer isso, especialmente nas horas de pico.
Outra questão é o tempo que você espera até receber os resultados. Em sistemas analíticos em tempo real (onde todos têm big data e, portanto, usam computação distribuída), é importante que os seus dados mais recentes estejam o mais novos possível e certamente não sejam de algumas horas atrás.
Como resultado, surgiram outras arquiteturas (texto em inglês) que abordam esses problemas. Nomeadamente, a arquitetura Lambda (uma mistura de processamento em lote e processamento em fluxo – texto em inglês) e a arquitetura Kappa (apenas processamento em fluxo – texto em inglês). Esses avanços no campo trouxeram novas ferramentas que os possibilitam — Kafka Streams, Apache Spark, Apache Storm, Apache Samza.
Sistemas de arquivos distribuídos
Os sistemas de arquivos distribuídos podem ser considerados como armazenamentos de dados distribuídos. São a mesma coisa como conceito — armazenar e acessar uma grande quantidade de dados em um cluster de máquinas, todas aparecendo como uma só. Eles geralmente andam de mãos dadas com a Computação Distribuída.
Escala conhecida – O Yahoo é conhecido por executar o HDFS em mais de 42.000 nós para armazenamento de 600 Petabytes de dados, lá em 2011
A diferença é que os sistemas de arquivos distribuídos permitem que os arquivos sejam acessados usando as mesmas interfaces e semânticas que os arquivos locais, e não por meio de uma API personalizada como a Cassandra Query Language (CQL).
HDFS
O Hadoop Distributed File System (HDFS) é o sistema de arquivos distribuídos usado para computação distribuída através do framework Hadoop. Com ampla adoção, é utilizado para armazenar e replicar grandes arquivos (de GB ou TB em tamanho) em muitas máquinas.
Sua arquitetura consiste principalmente em NameNodes e DataNodes. Os NameNodes são responsáveis por manter o metadata sobre o cluster, como qual nó contém quais blocos de arquivos. Eles atuam como coordenadores da rede, determinando onde é melhor armazenar e replicar arquivos, além de monitorar a saúde do sistema. Os DataNodes simplesmente armazenam arquivos e executam comandos como replicar um arquivo, escrever um novo entre outros.
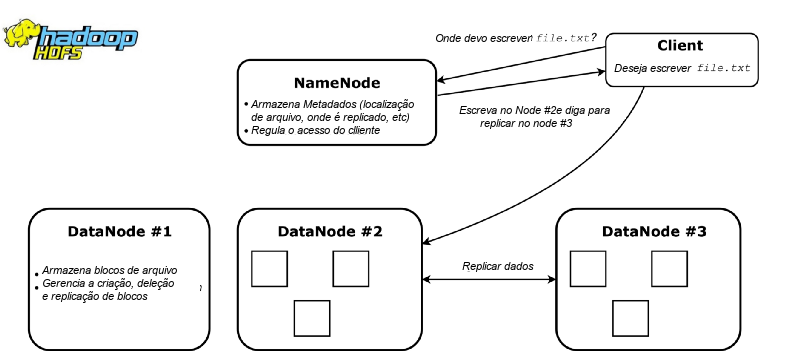
Não surpreendentemente, o HDFS é melhor utilizado com o Hadoop para computação, pois fornece consciência de dados para os jobs de computação. Esses jobs são então executados nos nós que armazenam os dados. Isso aproveita a localidade dos dados — otimizando as computações e reduzindo a quantidade de tráfego na rede.
IPFS
O Interplanetary File System (IPFS – texto em inglês), sistema de arquivos interplanetário, é um novo e empolgante protocolo de rede peer-to-peer para um sistema de arquivos distribuídos. Aproveitando a tecnologia Blockchain (texto em inglês), ele possui uma arquitetura completamente descentralizada, sem um único proprietário ou ponto de falha.
O IPFS oferece um sistema de nomes (semelhante ao DNS) chamado IPNS e permite que os usuários acessem facilmente informações. Ele armazena arquivos por meio de versionamento histórico, semelhante ao que o Git (texto em inglês) faz. Isso permite o acesso a todos os estados anteriores de um arquivo.
Ainda está passando por um desenvolvimento intenso (versão 0.4 no momento desta edição), mas já viu projetos interessados em construir sobre ele (FileCoin, texto em inglês).
Messageria distribuída
Sistemas de mensageria fornecem um local central para armazenamento e propagação de mensagens/eventos dentro do seu sistema geral. Eles permitem que você desacople a lógica de sua aplicação de falar diretamente com seus outros sistemas.
Escala conhecida – o cluster Kafka do LinkedIn processou 1 trilhão de mensagens por dia, com picos de 4,5 milhões de mensagens por segundo (texto em inglês).
Simplificando, uma plataforma de mensagens funciona da seguinte maneira:
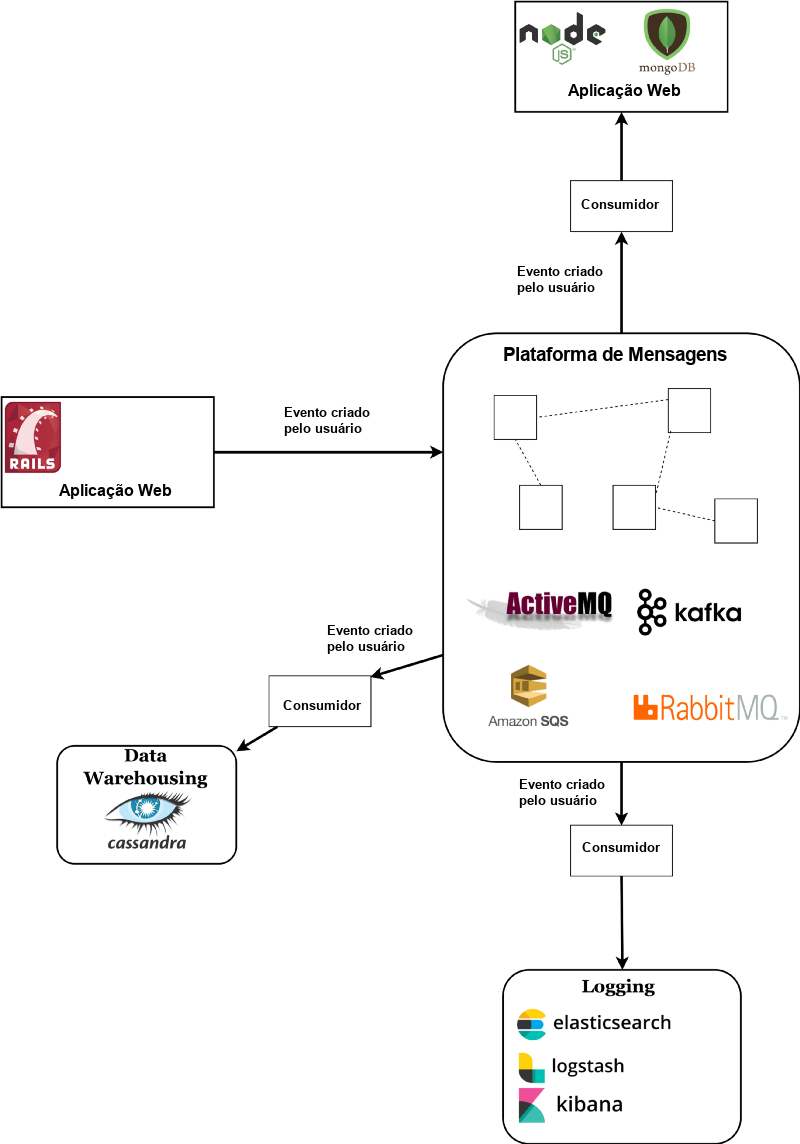
Uma mensagem é transmitida a partir da aplicação que a potencialmente cria (chamada de produtor), entra na plataforma e é lida por potencialmente múltiplas aplicações que têm interesse nela (chamadas de consumidores).
Se você precisa salvar um determinado evento em vários lugares (por exemplo, criação de usuário no banco de dados, data warehouse, serviço de envio de e-mails e qualquer outra coisa que você possa imaginar), uma plataforma de mensageria é a maneira mais limpa de disseminar essa mensagem.
Os consumidores podem tanto extrair informações dos brokers (modelo pull) quanto ter os brokers enviando informações diretamente para os consumidores (modelo push).
Existem algumas plataformas de mensagens populares e de alta qualidade:
RabbitMQ (texto em inglês) — broker de mensagens que permite um controle mais detalhado das trajetórias das mensagens através de regras de roteamento e outras configurações facilmente ajustáveis. Pode ser chamado de broker inteligente, pois possui muita lógica embutida e acompanha rigorosamente as mensagens que passam por ele. Oferece configurações tanto para AP quanto para CP do teorema CAP. Utiliza um modelo push para notificar os consumidores.
Kafka (texto em inglês) — broker de mensagens (e uma plataforma completa) que é um pouco mais de baixo nível, pois não acompanha quais mensagens foram lidas e não permite uma lógica de roteamento complexa. Isso ajuda a alcançar um desempenho incrível. Na minha opinião, esse é o maior prospecto nesse espaço, com desenvolvimento ativo da comunidade de código aberto e suporte da equipe Confluent (texto em inglês). O Kafka, indiscutivelmente, é o mais amplamente utilizado pelas principais empresas de tecnologia. Escrevi uma introdução detalhada sobre isso, onde explico em detalhes todas as suas vantagens (texto em inglês).
Apache ActiveMQ (texto em inglês) — o mais antigo do grupo, datando de 2004. Usa a API JMS, o que significa que é voltado para aplicativos Java EE. Foi reescrito como ActiveMQ Artemis (texto em inglês), que oferece um desempenho excepcional comparável ao Kafka.
Amazon SQS (texto em inglês) — um serviço de mensageria fornecido pela AWS. Permite que você integre rapidamente com aplicações existentes e elimina a necessidade de lidar com sua própria infraestrutura, o que pode ser um grande benefício, já que sistemas como o Kafka são notoriamente difíceis de configurar. A Amazon também oferece dois serviços semelhantes — SNS (texto em inglês) e MQ (texto em inglês), este último é basicamente o ActiveMQ, mas gerenciado pela Amazon.
Aplicações distribuídas
Se você agrupar 5 servidores de Rails atrás de um único balanceador de carga, todos conectados a um banco de dados, poderia chamar isso de aplicação distribuída? Lembre-se da minha definição lá em cima:
Um sistema distribuído é um grupo de computadores trabalhando juntos para parecer como se fosse um único computador para o usuário final. Essas máquinas têm um estado compartilhado, operam de maneira concorrente e podem falhar independentemente sem afetar o tempo de atividade do sistema como um todo.
Se você considerar o banco de dados como um estado compartilhado, poderia argumentar que isso pode ser classificado como um sistema distribuído — mas você estaria errado, pois você ignorou a parte "trabalhando juntos" da definição.
Um sistema é distribuído apenas se os nós se comunicarem entre si para coordenar suas ações.
Portanto, algo como uma aplicação que executa seu código de back-end em uma rede peer-to-peer (texto em inglês) pode ser melhor classificado como uma aplicação distribuída. Independentemente disso, toda essa classificação desnecessária não serve para nada além de ilustrar como somos detalhistas sobre agrupar coisas juntas.
Escala conhecida – Por exemplo, o enxame BitTorrent de 193.000 nós para um episódio de Game of Thrones, em abril de 2014.
Máquina virtual com Erlang
Erlang é uma linguagem funcional que possui ótimas semânticas para concorrência, distribuição e tolerância a falhas. A própria máquina virtual com Erlang lida com a distribuição de uma aplicação do Erlang.
Seu modelo funciona tendo muitos processos leves (texto em inglês) e isolados, todos com a capacidade de se comunicar entre si por meio de um sistema integrado de passagem de mensagens. Isso é chamado de Modelo de Ator (texto em inglês) e as bibliotecas Erlang OTP podem ser consideradas como um framework de atores distribuídos (similar ao Akka para a JVM).
O modelo é o que ajuda a alcançar uma ótima concorrência de maneira bastante simples — os processos são distribuídos pelos núcleos disponíveis do sistema que os executa. Uma vez que isso é indistinguível de um ambiente de rede (exceto pela capacidade de descartar mensagens), a máquina virtual do Erlang pode se conectar a outras máquinas virtuais do Erlang em execução no mesmo data center ou até mesmo em outro continente. Esse conjunto de máquinas virtuais executa uma única aplicação e lida com falhas de máquina por meio de takeover (outro nó é escalonado para executar).
De fato, a camada distribuída da linguagem foi adicionada para fornecer tolerância a falhas. Software em execução em uma única máquina está sempre em risco de ter essa única máquina falhando e tirando sua aplicação do ar. O software em execução em muitos nós permite um manuseio mais fácil de falhas de hardware, desde que a aplicação tenha sido construída com isso em mente.
BitTorrent
O BitTorrent é um dos protocolos mais amplamente utilizados para transferir arquivos grandes pela web por meio de torrents. A ideia principal é facilitar a transferência de arquivos entre diferentes pares na rede sem precisar passar por um servidor central.
Usando um client do BitTorrent, você se conecta a vários computadores ao redor do mundo para baixar um arquivo. Quando você abre um arquivo .torrent, você se conecta a um chamado tracker (rastreador), que é uma máquina que age como coordenador. Ele ajuda na descoberta de pares, mostrando os nós na rede que têm o arquivo que você deseja.
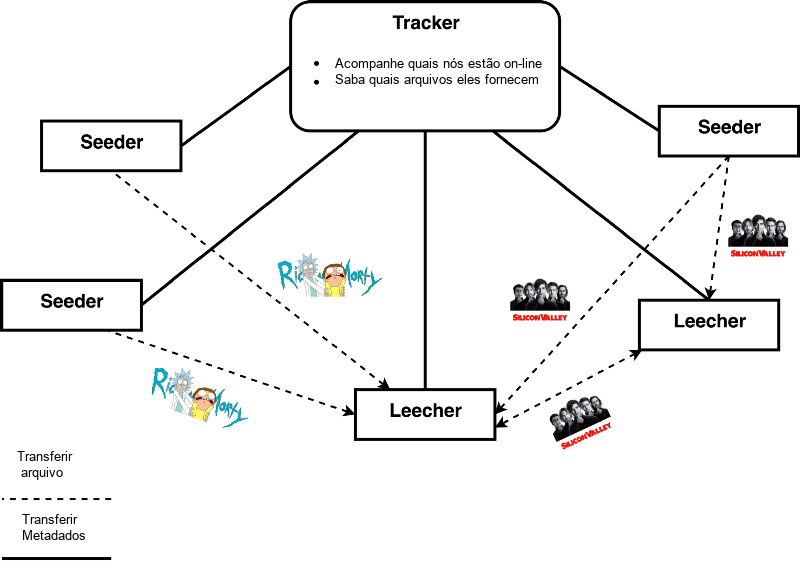
Você tem as noções de dois tipos de usuário, um leecher e um seeder. Um leecher é o usuário que está baixando um arquivo e um seeder é o usuário que está enviando esse arquivo.
O interessante sobre redes peer-to-peer é que você, como usuário comum, tem a capacidade de se juntar e contribuir para a rede.
O BitTorrent e seus precursores (Gnutella, Napster – textos em inglês) permitem que você hospede arquivos voluntariamente e os envie para outros usuários que os desejam. A razão pela qual o BitTorrent é tão popular é que ele foi o primeiro de seu tipo a fornecer incentivos para contribuir com a rede. O problema do Freeriding, onde um usuário apenas baixava arquivos sem contribuir com uploads, era um desafio para os protocolos de compartilhamento de arquivos anteriores.
O BitTorrent resolveu o freeriding até certo ponto, fazendo com que os seeders enviassem mais para aqueles que fornecem as melhores taxas de download. Ele funciona incentivando você a fazer upload enquanto baixa um arquivo. Infelizmente, depois que você termina, nada o obriga a permanecer ativo na rede. Isso causa uma falta de seeders na rede que têm o arquivo completo e, como o protocolo depende fortemente de tais usuários, soluções como rastreadores privados (texto em inglês) surgiram. Rastreadores privados exigem que você seja membro de uma comunidade (geralmente apenas por convite) para participar da rede distribuída.
Após avanços na área, torrents sem rastreadores foram inventados. Essa foi uma atualização para o protocolo BitTorrent que não dependia de rastreadores centralizados para reunir metadados e encontrar pares, mas usava novos algoritmos. Um exemplo disso é o Kademlia (Mainline DHT) (textos em inglês), uma tabela de hash distribuída (DHT) que permite encontrar pares através de outros pares. Na prática, cada usuário desempenha as funções de um rastreador.
Registros distribuídos
Um registro distribuído pode ser pensado como um banco de dados imutável, de apenas anexação, que é replicado, sincronizado e compartilhado entre todos os nós na rede distribuída.
Escala conhecida – a Rede Ethereum teve um pico de 1,3 milhão de transações por dia em 4 de janeiro de 2018
Eles aproveitam o padrão de Event Sourcing (texto em inglês), permitindo que você reconstrua o estado do registro em qualquer momento de sua história.
Blockchain
A tecnologia Blockchain é atualmente usada para os registros distribuídos e, na verdade, marcou seu início. Essa mais recente e revolucionária inovação no espaço distribuído possibilitou a criação do primeiro protocolo de pagamento verdadeiramente distribuído – o Bitcoin.
Blockchain é um registro distribuído que carrega uma lista ordenada de todas as transações que já ocorreram em sua rede. As transações são agrupadas e armazenadas em blocos. O blockchain inteiro é essencialmente uma lista encadeada (texto em inglês) de blocos (daí o nome). Esses blocos são computacionalmente caros de serem criados e estão intimamente ligados entre si por meio de criptografia.
Dito de maneira simples, cada bloco contém um hash especial (que começa com uma quantidade X de zeros) do conteúdo do bloco atual (na forma de uma Árvore de Merkle) mais o hash do bloco anterior. Esse hash requer muita potência de CPU para ser produzido porque a única maneira de obtê-lo é através de força bruta.
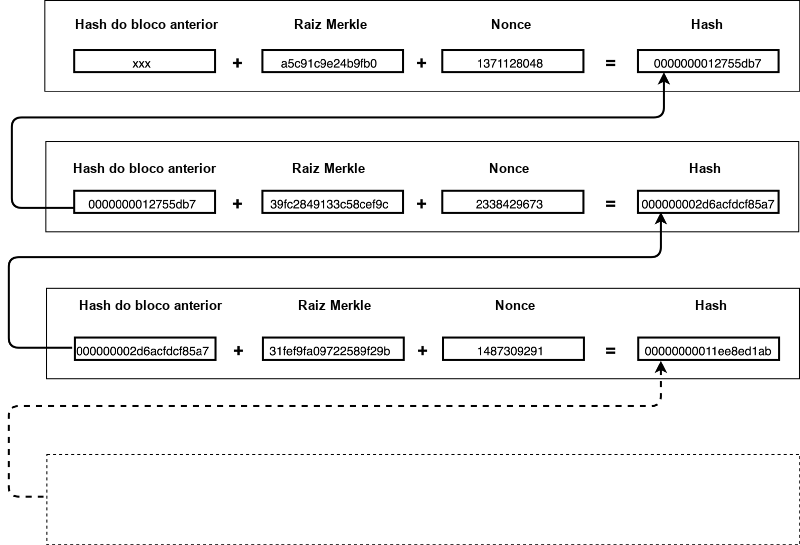
Os miners (mineradores) são os nós que tentam calcular o hash (via força bruta). Os miners competem entre si para ver quem consegue encontrar uma string aleatória (chamada de nonce) que, quando combinada com o conteúdo, produz o hash mencionado anteriormente. Uma vez que alguém encontre o nonce correto, ele o transmite para toda a rede. Essa string é então verificada por cada nó individualmente e aceita em sua cadeia.
Isso se traduz em um sistema onde é absurdamente caro modificar o blockchain e absurdamente fácil verificar se ele não foi adulterado.
É caro alterar o conteúdo de um bloco porque isso produziria um hash diferente. Lembre-se de que o hash de cada bloco subsequente depende dele. Se você mudasse uma transação no primeiro bloco da imagem acima, você mudaria a Raiz de Merkle. Isso, por sua vez, mudaria o hash do bloco (provavelmente sem os zeros iniciais necessários) — isso mudaria o hash do bloco nº 2 e assim por diante. Isso significa que você precisaria forçar um novo nonce para cada bloco após aquele que você acabou de modificar.
A rede sempre confia e replica a cadeia válida mais longa. Para trapacear o sistema e eventualmente produzir uma cadeia mais longa, você precisaria de mais de 50% do poder total de processamento da CPU usado por todos os nós.
O blockchain pode ser pensado como um mecanismo distribuído para o consenso emergente. O consenso não é alcançado explicitamente — não há eleição ou momento fixo em que o consenso ocorre. Em vez disso, o consenso é um produto emergente da interação assíncrona de milhares de nós independentes, todos seguindo regras de protocolo.
Essa inovação sem precedentes recentemente se tornou um boom no espaço tecnológico, com pessoas prevendo que marcará a criação da Web 3.0 (texto em inglês). É definitivamente o espaço mais emocionante no mundo da engenharia de software no momento, repleto de problemas extremamente desafiadores e interessantes esperando para serem resolvidos.
Bitcoin
O que os protocolos de pagamento distribuídos anteriores não tinham era uma maneira de prevenir de maneira prática o problema de gasto duplo (texto em inglês) em tempo real e de maneira distribuída. Pesquisas produziram propostas interessantes[1], mas o Bitcoin foi o primeiro a implementar uma solução prática com vantagens claras sobre os outros.
O problema de gasto duplo afirma que um ator (por exemplo, Bob) não pode gastar seu único recurso em dois lugares. Se Bob tem $1, ele não deveria poder entregá-lo tanto para Alice quanto para Zack — é apenas um recurso, não pode ser duplicado. Acontece que é realmente difícil alcançar verdadeiramente essa garantia em um sistema distribuído. Existem algumas abordagens de mitigação interessantes (texto em inglês) anteriores ao blockchain, mas elas não resolvem completamente o problema de maneira prática.
O problema de gasto duplo é facilmente resolvido pelo Bitcoin, pois apenas um bloco é adicionado à cadeia de cada vez. O gasto duplo é impossível dentro de um único bloco, portanto, mesmo que dois blocos sejam criados ao mesmo tempo — apenas um virá a fazer parte da cadeia mais longa eventualmente.

O Bitcoin depende da dificuldade de acumular poder de processamento da CPU.
Enquanto em um sistema de votação um atacante só precisa adicionar nós à rede (o que é fácil, já que o acesso gratuito à rede é uma meta de projeto), em um esquema baseado em poder de CPU, um atacante enfrenta uma limitação física: obter acesso a hardware cada vez mais poderoso.
Essa também é a razão pela qual grupos maliciosos de nós precisam controlar mais de 50% do poder computacional da rede para realmente realizar qualquer ataque bem-sucedido. Menos do que isso, e o restante da rede criará um blockchain mais longo mais rapidamente.
Ethereum
Ethereum pode ser considerado como uma plataforma de software baseada em blockchain programável. Ele tem sua própria criptomoeda (Ether), que alimenta a implementação de contratos inteligentes em seu blockchain.
Contratos inteligentes são um pedaço de código armazenado como uma única transação no blockchain do Ethereum. Para executar o código, tudo o que você precisa fazer é emitir uma transação com um contrato inteligente como seu destino. Isso, por sua vez, faz com que os nós mineradores executem o código e quaisquer mudanças que ele incorra. O código é executado dentro da Máquina Virtual Ethereum.
Solidity, a linguagem de programação nativa do Ethereum, é o que é usado para escrever contratos inteligentes. É uma linguagem de programação completa de Turing que interage diretamente com o blockchain do Ethereum, permitindo que você consulte o estado, como saldos ou outros resultados de contratos inteligentes. Para evitar loops infinitos, executar o código requer uma certa quantidade de Ether.
Como o blockchain pode ser interpretado como uma série de mudanças de estado, muitas aplicações distribuídas (DApps; texto em inglês) foram construídas em cima do Ethereum e plataformas similares.
Outros usos de registros distribuídos
Prova de Existência (texto em inglês) — um serviço para armazenar de maneira anônima e segura a prova de que um determinado documento digital existia em algum momento no tempo. Útil para garantir a integridade do documento, propriedade e registro de data e hora.
Organizações autônomas descentralizadas (DAO; texto em inglês) — organizações que utilizam blockchain como meio de alcançar consenso sobre as proposições de melhoria da organização. Exemplos são o sistema de governança da Dash e o projeto SmartCash (textos em inglês).
Autenticação descentralizada — armazene sua identidade no blockchain, permitindo que você use logins únicos em todos os lugares (single sign-on; SSO). Exemplos são Sovrin e Civic (textos em inglês).
Há muitos, muitos outros. A tecnologia de registro distribuído realmente abriu possibilidades infinitas. Alguns, provavelmente, estão sendo inventados enquanto falamos!
Resumo
No curto espaço deste artigo, conseguimos definir o que é um sistema distribuído, por que você usaria um e passamos brevemente por cada categoria. Algumas coisas importantes para lembrar são:
- Sistemas distribuídos são complexos
- São escolhidos pela necessidade de escala e preço
- São mais difíceis de trabalhar
- Teorema CAP — escolha entre Consistência e Disponibilidade
- Eles têm 6 categorias — armazenamento de dados, computação, sistemas de arquivos, sistemas de mensagens, registros, aplicações
Para ser sincero, mal arranhamos a superfície dos sistemas distribuídos. Não tive a chance de abordar minuciosamente e explicar problemas fundamentais como consenso, estratégias de replicação, ordenação de eventos e tempo, tolerância a falhas, transmissão de mensagens pela rede e outros (textos em inglês).
Atenção
Deixe-me compartilhar com você um aviso final:
Você deve evitar os sistemas distribuídos o máximo possível. A sobrecarga de complexidade que eles trazem consigo não vale o esforço se você puder evitar o problema resolvendo-o de uma maneira diferente ou por meio de alguma outra solução criativa.
[1]
Combate ao duplo gasto usando sistemas P2P cooperativos (texto em inglês), 25 a 27 de junho de 2007 — uma solução proposta na qual cada 'moeda' pode expirar e é atribuído um testemunho (validador) a ela ao ser gasta.
Bitgold (texto em inglês), dezembro de 2005 — uma visão geral de alto nível de um protocolo extremamente semelhante ao do Bitcoin. Diz-se que ele é o precursor do Bitcoin.
Leituras adicionais sobre sistemas distribuídos:
Designing Data-Intensive Applications, Martin Kleppmann — um ótimo livro que aborda tudo sobre sistemas distribuídos e muito mais (em inglês).
Especialização em computação em nuvem, Universidade de Illinois, Coursera — uma série de cursos (6) que aborda conceitos de sistemas distribuídos e suas aplicações.
Jepsen — blog que explica muitas tecnologias distribuídas (ElasticSearch, Redis, MongoDB etc).
Obrigado por dedicar seu tempo para ler este longo artigo (mais de 6.700 palavras)!
Se, por acaso, você achou este artigo informativo ou considerou que ele proporcionou valor a você, por favor, considere compartilhá-lo com um amigo que possa se beneficiar de uma introdução a esse maravilhoso campo de estudo.
Sobre Stanislav Kozlovski
O autor, atualmente, trabalha na Confluent. Confluent é uma empresa de Big Data fundada pelos próprios criadores do Apache Kafka! Ele se diz imensamente grato pela oportunidade que lhe deram – atualmente, ele trabalha no próprio Kafka, o que considera incrível! Na Confluent, eles ajudam a moldar todo o ecossistema Kafka de código aberto, incluindo uma nova oferta gerenciada de nuvem Kafka como serviço.
A Confluent contrata para vários cargos (especialmente SRE/Engenheiros de Software) na Europa e nos EUA! Se você estiver interessado em trabalhar no próprio Kafka, em busca de novas oportunidades ou simplesmente curioso – envie para o autor uma mensagem no Twitter e ele se oferece a compartilhar todas as grandes vantagens de se trabalhar por lá.